
The evolution of expertise in speech recognition has been marked by important strides, however challenges like latency the time delay in processing spoken language, have frequently impeded progress. This latency is particularly pronounced in autoregressive fashions, which course of speech sequentially, resulting in delays. These delays are detrimental in real-time functions like reside captioning or digital assistants, the place immediacy is vital. Addressing this latency with out compromising accuracy stays essential in advancing speech recognition expertise.
A pioneering strategy in speech recognition is growing a non-autoregressive mannequin, a departure from conventional strategies. This mannequin, proposed by a workforce of researchers from Google Analysis, is designed to deal with the inherent latency points present in current methods. It makes use of massive language fashions and leverages parallel processing, which processes speech segments concurrently slightly than sequentially. This related processing strategy is instrumental in lowering latency, providing a extra fluid and responsive consumer expertise.
The core of this revolutionary mannequin is the fusion of the Common Speech Mannequin (USM) with the PaLM 2 language mannequin. The USM, a strong mannequin with 2 billion parameters, is designed for correct speech recognition. It makes use of a vocabulary of 16,384-word items and employs a Connectionist Temporal Classification (CTC) decoder for parallel processing. The USM is educated on an intensive dataset, encompassing over 12 million hours of unlabeled audio and 28 billion sentences of textual content knowledge, making it extremely adept at dealing with multilingual inputs.
The PaLM 2 language mannequin, recognized for its prowess in pure language processing, enhances the USM. It’s educated on numerous knowledge sources, together with net paperwork and books, and employs a big 256,000 wordpiece vocabulary. The mannequin stands out for its capacity to attain Automated Speech Recognition (ASR) hypotheses utilizing a prefix language mannequin scoring mode. This methodology entails prompting the mannequin with a hard and fast prefix—high hypotheses from earlier segments—and scoring a number of suffix hypotheses for the present section.
In observe, the mixed system processes long-form audio in 8-second chunks. As quickly because the audio is on the market, the USM encodes it, and these segments are then relayed to the CTC decoder. The decoder types a confusion community lattice encoding attainable phrase items, which the PaLM 2 mannequin scores. The system updates each 8 seconds, offering a close to real-time response.
The efficiency of this mannequin was rigorously evaluated throughout a number of languages and datasets, together with YouTube captioning and the FLEURS check set. The outcomes have been exceptional. A median enchancment of 10.8% in relative phrase error charge (WER) was noticed on the multilingual FLEURS check set. For the YouTube captioning dataset, which presents a tougher state of affairs, the mannequin achieved a median enchancment of three.6% throughout all languages. These enhancements are a testomony to the mannequin’s effectiveness in numerous languages and settings.
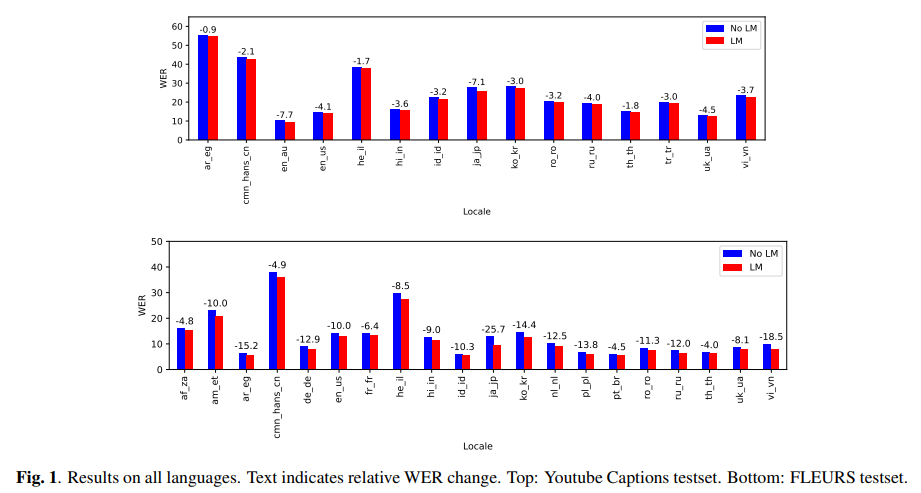
The research delved into numerous elements affecting the mannequin’s efficiency. It explored the influence of language mannequin dimension, starting from 128 million to 340 billion parameters. It discovered that whereas bigger fashions diminished sensitivity to fusion weight, the beneficial properties in WER may not offset the rising inference prices. The optimum LLM scoring weight additionally shifted with mannequin dimension, suggesting a steadiness between mannequin complexity and computational effectivity.
In conclusion, this analysis presents a big leap in speech recognition expertise. Its highlights embrace:
- A non-autoregressive mannequin combining the USM and PaLM 2 for diminished latency.
- Enhanced accuracy and velocity, making it appropriate for real-time functions.
- Important enhancements in WER throughout a number of languages and datasets.
This mannequin’s revolutionary strategy to processing speech in parallel, coupled with its capacity to deal with multilingual inputs effectively, makes it a promising answer for numerous real-world functions. The insights offered into system parameters and their results on ASR efficacy add priceless information to the sector, paving the way in which for future developments in speech recognition expertise.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Neglect to affix our Telegram Channel
Good day, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m enthusiastic about expertise and need to create new merchandise that make a distinction.