
As organizations throughout sectors grapple with the alternatives and challenges offered through the use of massive language fashions (LLMs), the infrastructure wanted to construct, practice, check, and deploy LLMs presents its personal distinctive challenges. As a part of the SEI’s current investigation into use circumstances for LLMs inside the Intelligence Group (IC), we wanted to deploy compliant, cost-effective infrastructure for analysis and improvement. On this publish, we describe present challenges and cutting-edge of cost-effective AI infrastructure, and we share 5 classes realized from our personal experiences standing up an LLM for a specialised use case.
The Problem of Architecting MLOps Pipelines
Architecting machine studying operations (MLOps) pipelines is a troublesome course of with many shifting elements, together with information units, workspace, logging, compute assets, and networking—and all these elements should be thought-about throughout the design part. Compliant, on-premises infrastructure requires superior planning, which is usually a luxurious in quickly advancing disciplines resembling AI. By splitting duties between an infrastructure crew and a improvement crew who work intently collectively, mission necessities for undertaking ML coaching and deploying the assets to make the ML system succeed could be addressed in parallel. Splitting the duties additionally encourages collaboration for the mission and reduces mission pressure like time constraints.
Approaches to Scaling an Infrastructure
The present cutting-edge is a multi-user, horizontally scalable atmosphere positioned on a company’s premises or in a cloud ecosystem. Experiments are containerized or saved in a approach so they’re straightforward to copy or migrate throughout environments. Information is saved in particular person elements and migrated or built-in when needed. As ML fashions change into extra advanced and because the quantity of information they use grows, AI groups may have to extend their infrastructure’s capabilities to keep up efficiency and reliability. Particular approaches to scaling can dramatically have an effect on infrastructure prices.
When deciding how you can scale an atmosphere, an engineer should take into account elements of price, pace of a given spine, whether or not a given mission can leverage sure deployment schemes, and general integration aims. Horizontal scaling is the usage of a number of machines in tandem to distribute workloads throughout all infrastructure accessible. Vertical scaling offers further storage, reminiscence, graphics processing items (GPUs), and so on. to enhance system productiveness whereas decreasing price. Any such scaling has particular software to environments which have already scaled horizontally or see a scarcity of workload quantity however require higher efficiency.
Typically, each vertical and horizontal scaling could be price efficient, with a horizontally scaled system having a extra granular degree of management. In both case it’s potential—and extremely really useful—to determine a set off operate for activation and deactivation of pricey computing assets and implement a system beneath that operate to create and destroy computing assets as wanted to attenuate the general time of operation. This technique helps to cut back prices by avoiding overburn and idle assets, which you might be in any other case nonetheless paying for, or allocating these assets to different jobs. Adapting sturdy orchestration and horizontal scaling mechanisms resembling containers, offers granular management, which permits for clear useful resource utilization whereas decreasing working prices, notably in a cloud atmosphere.
Classes Discovered from Venture Mayflower
From Could-September 2023, the SEI carried out the Mayflower Venture to discover how the Intelligence Group may arrange an LLM, customise LLMs for particular use circumstances, and consider the trustworthiness of LLMs throughout use circumstances. You may learn extra about Mayflower in our report, A Retrospective in Engineering Massive Language Fashions for Nationwide Safety. Our crew discovered that the power to quickly deploy compute environments primarily based on the mission wants, information safety, and making certain system availability contributed on to the success of our mission. We share the next classes realized to assist others construct AI infrastructures that meet their wants for price, pace, and high quality.
1. Account on your belongings and estimate your wants up entrance.
Contemplate each bit of the atmosphere an asset: information, compute assets for coaching, and analysis instruments are just some examples of the belongings that require consideration when planning. When these elements are recognized and correctly orchestrated, they will work collectively effectively as a system to ship outcomes and capabilities to finish customers. Figuring out your belongings begins with evaluating the info and framework the groups can be working with. The method of figuring out every element of your atmosphere requires experience from—and ideally, cross coaching and collaboration between—each ML engineers and infrastructure engineers to perform effectively.
{kind=link}

2. Construct in time for evaluating toolkits.
Some toolkits will work higher than others, and evaluating them generally is a prolonged course of that must be accounted for early on. In case your group has change into used to instruments developed internally, then exterior instruments could not align with what your crew members are conversant in. Platform as a service (PaaS) suppliers for ML improvement provide a viable path to get began, however they might not combine nicely with instruments your group has developed in-house. Throughout planning, account for the time to judge or adapt both instrument set, and evaluate these instruments towards each other when deciding which platform to leverage. Price and value are the first elements you need to take into account on this comparability; the significance of those elements will fluctuate relying in your group’s assets and priorities.
3. Design for flexibility.
Implement segmented storage assets for flexibility when attaching storage elements to a compute useful resource. Design your pipeline such that your information, outcomes, and fashions could be handed from one place to a different simply. This strategy permits assets to be positioned on a typical spine, making certain quick switch and the power to connect and detach or mount modularly. A standard spine offers a spot to retailer and name on massive information units and outcomes of experiments whereas sustaining good information hygiene.
A apply that may assist flexibility is offering a normal “springboard” for experiments: versatile items of {hardware} which might be independently highly effective sufficient to run experiments. The springboard is much like a sandbox and helps speedy prototyping, and you may reconfigure the {hardware} for every experiment.
For the Mayflower Venture, we carried out separate container workflows in remoted improvement environments and built-in these utilizing compose scripts. This technique permits a number of GPUs to be referred to as throughout the run of a job primarily based on accessible marketed assets of joined machines. The cluster offers multi-node coaching capabilities inside a job submission format for higher end-user productiveness.
4. Isolate your information and defend your gold requirements.
Correctly isolating information can clear up a wide range of issues. When working collaboratively, it’s straightforward to exhaust storage with redundant information units. By speaking clearly along with your crew and defining a normal, widespread, information set supply, you may keep away from this pitfall. Which means a major information set should be extremely accessible and provisioned with the extent of use—that’s, the quantity of information and the pace and frequency at which crew members want entry—your crew expects on the time the system is designed. The supply ought to be capable to assist the anticipated reads from nevertheless many crew members may have to make use of this information at any given time to carry out their duties. Any output or remodeled information should not be injected again into the identical space wherein the supply information is saved however ought to as a substitute be moved into one other working listing or designated output location. This strategy maintains the integrity of a supply information set whereas minimizing pointless storage use and permits replication of an atmosphere extra simply than if the info set and dealing atmosphere weren’t remoted.
5. Save prices when working with cloud assets.
Authorities cloud assets have completely different availability than industrial assets, which regularly require further compensations or compromises. Utilizing an current on-premises useful resource might help cut back prices of cloud operations. Particularly, think about using native assets in preparation for scaling up as a springboard. This apply limits general compute time on costly assets that, primarily based in your use case, could also be much more highly effective than required to carry out preliminary testing and analysis.
{kind=link}
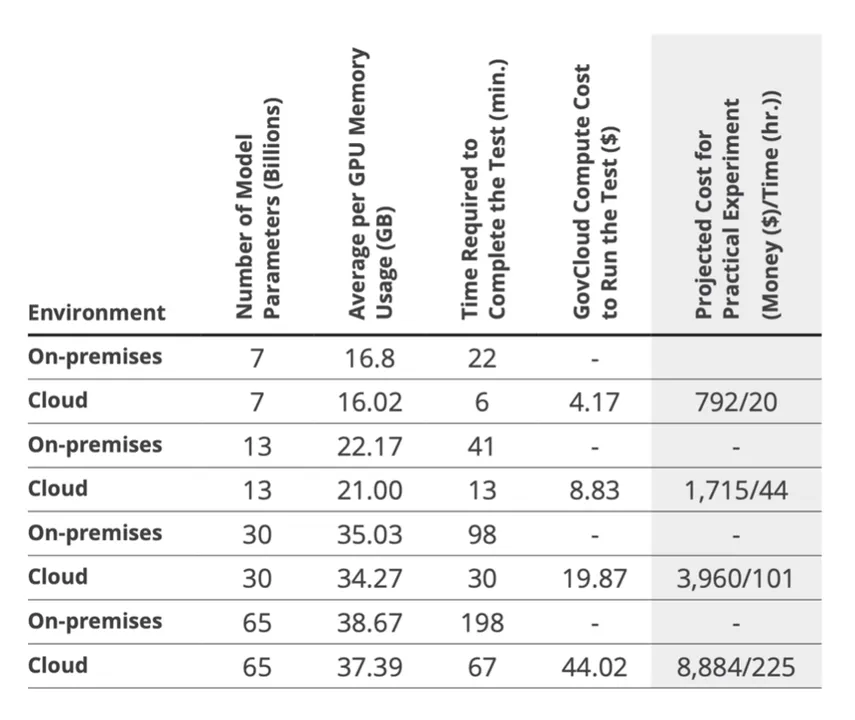
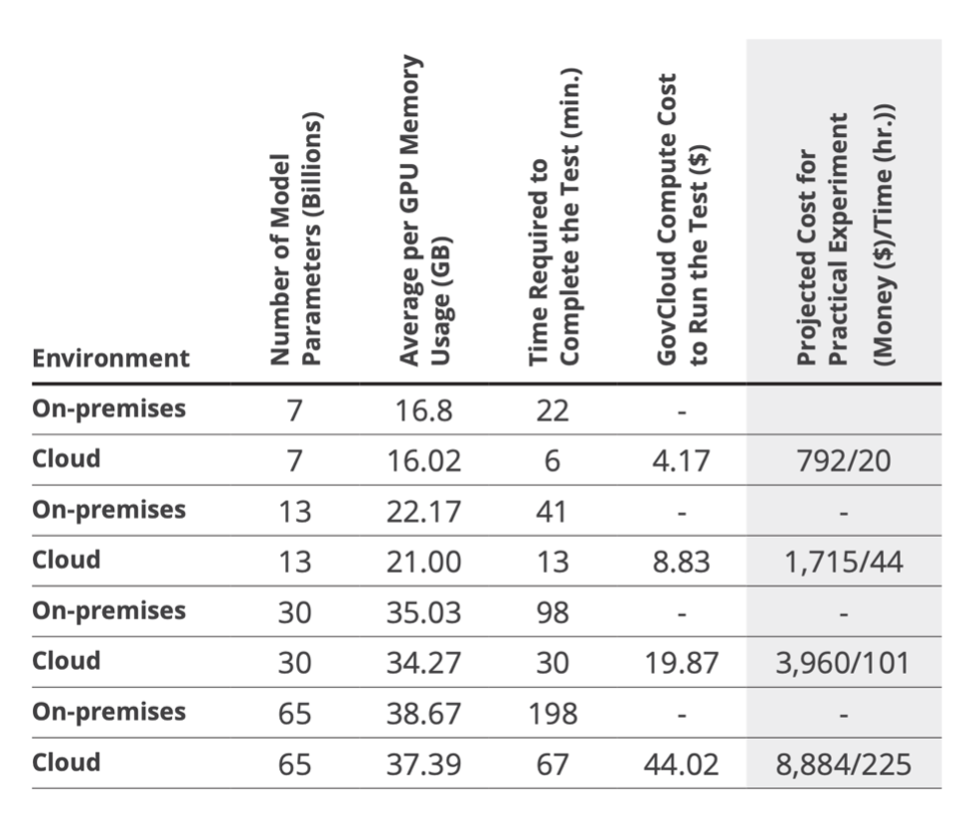
Determine 1: On this desk from our report A Retrospective in Engineering Massive Language Fashions for Nationwide Safety, we offer info on efficiency benchmark assessments for coaching LlaMA fashions of various parameter sizes on our customized 500-document set. For the estimates within the rightmost column, we outline a sensible experiment as LlaMA with 10k coaching paperwork for 3 epochs with GovCloud at $39.33/ hour, LoRA (r=1, α=2, dropout = 0.05), and DeepSpeed. On the time of the report, Prime Secret charges have been $79.0533/hour.
Trying Forward
Infrastructure is a serious consideration as organizations look to construct, deploy, and use LLMs—and different AI instruments. Extra work is required, particularly to satisfy challenges in unconventional environments, resembling these on the edge.
Because the SEI works to advance the self-discipline of AI engineering, a powerful infrastructure base can assist the scalability and robustness of AI programs. Particularly, designing for flexibility permits builders to scale an AI answer up or down relying on system and use case wants. By defending information and gold requirements, groups can make sure the integrity and assist the replicability of experiment outcomes.
Because the Division of Protection more and more incorporates AI into mission options, the infrastructure practices outlined on this publish can present price financial savings and a shorter runway to fielding AI capabilities. Particular practices like establishing a springboard platform can save time and prices in the long term.