
Introduction
The panorama of synthetic intelligence has been dramatically reshaped over the previous few years by the appearance of Giant Language Fashions (LLMs). These highly effective instruments have developed from easy textual content processors to advanced methods able to understanding and producing human-like textual content, making important strides in each capabilities and purposes. On the forefront of this evolution is Meta’s newest providing, Llama 3, which guarantees to push the boundaries of what open fashions can obtain when it comes to accessibility and efficiency.
Key Options of Llama 3
- Llama 3 maintains a decoder-only transformer structure with important enhancements, together with a tokenizer supporting 128,000 tokens, enhancing language encoding effectivity.
- Built-in throughout each 8 billion and 70 billion parameter fashions, enhancing inference effectivity for targeted and efficient processing.
- Llama 3 outperforms its predecessors and opponents throughout numerous benchmarks, excelling in duties comparable to MMLU and HumanEval.
- Educated on over 15 trillion tokens dataset, seven instances bigger than Llama 2‘s dataset, incorporating numerous linguistic illustration and non-English knowledge from over 30 languages.
- Detailed scaling legal guidelines optimize knowledge combine and computational assets, guaranteeing strong efficiency throughout numerous purposes whereas tripling the coaching course of’s effectivity in comparison with Llama 2.
- An enhanced post-training section combines supervised fine-tuning, rejection sampling, and coverage optimization to enhance mannequin high quality and decision-making capabilities.
- Out there throughout main platforms, it options enhanced tokenizer effectivity and security options, empowering builders to tailor purposes and guarantee accountable AI deployment.
Discuss of the AI City
Clement Delangue, Co-founder & CEO at HuggingFace
Yann LeCun, Professor at NYU | Chief AI Scientist at Meta | Researcher in AI, Machine Studying, Robotics, and many others. | ACM Turing Award Laureate.
Andrej Karpathy, Founding Staff at OpenAI
Meta Llama 3 represents the most recent development in Meta’s sequence of language fashions, marking a major step ahead within the evolution of generative AI. Out there now, this new technology consists of fashions with 8 billion and 70 billion parameters, every designed to excel throughout a various vary of purposes. From partaking in on a regular basis conversations to tackling advanced reasoning duties, Llama 3 units a brand new customary in efficiency, outshining its predecessors on quite a few business benchmarks. Llama 3 is freely accessible, empowering the group to drive innovation in AI, from creating purposes to enhancing developer instruments and past.
Mannequin Structure and Enhancements from Llama 2
Llama 3 maintains the confirmed decoder-only transformer structure whereas incorporating important enhancements that elevate its performance past that of Llama 2. Adhering to a coherent design philosophy, Llama 3 features a tokenizer that helps an intensive vocabulary of 128,000 tokens, vastly enhancing the mannequin’s effectivity in encoding language. This growth interprets into markedly improved general efficiency. Furthermore, to spice up inference effectivity, Llama 3 integrates Grouped Question Consideration (GQA) throughout each its 8 billion and 70 billion parameter fashions. This mannequin additionally employs sequences of 8,192 tokens with a masking method that stops self-attention from extending throughout doc boundaries, guaranteeing extra targeted and efficient processing. These enhancements collectively improve Llama 3’s functionality to deal with a broader array of duties with elevated accuracy and effectivity.
| Characteristic | Llama 2 | Llama 3 |
| Parameter Vary | 7B to 70B parameters | 8B and 70B parameters, with plans for 400B+ |
| Mannequin Structure | Based mostly on the transformer structure | Commonplace decoder-only transformer structure |
| Tokenization Effectivity | Context size as much as 4096 tokens | Makes use of a tokenizer with a vocabulary of 128K tokens |
| Coaching Information | 2 trillion tokens from publicly obtainable sources | Over 15T tokens from publicly obtainable sources |
| Inference Effectivity | Enhancements like GQA for the 70B mannequin | Grouped Question Consideration (GQA) for improved effectivity |
| Wonderful-tuning Strategies | Supervised fine-tuning and RLHF | Supervised fine-tuning (SFT), rejection sampling, PPO, DPO |
| Security and Moral Issues | Protected in accordance with adversarial immediate testing | In depth red-teaming for security |
| Open Supply and Accessibility | Group license with sure restrictions | Goals for an open strategy to foster an AI ecosystem |
| Use Instances | Optimized for chat and code technology | Broad use throughout a number of domains with a deal with instruction-following |
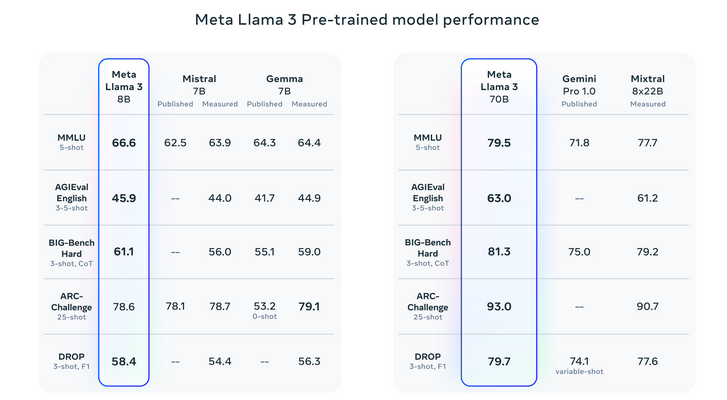
Benchmarking Outcomes In comparison with Different Fashions
Llama 3 has raised the bar in generative AI, surpassing its predecessors and opponents throughout a wide range of benchmarks. It has excelled significantly in assessments comparable to MMLU, which evaluates data in numerous areas, and HumanEval, targeted on coding abilities. Furthermore, Llama 3 has outperformed different high-parameter fashions like Google’s Gemini 1.5 Professional and Anthropic’s Claude 3 Sonnet, particularly in advanced reasoning and comprehension duties.
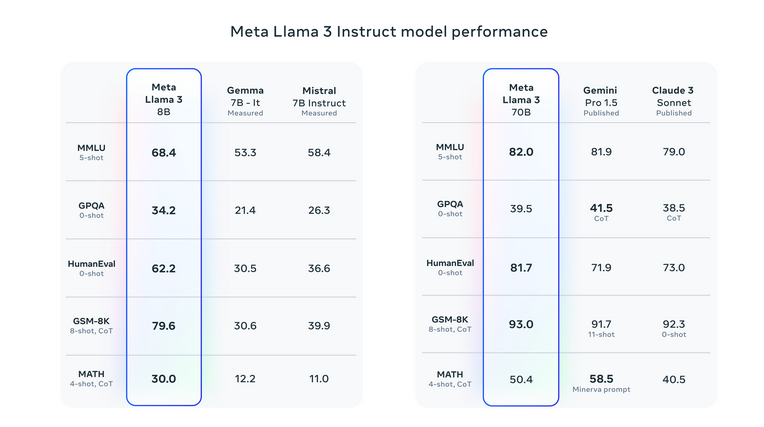
Please see analysis particulars for setting and parameters with which these evaluations are calculated.
Analysis on Commonplace and Customized Check Units
Meta has created distinctive analysis units past conventional benchmarks to check Llama 3 throughout numerous real-world purposes. This tailor-made analysis framework consists of 1,800 prompts protecting 12 vital use instances: giving recommendation, brainstorming, classifying, answering each closed and open questions, coding, inventive composition, knowledge extraction, role-playing, logical reasoning, textual content rewriting, and summarizing. Limiting entry to this particular set, even for Meta’s modeling groups, safeguards towards potential overfitting of the mannequin. This rigorous testing strategy has confirmed Llama 3’s superior efficiency, regularly outshining different fashions. Thus underscoring its adaptability and proficiency.
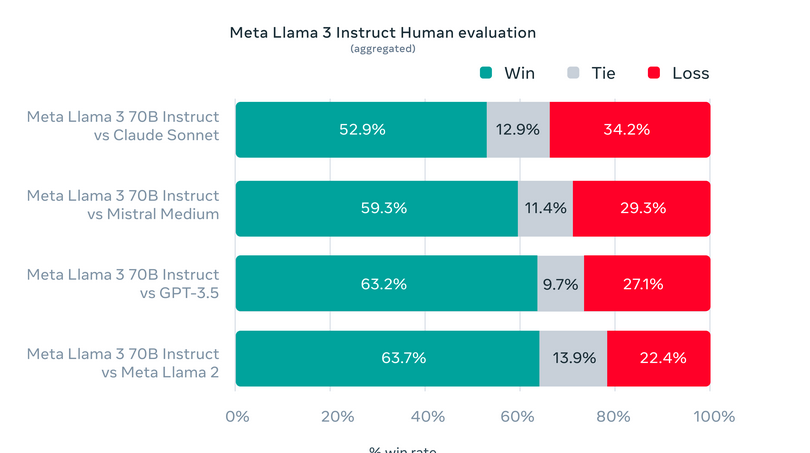
Please see analysis particulars for setting and parameters with which these evaluations are calculated.
Coaching Information and Scaling Methods
Allow us to now discover coaching knowledge and scaling methods:
Coaching Information
- Llama 3’s coaching dataset, over 15 trillion tokens, is a seven-fold enhance from Llama 2.
- The dataset encompasses 4 instances extra code and over 5% of high-quality non-English knowledge from 30 languages. Guaranteeing numerous linguistic illustration for multilingual purposes.
- To keep up knowledge high quality, Meta employs refined data-filtering pipelines, together with heuristic filters, NSFW filters, semantic deduplication, and textual content classifiers.
- Leveraging insights from earlier Llama fashions, these methods improve the coaching of Llama 3 by figuring out and incorporating high quality knowledge.
Scaling Methods
- Meta targeted on maximizing the utility of Llama 3’s dataset by creating detailed scaling legal guidelines.
- Optimization of knowledge combine and computational assets facilitated correct predictions of mannequin efficiency throughout numerous duties.
- Strategic foresight ensures strong efficiency throughout numerous purposes like trivia, STEM, coding, and historic data.
- Insights revealed the Chinchilla-optimal quantity of coaching compute for the 8B parameter mannequin, round 200 billion tokens.
- Each the 8B and 70B fashions proceed to enhance efficiency log-linearly with as much as 15 trillion tokens.
- Meta achieved over 400 TFLOPS per GPU utilizing 16,000 GPUs concurrently throughout custom-built 24,000 GPU clusters.
- Improvements in coaching infrastructure embody automated error detection, system upkeep, and scalable storage options.
- These developments tripled Llama 3’s coaching effectivity in comparison with Llama 2, attaining an efficient coaching time of over 95%.
- These enhancements set new requirements for coaching massive language fashions, pushing ahead the boundaries of AI.
Instruction of Wonderful-Tuning
- Instruction-tuning enhances performance of pretrained chat fashions.
- Course of combines supervised fine-tuning, rejection sampling, PPO, and DPO.
- Prompts in SFT and desire rankings in PPO/DPO essential for mannequin efficiency.
- Meticulous knowledge curation and high quality assurance by human annotators.
- Choice rankings in PPO/DPO enhance reasoning and coding process efficiency.
- Fashions able to producing right solutions however might wrestle with choice.
- Coaching with desire rankings enhances decision-making in advanced duties.
Deployment of Llama3
Llama 3 is ready for widespread availability throughout main platforms, together with cloud providers and mannequin API suppliers. It options enhanced tokenizer effectivity, decreasing token use by as much as 15% in comparison with Llama 2, and incorporates Group Question Consideration (GQA) within the 8B mannequin to take care of inference effectivity, even with a further 1 billion parameters over Llama 2 7B. The open-source ‘Llama Recipes’ affords complete assets for sensible deployment and optimization methods, supporting Llama 3’s versatile utility.
Enhancements and Security Options in Llama 3
Llama 3 is designed to empower builders with instruments and suppleness to tailor purposes in accordance with particular wants. It improve the open AI ecosystem. This model introduces new security and belief instruments includingLlama Guard 2, Cybersec Eval 2, and Code Defend, which assist filter insecure code throughout inference. Llama 3 has been developed in partnership with torchtune, a PyTorch-native library that permits environment friendly, memory-friendly authoring, fine-tuning, and testing of LLMs. This library helps integration with platforms like Hugging Face and Weights & Biases. It additionally facilitates environment friendly inference on numerous units by Executorch.
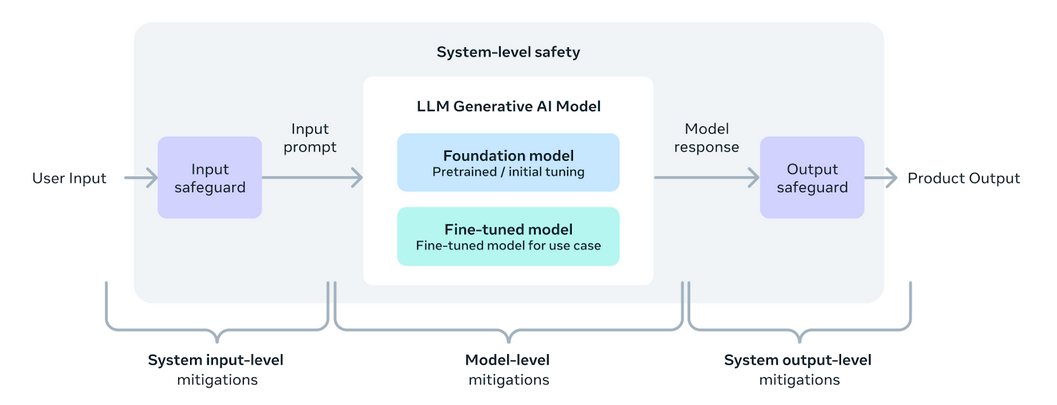
A systemic strategy to accountable deployment ensures that Llama 3 fashions aren’t solely helpful but in addition protected. Instruction fine-tuning is a key part, considerably enhanced by red-teaming efforts that take a look at for security and robustness towards potential misuse in areas comparable to cyber safety. The introduction of Llama Guard 2 incorporates the MLCommons taxonomy to assist setting business requirements, whereas CyberSecEval 2 improves safety measures towards code misuse.
The adoption of an open strategy in creating Llama 3 goals to unite the AI group and tackle potential dangers successfully. Meta’s up to date Accountable Use Information (RUG) outlines greatest practices for guaranteeing that each one mannequin inputs and outputs adhere to security requirements, complemented by content material moderation instruments supplied by cloud suppliers. These collective efforts are directed in the direction of fostering a protected, accountable, and revolutionary use of LLMs in numerous purposes.
Future Developments for Llama 3
The preliminary launch of the Llama 3 fashions, together with the 8B and 70B variations. It’s simply the beginning of the deliberate developments for this sequence. Meta is at the moment coaching even bigger fashions with over 400 billion parameters. These fashions will promise enhanced capabilities, comparable to multimodality, multilingual communication, prolonged context home windows, and general stronger efficiency. Within the coming months, these superior fashions can be launched. Accompanied by an in depth analysis paper outlining the findings from the coaching of Llama 3. Meta has shared early snapshots from ongoing coaching of their largest LLM mannequin, providing insights into future releases.
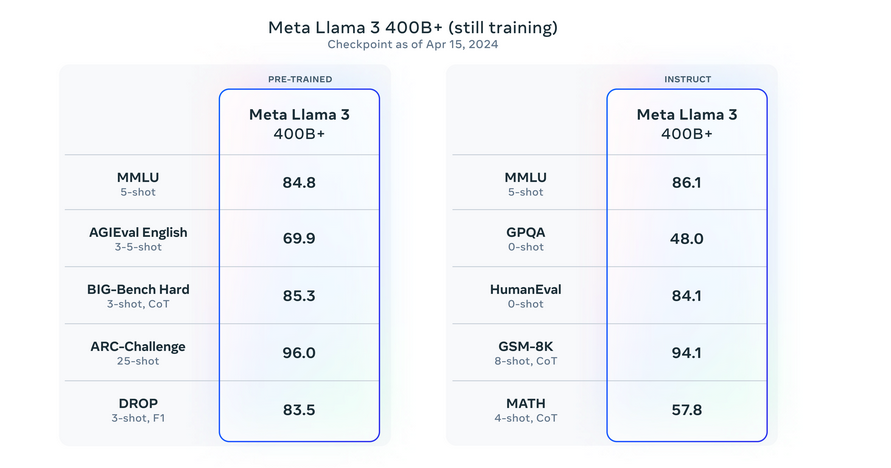
Please see analysis particulars for setting and parameters with which these evaluations are calculated.
Influence and Endorsement of Llama 3
- Llama 3 rapidly grew to become the quickest mannequin to succeed in the #1 trending spot on Hugging Face. Reaching this file inside only a few hours of its launch.
Click on right here to entry the hyperlink.
- Following the event of 30,000 fashions from Llama 1 and a pair of, Llama 3 is poised to considerably influence the AI ecosystem.
- Main AI and cloud platforms like AWS, Microsoft Azure, Google Cloud, and Hugging Face promptly included Llama 3.
- The mannequin’s presence on Kaggle widens its accessibility, encouraging extra hands-on exploration and growth inside the knowledge science group.
- Out there on LlamaIndex, this useful resource compiled by specialists like @ravithejads and @LoganMarkewich supplies detailed steerage on using Llama 3 throughout a spread of purposes, from easy duties to advanced RAG pipelines. Click on right here to entry hyperlink.
Conclusion
Llama 3 units a brand new customary within the evolution of Giant Language Fashions. They’re enhancing AI capabilities throughout a spread of duties with its superior structure and effectivity. Its complete testing demonstrates superior efficiency, outshining each predecessors and modern fashions. With strong coaching methods and revolutionary security measures like Llama Guard 2 and Cybersec Eval 2. Llama 3 underscores Meta’s dedication to accountable AI growth. As Llama 3 turns into broadly obtainable, it guarantees to drive important developments in AI purposes. Additionally providing builders a strong software to discover and develop technological frontiers.