
The computational calls for of LLMs, notably with lengthy prompts, hinder their sensible use because of the quadratic complexity of the eye mechanism. As an illustration, processing a one million-token immediate with an eight-billion-parameter LLM on a single A100 GPU takes about half-hour for the preliminary stage. This results in vital delays earlier than the mannequin begins producing outputs. Whereas present strategies intention to speed up this course of, they typically want to enhance accuracy and effectivity. Dynamic sparse consideration, which adapts to various enter patterns, can cut back this latency with out in depth retraining, in contrast to mounted sparse strategies like Longformer and BigBird.
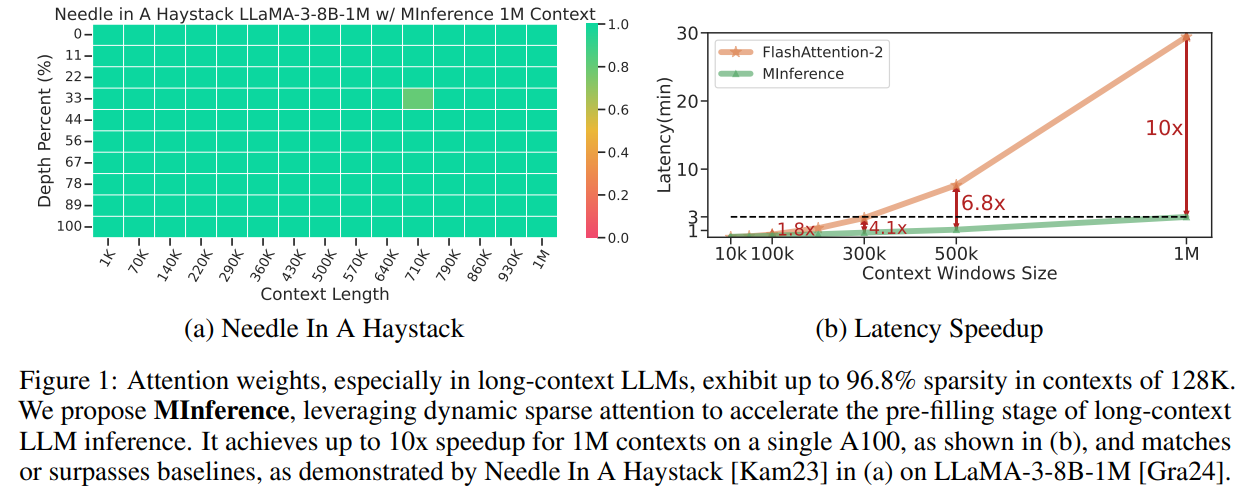
Researchers from Microsoft Company and the College of Surrey have developed MInference (Million-tokens Inference), a way to hurry up long-sequence processing in LLMs. By figuring out three distinct consideration patterns—A-shape, Vertical-Slash, and Block-Sparse—they optimize sparse calculations for GPUs. MInference dynamically builds sparse indices for these patterns throughout inference, considerably lowering latency with out altering pre-training or needing fine-tuning. Assessments on varied LLMs and benchmarks, similar to LLaMA-3-8B-1M and InfiniteBench, present as much as a 10x speedup, slicing the pre-filling stage from half-hour to three minutes on a single A100 GPU whereas sustaining accuracy.
Sparse consideration strategies intention to enhance Transformer effectivity by lowering the quadratic complexity of consideration. These strategies embody static sparse patterns (e.g., sliding home windows, dilated consideration), cluster-based approaches (e.g., hash-based, kNN-based), and dynamic sparse consideration. Nevertheless, they sometimes require pre-training, limiting their direct applicability to ready-to-use LLMs. Latest approaches lengthen LLM context home windows by staged pre-training, modified place embeddings, and exterior reminiscence modules however don’t cut back excessive inference prices. Different research optimize pre-filling and decoding in long-context LLMs but typically contain coaching from scratch or substantial overhead, making them impractical for present pre-trained fashions.
Consideration weights in long-context LLMs are inherently sparse and dynamic. As an illustration, in a 128k context, retaining simply the highest 4k columns covers 96.8% of the whole consideration. Nevertheless, the precise tokens attended to by every head can range tremendously with totally different prompts, making the eye patterns extremely context-dependent. Regardless of this variability, these patterns typically exhibit constant buildings throughout totally different layers and heads, similar to A-shape, Vertical-Slash, and Block-Sparse. Leveraging these patterns, we will considerably optimize sparse computations on GPUs, lowering the computational overhead whereas sustaining accuracy in long-context LLMs.
The experiments carried out intention to judge the effectiveness and effectivity of MInference throughout a number of benchmarks, together with InfiniteBench, RULER, and the Needle in a Haystack activity, protecting numerous long-context situations similar to QA, summarization, and retrieval. 4 state-of-the-art long-context language fashions had been utilized, together with LLaMA-3 and GLM-4, with grasping decoding for consistency. MInference’s efficiency was examined on varied context lengths, demonstrating superiority in sustaining context and processing pace over competing strategies. It integrates effectively with KV cache compression methods and considerably reduces latency, proving its sensible worth in optimizing long-context language mannequin efficiency.
The research tackles the excessive computational value and vital latency within the pre-filling stage of long-context LLMs’ consideration calculations by introducing MInference. MInference hurries up this course of utilizing dynamic sparse consideration with particular spatial aggregation patterns: A-shape, Vertical-Slash, and Block-Sparse. A kernel-aware technique optimizes the sparse sample for every consideration head, adopted by a fast approximation to create dynamic sparse masks for various inputs, facilitating environment friendly sparse consideration. Testing on benchmarks like InfiniteBench and RULER exhibits MInference maintains long-context efficiency whereas attaining as much as a 10x speedup, drastically slicing latency on a single A100 GPU from half-hour to three minutes for prompts as much as 1 million tokens. Related patterns have potential in multi-modal and encoder-decoder LLMs, indicating promising pre-filling stage acceleration functions.
Take a look at the Paper, GitHub, and Demo. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.