
Introduction
The Web of Issues (IoT) is producing an unprecedented quantity of knowledge. IBM estimates that annual IoT information quantity will attain roughly 175 zettabytes by 2025. That’s tons of of trillions of Gigabytes! In response to Cisco, if every Gigabyte in a Zettabyte had been a brick, 258 Nice Partitions of China may very well be constructed.
Actual time processing of IoT information unlocks its true worth by enabling companies to make well timed, data-driven choices. Nonetheless, the huge and dynamic nature of IoT information poses vital challenges for a lot of organizations. At Databricks, we acknowledge these obstacles and supply a complete information intelligence platform to assist manufacturing organizations successfully course of and analyze IoT information. By leveraging the Databricks Knowledge Intelligence Platform, manufacturing organizations can remodel their IoT information into actionable insights to drive effectivity, scale back downtime, and enhance total operational efficiency, with out the overhead of managing a posh analytics system. On this weblog, we share examples of easy methods to use Databricks’ IoT analytics capabilities to create efficiencies in your enterprise.
Downside Assertion
Whereas analyzing time sequence information at scale and in real-time is usually a vital problem, Databricks’ Delta Dwell Tables (DLT) offers a completely managed ETL resolution, simplifying the operation of time sequence pipelines and lowering the complexity of managing the underlying software program and infrastructure. DLT gives options similar to schema inference and information high quality enforcement, guaranteeing that information high quality points are recognized with out permitting schema modifications from information producers to disrupt the pipelines. Databricks offers a easy interface for parallel computation of complicated time sequence operations, together with exponential weighted shifting averages, interpolation, and resampling, through the open-source Tempo library. Furthermore, with Lakeview Dashboards, manufacturing organizations can acquire helpful insights into how metrics, similar to defect charges by manufacturing unit, is likely to be impacting their backside line. Lastly, Databricks can notify stakeholders of anomalies in real-time by feeding the outcomes of our streaming pipeline into SQL alerts. Databricks’ revolutionary options assist manufacturing organizations overcome their information processing challenges, enabling them to make knowledgeable choices and optimize their operations.
Instance 1: Actual Time Knowledge Processing
Databricks’ unified analytics platform offers a sturdy resolution for manufacturing organizations to sort out their information ingestion and streaming challenges. In our instance, we’ll create streaming tables that ingest newly landed information in real-time from a Unity Catalog Quantity, emphasizing a number of key advantages:
- Actual-Time Processing: Manufacturing organizations can course of information incrementally by using streaming tables, mitigating the price of reprocessing beforehand seen information. This ensures that insights are derived from the latest information obtainable, enabling faster decision-making.
- Schema Inference: Databricks’ Autoloader function runs schema inference, permitting flexibility in dealing with the altering schemas and information codecs from upstream producers that are all too widespread.
- Autoscaling Compute Sources: Delta Dwell Tables gives autoscaling compute assets for streaming pipelines, guaranteeing optimum useful resource utilization and cost-efficiency. Autoscaling is especially useful for IoT workloads the place the amount of knowledge may spike or plummet dramatically based mostly on seasonality and time of day.
- Precisely-As soon as Processing Ensures: Streaming on Databricks ensures that every row is processed precisely as soon as, eliminating the chance of pipelines creating duplicate or lacking information.
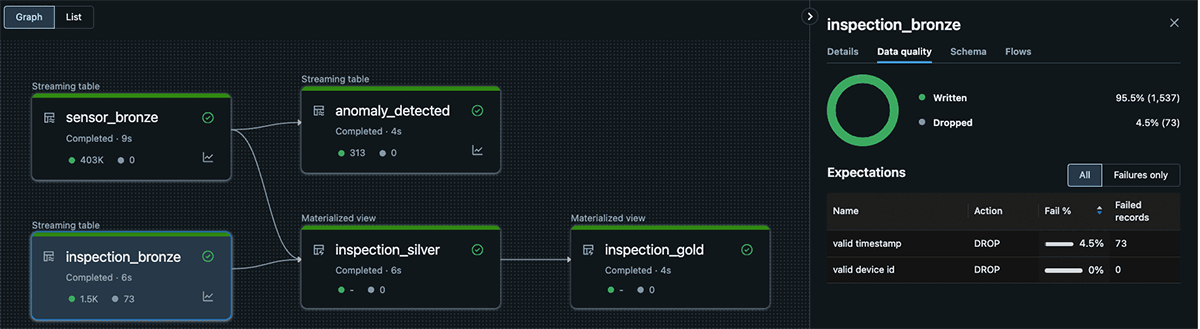
- Knowledge High quality Checks: DLT additionally gives information high quality checks, helpful for validating that values are inside sensible ranges or guaranteeing main keys exist earlier than operating a be part of. These checks assist keep information high quality and permit for triggering warnings or dropping rows the place wanted.
Manufacturing organizations can unlock helpful insights, enhance operational effectivity, and make data-driven choices with confidence by leveraging Databricks’ real-time information processing capabilities.
@dlt.desk(
identify='inspection_bronze',
remark='Masses uncooked inspection information into the bronze layer'
) # Drops any rows the place timestamp or device_id are null, as these rows would not be usable for our subsequent step
@dlt.expect_all_or_drop({"legitimate timestamp": "`timestamp` will not be null", "legitimate gadget id": "device_id will not be null"})
def autoload_inspection_data():
schema_hints = 'defect float, timestamp timestamp, device_id integer'
return (
spark.readStream.format('cloudFiles')
.choice('cloudFiles.format', 'csv')
.choice('cloudFiles.schemaHints', schema_hints)
.choice('cloudFiles.schemaLocation', 'checkpoints/inspection')
.load('inspection_landing')
)
Instance 2: Tempo for Time Sequence Evaluation
Given streams from disparate information sources similar to sensors and inspection studies, we’d must calculate helpful time sequence options similar to exponential shifting common or pull collectively our instances sequence datasets. This poses a few challenges:
- How can we deal with null, lacking, or irregular information in our time sequence?
- How can we calculate time sequence options similar to exponential shifting common in parallel on a large dataset with out exponentially growing price?
- How can we pull collectively our datasets when the timestamps do not line up? On this case, our inspection defect warning may get flagged hours after the sensor information is generated. We’d like a be part of that enables “worth is true” guidelines, becoming a member of in the latest sensor information that doesn’t exceed the inspection timestamp. This manner we will seize the options main as much as the defect warning, with out leaking information that arrived afterwards into our function set.
Every of those challenges may require a posh, customized library particular to time sequence information. Fortunately, Databricks has performed the laborious half for you! We’ll use the open supply library Tempo from Databricks Labs to make these difficult operations easy. TSDF, Tempo’s time sequence dataframe interface, permits us to interpolate lacking information with the imply from the encompassing factors, calculate an exponential shifting common for temperature, and do our “worth is true” guidelines be part of, generally known as an as-of be part of. For instance, in our DLT Pipeline:
@dlt.desk(
identify='inspection_silver',
remark='Joins bronze sensor information with inspection studies'
)
def create_timeseries_features():
inspections = dlt.learn('inspection_bronze').drop('_rescued_data')
inspections_tsdf = TSDF(inspections, ts_col='timestamp', partition_cols=['device_id']) # Create our inspections TSDF
raw_sensors = (
dlt.learn('sensor_bronze')
.drop('_rescued_data') # Flip the signal when destructive in any other case hold it the identical
.withColumn('air_pressure', when(col('air_pressure') < 0, -col('air_pressure'))
.in any other case(col('air_pressure')))
)
sensors_tsdf = (
TSDF(raw_sensors, ts_col='timestamp', partition_cols=['device_id', 'trip_id', 'factory_id', 'model_id'])
.EMA('rotation_speed', window=5) # Exponential shifting common over 5 rows
.resample(freq='1 hour', func='imply') # Resample into 1 hour intervals
)
return (
inspections_tsdf # Value is proper (as-of) be part of!
.asofJoin(sensors_tsdf, right_prefix='sensor')
.df # Return the vanilla Spark Dataframe
.withColumnRenamed('sensor_trip_id', 'trip_id') # Rename some columns to match our schema
.withColumnRenamed('sensor_model_id', 'model_id')
.withColumnRenamed('sensor_factory_id', 'factory_id')
)Instance 3: Native Dashboarding and Alerting
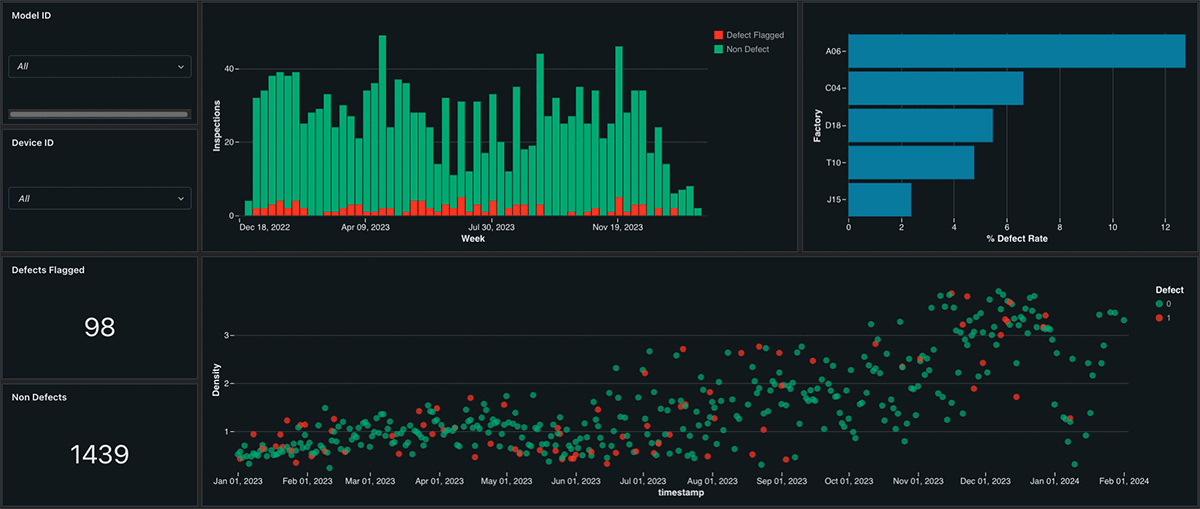
As soon as we’ve outlined our DLT Pipeline we have to take motion on the offered insights. Databricks gives SQL Alerts, which may be configured to ship electronic mail, Slack, Groups, or generic webhook messages when sure circumstances in Streaming Tables are met. This permits manufacturing organizations to rapidly reply to points or alternatives as they come up. Moreover, Databricks’ Lakeview Dashboards present a user-friendly interface for aggregating and reporting on information, with out the necessity for added licensing prices. These dashboards are immediately built-in into the Knowledge Intelligence Platform, making it simple for groups to entry and analyze information in actual time. Materialized Views and Lakehouse Dashboards are a profitable mixture, pairing lovely visuals with immediate efficiency:
Conclusion
Total, Databricks’ DLT Pipelines, Tempo, SQL Alerts, and Lakeview Dashboards present a robust, unified function set for manufacturing organizations seeking to acquire real-time insights from their information and enhance their operational effectivity. By simplifying the method of managing and analyzing information, Databricks helps manufacturing organizations deal with what they do greatest: creating, shifting, and powering the world. With the difficult quantity, velocity, and selection necessities posed by IoT information, you want a unified information intelligence platform that democratizes information insights. Get began right now with our resolution accelerator for IoT Time Sequence Evaluation!
Right here is the hyperlink to this resolution accelerator.