
The deep studying revolution in pc imaginative and prescient has shifted from manually crafted options to data-driven approaches, highlighting the potential of decreasing characteristic biases. This paradigm shift goals to create extra versatile methods that excel throughout numerous imaginative and prescient duties. Whereas the Transformer structure has demonstrated effectiveness throughout totally different knowledge modalities, it nonetheless retains some inductive biases. Imaginative and prescient Transformer (ViT) reduces spatial hierarchy however maintains translation equivariance and locality by means of patch projection and place embeddings. The problem lies in eliminating these remaining inductive biases to additional enhance mannequin efficiency and flexibility.
Earlier makes an attempt to handle locality in imaginative and prescient architectures have been restricted. Most fashionable imaginative and prescient architectures, together with these geared toward simplifying inductive biases, nonetheless preserve locality of their design. Even pre-deep studying visible options like SIFT and HOG used native descriptors. Efforts to take away locality in ConvNets, comparable to changing spatial convolutional filters with 1×1 filters, resulted in efficiency degradation. Different approaches like iGPT and Perceiver explored pixel-level processing however confronted effectivity challenges or fell quick in efficiency in comparison with easier strategies.
Researchers from FAIR, Meta AI and the College of Amsterdam problem the standard perception that locality is a elementary inductive bias for imaginative and prescient duties. They discover that by treating particular person pixels as tokens for the Transformer and utilizing realized place embeddings, eradicating locality inductive biases results in higher efficiency than typical approaches like ViT. They title this method “Pixel Transformer” (PiT) and reveal its effectiveness throughout numerous duties, together with supervised classification, self-supervised studying, and picture technology with diffusion fashions. Apparently, PiT outperforms baselines outfitted with locality inductive biases. Nonetheless, the researchers acknowledge that whereas locality is probably not obligatory, it’s nonetheless helpful for sensible concerns like computational effectivity. This examine delivers a compelling message that locality isn’t an indispensable inductive bias for mannequin design.
PiT intently follows the usual Transformer encoder structure, processing an unordered set of pixels from the enter picture with learnable place embeddings. The enter sequence is mapped to a sequence of representations by means of a number of layers of Self-Consideration and MLP blocks. Every pixel is projected right into a high-dimensional vector through a linear projection layer, and a learnable [cls] token is appended to the sequence. Content material-agnostic place embeddings are realized for every place. This design removes the locality inductive bias and makes PiT permutation equivariant on the pixel degree.
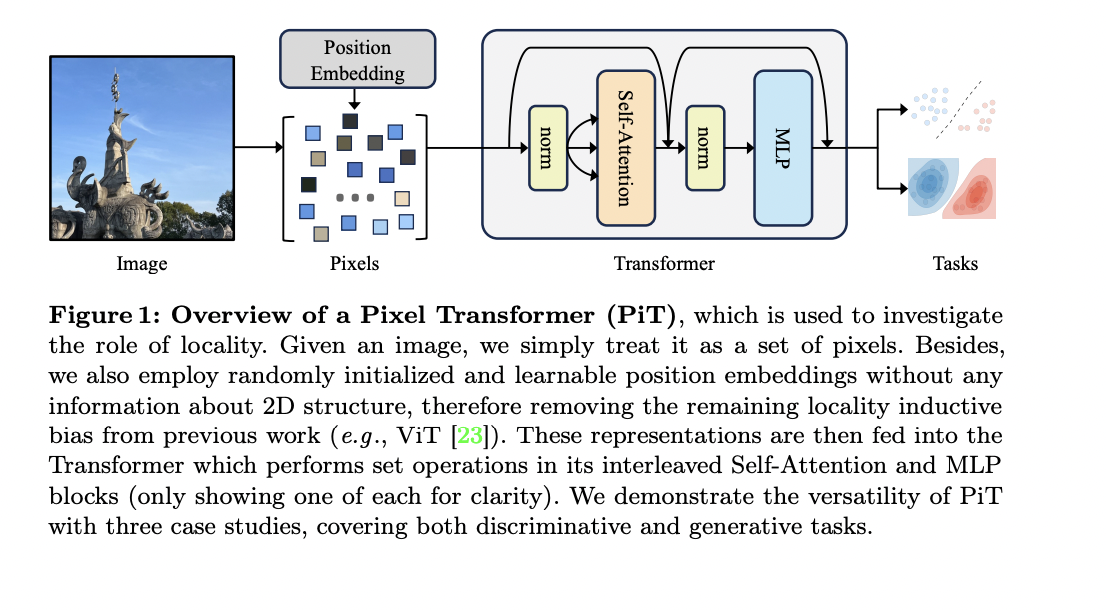
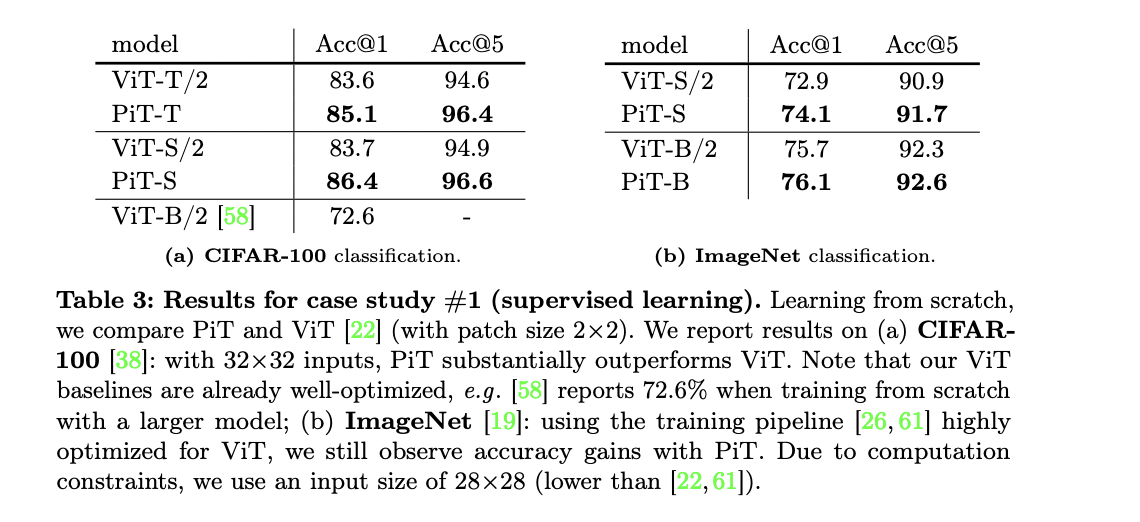
In empirical evaluations, PiT demonstrates aggressive efficiency throughout numerous duties. For picture technology utilizing diffusion fashions, PiT-L outperforms the baseline DiT-L/2 on a number of metrics, together with FID, sFID, and IS. The effectiveness of PiT generalizes effectively throughout totally different duties, architectures, and working representations. Additionally the outcomes on CIFAR100 with 32×32 inputs, PiT considerably outperforms ViT. Researchers discovered that for PiT, self-supervised pre-training with MAE improves accuracy in comparison with coaching from scratch. The hole between ViT and PiT, with pre-training, will get bigger when shifting from Tiny to Small fashions. This means PiT can probably scale higher than ViT.
Whereas PiT demonstrates that Transformers can instantly work with particular person pixels as tokens, sensible limitations stay attributable to computational complexity. Nonetheless, this exploration challenges the notion that locality is prime for imaginative and prescient fashions and means that patchification is primarily a helpful heuristic buying and selling effectivity for accuracy. This discovering opens new avenues for designing next-generation fashions in pc imaginative and prescient and past, probably resulting in extra versatile and scalable architectures that rely much less on manually inducted priors and extra on data-driven, learnable alternate options.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 44k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.