
The first problem in textual content embeddings in Pure Language Processing (NLP) lies in growing fashions that may carry out equally effectively throughout completely different languages. Conventional fashions are sometimes English-centric, limiting their efficacy in multilingual contexts. This hole highlights the necessity for embedding fashions educated on numerous linguistic knowledge able to understanding and deciphering a number of languages with out dropping accuracy or efficiency. Addressing this problem would considerably improve the mannequin’s utility in international functions, from automated translation companies to cross-lingual info retrieval methods.
The event of textual content embeddings depends closely on monolingual datasets, predominantly in English, which narrows their applicability. Whereas efficient for English textual content, these strategies usually should be revised when utilized to different languages. The method sometimes includes coaching fashions on giant datasets to seize linguistic nuances with out contemplating the multilingual spectrum. Consequently, there’s an evident efficiency disparity when these fashions are tasked with processing non-English languages, underscoring the need for extra inclusive and numerous coaching methodologies.
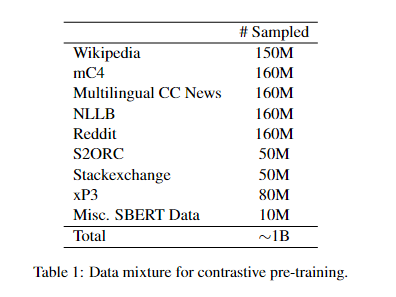
A analysis group at Microsoft Company has launched the multilingual E5 textual content embedding fashions mE5-{small / base / giant}, designed to deal with the above talked about challenges. These fashions are educated utilizing a strategy incorporating many languages, making certain higher efficiency throughout completely different linguistic contexts. By adopting a two-stage coaching course of that features contrastive pre-training on multilingual textual content pairs adopted by supervised fine-tuning, the fashions purpose to stability inference effectivity and embedding high quality, making them extremely versatile for varied multilingual functions.
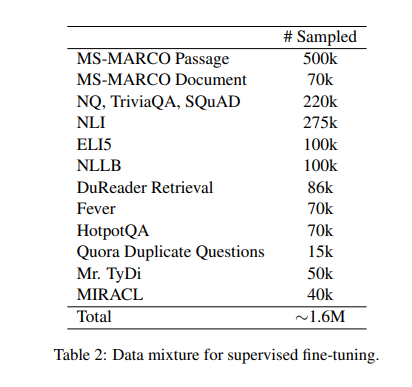
The multilingual E5 textual content embedding fashions are initialized from the multilingual MiniLM, xlm-robertabase, and xlm-roberta-large fashions. Contrastive pre-training is carried out on 1 billion multilingual textual content pairs, adopted by fine-tuning on a mix of labeled datasets. The mE5-large-instruct mannequin is fine-tuned on a brand new knowledge combination that features artificial knowledge from GPT-4. This methodology ensures that the fashions are proficient in English and exhibit excessive efficiency in different languages. The coaching course of is designed to align the fashions carefully with the linguistic properties of the goal languages, utilizing each weakly-supervised and supervised strategies. This method enhances the fashions’ multilingual capabilities and ensures that they’re adaptable to particular language duties, offering a major development in textual content embedding applied sciences.
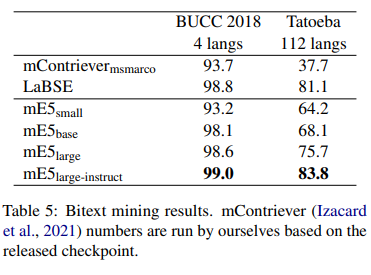
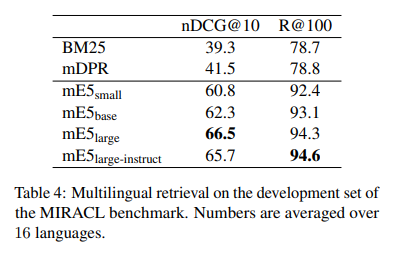
The fashions are evaluated on varied datasets, together with nDCG10, R100, MrTyDi, and DuReader. Upon analysis, the multilingual E5 fashions demonstrated distinctive efficiency throughout a number of languages and benchmarks, together with the MIRACL multilingual retrieval benchmark and Bitext mining in over 100 languages. The mE5 large-instruct mannequin surpasses the efficiency of LaBSE, particularly designed for bitext mining, as a result of expanded language protection afforded by the artificial knowledge. The analysis validates the effectiveness of the proposed coaching methodology and the numerous advantages of incorporating numerous linguistic knowledge, showcasing the fashions’ capacity to set new requirements in multilingual textual content embedding.
Creating multilingual E5 textual content embedding fashions is a beneficial development in NLP. By successfully addressing the restrictions of prior fashions and introducing a sturdy methodology for coaching on numerous linguistic knowledge, the analysis group has paved the best way for extra inclusive and environment friendly multilingual functions. These fashions improve the efficiency of language-related duties throughout completely different languages and considerably break down language obstacles in digital communication, heralding a brand new period of worldwide accessibility in info expertise.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be part of our 37k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to affix our Telegram Channel
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.