
In AI, synthesizing linguistic and visible inputs marks a burgeoning space of exploration. With the appearance of multimodal fashions, the ambition to interact the textual with the visible opens up unprecedented avenues for machine comprehension. These superior fashions transcend the normal scope of enormous language fashions (LLMs), aiming to understand and make the most of each types of information to deal with many duties. Potential purposes are producing detailed picture captions and offering correct responses to visible queries.
Regardless of exceptional strides within the subject, precisely deciphering photos paired with textual content stays a substantial problem. Current fashions typically need assistance with the complexity of real-world visuals, particularly these containing textual content. This can be a important hurdle, as understanding photos with embedded textual info is essential for fashions to reflect human-like notion and interplay with their atmosphere really.
The panorama of present methodologies consists of Imaginative and prescient Language Fashions (VLMs) and Multimodal Giant Language Fashions (MLLMs). These methods have been designed to bridge the hole between visible and textual information, integrating them right into a cohesive understanding. Nonetheless, they regularly want to completely seize the intricacies and nuanced particulars current in visible content material, significantly when it includes deciphering and contextualizing embedded textual content.
SuperAGI researchers have developed Veagle, a novel mannequin for addressing limitations in present VLMs and MLLMs. This revolutionary mannequin has the potential to dynamically combine visible info into language fashions. Veagle emerges from a synthesis of insights from prior analysis, making use of a classy mechanism to undertaking encoded visible information immediately into the linguistic evaluation framework. This permits for a deeper, extra nuanced comprehension of visible contexts, considerably enhancing the mannequin’s capability to interpret and relate textual and visible info.
Veagle’s methodology is exclusive for its structured coaching routine, which encompasses the utilization of a pre-trained imaginative and prescient encoder alongside a language mannequin. This strategic strategy includes two coaching phases, meticulously designed to refine and improve the mannequin’s capabilities. At first, Veagle focuses on assimilating the elemental connections between visible and textual information, establishing a stable basis. The mannequin undergoes additional refinement, honing its capability to interpret advanced visible scenes and the embedded textual content, thereby facilitating a complete understanding of the interaction between the 2 modalities.

The analysis of Veagle’s efficiency reveals its superior capabilities in a collection of benchmark assessments, significantly in visible query answering and picture comprehension duties. The mannequin demonstrates a major enchancment, attaining a 5-6% enhancement in efficiency over current fashions, and establishes new requirements for accuracy and effectivity in multimodal AI analysis. These outcomes not solely underscore the effectiveness of Veagle in navigating the challenges of integrating visible and textual info but in addition spotlight its versatility and potential applicability throughout a variety of eventualities past the confines of established benchmarks.
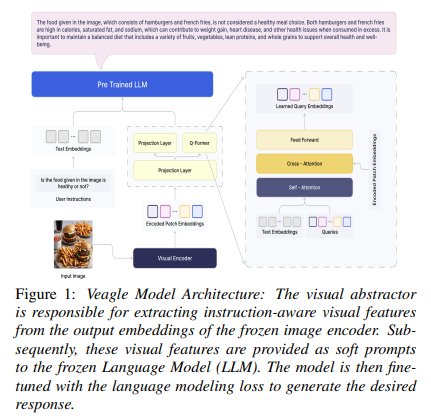
In conclusion, Veagle represents a paradigm shift in multimodal illustration studying, providing a extra subtle and efficient technique of integrating language and imaginative and prescient. Veagle paves the best way for fascinating analysis in VLMs and MLLMs by overcoming the prevalent limitations of present fashions. This development alerts a transfer in the direction of fashions that may extra precisely mirror human cognitive processes, deciphering and interacting with the atmosphere in a way that was beforehand unattainable.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our 38k+ ML SubReddit
Wish to get in entrance of 1.5 Million AI lovers? Work with us right here
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.