
Knowledge governance is a key enabler for groups adopting a data-driven tradition and operational mannequin to drive innovation with knowledge. Amazon DataZone is a completely managed knowledge administration service that makes it quicker and simpler for purchasers to catalog, uncover, share, and govern knowledge saved throughout Amazon Net Companies (AWS), on premises, and on third-party sources. It additionally makes it simpler for engineers, knowledge scientists, product managers, analysts, and enterprise customers to entry knowledge all through a corporation to find, use, and collaborate to derive data-driven insights.
Amazon DataZone means that you can merely and securely govern end-to-end knowledge property saved in your Amazon Redshift knowledge warehouses or knowledge lakes cataloged with the AWS Glue knowledge catalog. As you expertise the advantages of consolidating your knowledge governance technique on high of Amazon DataZone, it’s possible you’ll need to lengthen its protection to new, various knowledge repositories (both self-managed or as managed companies) together with relational databases, third-party knowledge warehouses, analytic platforms and extra.
This publish explains how one can lengthen the governance capabilities of Amazon DataZone to knowledge property hosted in relational databases based mostly on MySQL, PostgreSQL, Oracle or SQL Server engines. What’s coated on this publish is already applied and accessible within the Steerage for Connecting Knowledge Merchandise with Amazon DataZone answer, printed within the AWS Options Library. This answer was constructed utilizing the AWS Cloud Improvement Equipment (AWS CDK) and was designed to be simple to arrange in any AWS surroundings. It’s based mostly on a serverless stack for cost-effectiveness and ease and follows the very best practices within the AWS Nicely-Architected-Framework.
Self-service analytics expertise in Amazon DataZone
In Amazon DataZone, knowledge producers populate the enterprise knowledge catalog with knowledge property from knowledge sources such because the AWS Glue knowledge catalog and Amazon Redshift. In addition they enrich their property with enterprise context to make them accessible to the shoppers.
After the information asset is obtainable within the Amazon DataZone enterprise catalog, knowledge shoppers equivalent to analysts and knowledge scientists can search and entry this knowledge by requesting subscriptions. When the request is accepted, Amazon DataZone can routinely provision entry to the managed knowledge asset by managing permissions in AWS Lake Formation or Amazon Redshift in order that the information client can begin querying the information utilizing instruments equivalent to Amazon Athena or Amazon Redshift. Word {that a} managed knowledge asset is an asset for which Amazon DataZone can handle permissions. It consists of these saved in Amazon Easy Storage Service (Amazon S3) knowledge lakes (and cataloged within the AWS Glue knowledge catalog) or Amazon Redshift.
As you’ll see subsequent, when working with relational databases, a lot of the expertise described above will stay the identical as a result of Amazon DataZone supplies a set options and integrations that knowledge producers and shoppers can use with a constant expertise, even when working with extra knowledge sources. Nonetheless, there are some extra duties that have to be accounted for to realize a frictionless expertise, which shall be addressed later on this publish.
The next diagram illustrates a high-level overview of the circulation of actions when an information producer and client collaborate round an information asset saved in a relational database utilizing Amazon DataZone.
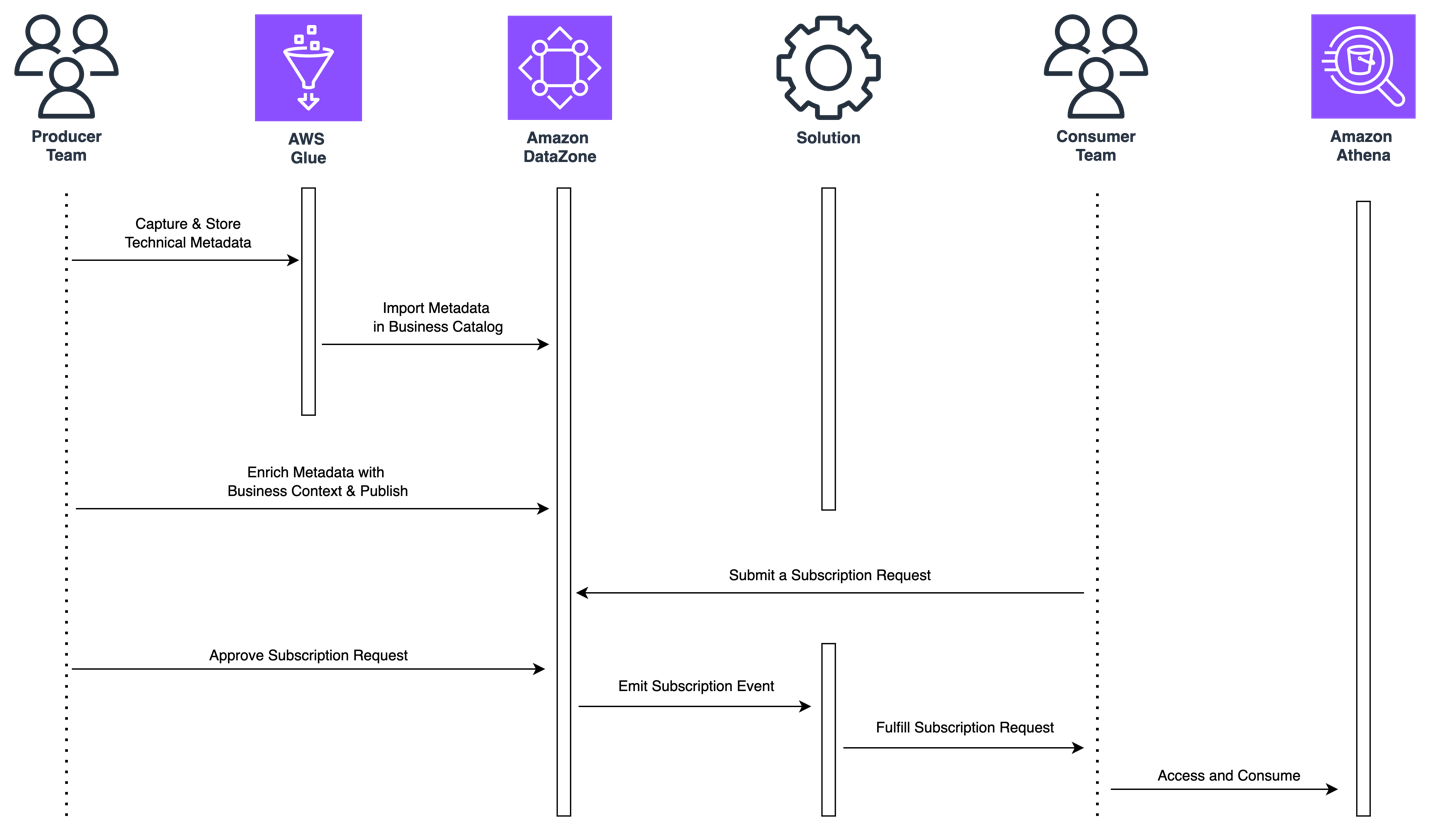
Determine 1: Circulate of actions for self-service analytics round knowledge property saved in relational databases
First, the information producer must seize and catalog the technical metadata of the information asset.
The AWS Glue knowledge catalog can be utilized to retailer metadata from a wide range of knowledge property, like these saved in relational databases, together with their schema, connection particulars, and extra. It provides AWS Glue connections and AWS Glue crawlers as a method to seize the information asset’s metadata simply from their supply database and maintain it updated. Later on this publish, we’ll introduce how the “Steerage for Connecting Knowledge Merchandise with Amazon DataZone” answer may also help knowledge producers simply deploy and run AWS Glue connections and crawlers to seize technical metadata.
Second, the information producer must consolidate the information asset’s metadata within the enterprise catalog and enrich it with enterprise metadata. The producer additionally must handle and publish the information asset so it’s discoverable all through the group.
Amazon DataZone supplies built-in knowledge sources that will let you simply fetch metadata (equivalent to desk title, column title, or knowledge sorts) of property within the AWS Glue knowledge catalog into Amazon DataZone’s enterprise catalog. You may also embody knowledge high quality particulars due to the mixing with AWS Glue Knowledge High quality or exterior knowledge high quality options. Amazon DataZone additionally supplies metadata varieties and generative synthetic intelligence (generative AI) pushed options to simplify the enrichment of information property’ metadata with enterprise context. Lastly, the Amazon DataZone knowledge portal helps you handle and publish your knowledge property.
Third, an information client must subscribe to the information asset printed by the producer. To take action, the information client will submit a subscription request that, as soon as accepted by the producer, triggers a mechanism that routinely provisions learn entry to the patron with out transferring or duplicating knowledge.
In Amazon DataZone, knowledge property saved in relational databases are thought of unmanaged knowledge property, which implies that Amazon DataZone will be unable to handle permissions to them on the shopper’s behalf. That is the place the “Steerage for Connecting Knowledge Merchandise with Amazon DataZone” answer additionally is useful as a result of it deploys the required mechanism to provision entry routinely when subscriptions are accepted. You’ll find out how the answer does this later on this publish.
Lastly, the information client must entry the subscribed knowledge as soon as entry has been provisioned. Relying on the use case, shoppers want to use SQL-based engines to run exploratory evaluation, enterprise intelligence (BI) instruments to construct dashboards for decision-making, or knowledge science instruments for machine studying (ML) improvement.
Amazon DataZone supplies blueprints to offer choices for consuming knowledge and supplies default ones for Amazon Athena and Amazon Redshift, with extra to return quickly. Amazon Athena connectors is an efficient strategy to run one-time queries on high of relational databases. Later on this publish we’ll introduce how the “Steerage for Connecting Knowledge Merchandise with Amazon DataZone” answer may also help knowledge shoppers deploy Amazon Athena connectors and grow to be a platform to deploy customized instruments for knowledge shoppers.
Resolution’s core elements
Now that we have now coated what the self-service analytics expertise appears like when working with knowledge property saved in relational databases, let’s assessment at a excessive degree the core elements of the “Steerage for Connecting Knowledge Merchandise with Amazon DataZone” answer.
You’ll be capable to determine the place a number of the core elements match within the circulation of actions described within the final part as a result of they have been developed to carry simplicity and automation for a frictionless expertise. Different elements, though they aren’t straight tied to the expertise, are as related since they maintain the conditions for the answer to work correctly.

Determine 2: Resolution’s core elements
- The toolkit element is a set of instruments (in AWS Service Catalog) that producer and client groups can simply deploy and use, in a self-service trend, to assist a number of the duties described within the expertise, equivalent to the next.
- As an information producer, seize metadata from knowledge property saved in relational databases into the AWS Glue knowledge catalog by leveraging AWS Glue connectors and crawlers.
- As an information client, question a subscribed knowledge asset straight from its supply database with Amazon Athena by deploying and utilizing an Amazon Athena connector.
- The workflows element is a set of automated workflows (orchestrated by way of AWS Step Capabilities) that can set off routinely on sure Amazon DataZone occasions equivalent to:
- When a brand new Amazon DataZone knowledge lake surroundings is efficiently deployed in order that its default capabilities are prolonged to assist this answer’s toolkit.
- When a subscription request is accepted by an information producer in order that entry is provisioned routinely for knowledge property saved in relational databases. This workflow is the mechanism that was referred to within the expertise of the final part because the means to provision entry to unmanaged knowledge property ruled by Amazon DataZone.
- When a subscription is revoked or canceled in order that entry is revoked routinely for knowledge property in relational databases.
- When an current Amazon DataZone surroundings deletion begins in order that non default Amazon DataZone capabilities are eliminated.
The next desk lists the a number of AWS companies that the answer makes use of to supply an add-on for Amazon DataZone with the aim of offering the core elements described on this part.
| AWS Service | Description |
| Amazon DataZone | Knowledge governance service whose capabilities are prolonged when deploying this add-on answer. |
| Amazon EventBridge | Used as a mechanism to seize Amazon DataZone occasions and set off answer’s corresponding workflow. |
| Amazon Step Capabilities | Used as orchestration engine to execute answer workflows. |
| AWS Lambda | Supplies logic for the workflow duties, equivalent to extending surroundings’s capabilities or sharing secrets and techniques with surroundings credentials. |
| AWS Secrets and techniques Supervisor | Used to retailer database credentials as secrets and techniques. Every client surroundings with granted subscription to 1 or many knowledge property in the identical relational database could have its personal particular person credentials (secret). |
| Amazon DynamoDB | Used to retailer workflows’ output metadata. Governance groups can observe subscription particulars for knowledge property saved in relational databases. |
| Amazon Service Catalog | Used to supply a complementary toolkit for customers (producers and shoppers), in order that they will provision merchandise to execute duties particular to their roles in a self-service method. |
| AWS Glue | A number of elements are used, such because the AWS Glue knowledge catalog because the direct publishing supply for Amazon DataZone enterprise catalog and connectors and crawlers to attach on infer schemas from knowledge property saved in relational databases. |
| Amazon Athena | Used as one of many consumption mechanisms that permit customers and groups to question knowledge property that they’re subscribed to, both on high of Amazon S3 backed knowledge lakes and relational databases. |
Resolution overview
Now let’s dive into the workflow that routinely provisions entry to an accepted subscription request (2b within the final part). Determine 3 outlines the AWS companies concerned in its execution. It additionally illustrates when the answer’s toolkit is used to simplify a number of the duties that producers and shoppers have to carry out earlier than and after a subscription is requested and granted. For those who’d prefer to study extra about different workflows on this answer, please check with the implementation information.
The structure illustrates how the answer works in a multi-account surroundings, which is a typical state of affairs. In a multi-account surroundings, the governance account will host the Amazon DataZone area and the remaining accounts shall be related to it. The producer account hosts the subscription’s knowledge asset and the patron account hosts the surroundings subscribing to the information asset.

Determine 3 – Structure for subscription grant workflow
Resolution walkthrough
1. Seize knowledge asset’s metadata
A knowledge producer captures metadata of a knowledge asset to be printed from its knowledge supply into the AWS Glue catalog. This may be carried out through the use of AWS Glue connections and crawlers. To hurry up the method, the answer features a Producer Toolkit utilizing the AWS Service Catalog to simplify the deployment of such assets by simply filling out a type.
As soon as the knowledge asset’s technical metadata is captured, the information producer will run an information supply job in Amazon DataZone to publish it into the enterprise catalog. Within the Amazon DataZone portal, a client will uncover the information asset and subsequently, subscribe to it when wanted. Any subscription motion will create a subscription request in Amazon DataZone.
2. Approve a subscription request
The information producer approves the incoming subscription request. An occasion is distributed to Amazon EventBridge, the place a rule deployed by the answer captures it and triggers an occasion of the AWS Step Capabilities major state machine within the governance account for every surroundings of the subscribing mission.
3. Fulfill read-access within the relational database (producer account)
The major state machine within the governance account triggers an occasion of the AWS Step Capabilities secondary state machine within the producer account, which is able to run a set of AWS Lambda features to:
- Retrieve the subscription knowledge asset’s metadata from the AWS Glue catalog, together with the main points required for connecting to the knowledge supply internet hosting the subscription’s knowledge asset.
- Connect with the knowledge supply internet hosting the subscription’s knowledge asset, create credentials for the subscription’s goal surroundings (if nonexistent) and grant learn entry to the subscription’s knowledge asset.
- Retailer the brand new knowledge supply credentials in an AWS Secrets and techniques Supervisor producer secret (if nonexistent) with a useful resource coverage permitting learn cross-account entry to the surroundings’s related client account.
- Replace monitoring data in Amazon DynamoDB within the governance account.
4. Share entry credentials to the subscribing surroundings (client account)
The major state machine within the governance account triggers an occasion of the AWS Step Capabilities secondary state machine within the client account, which is able to run a set of AWS Lambda features to:
- Retrieve connection credentials from the producer secret within the producer account by way of cross-account entry, then copy the credentials into a brand new client secret (if nonexistent) in AWS Secrets and techniques Supervisor native to the patron account.
- Replace monitoring data in Amazon DynamoDB within the governance account.
5. Entry the subscribed knowledge
The information client makes use of the patron secret to hook up with that knowledge supply and question the subscribed knowledge asset utilizing any most popular means.
To hurry up the method, the answer features a client toolkit utilizing the AWS Service Catalog to simplify the deployment of such assets by simply filling out a type. Present scope for this toolkit features a software that deploys an Amazon Athena connector for a corresponding MySQL, PostgreSQL, Oracle, or SQL Server knowledge supply. Nonetheless, it may very well be prolonged to assist different instruments on high of AWS Glue, Amazon EMR, Amazon SageMaker, Amazon Quicksight, or different AWS companies, and maintain the identical simple-to-deploy expertise.
Conclusion
On this publish we went by way of how groups can lengthen the governance of Amazon DataZone to cowl relational databases, together with these with MySQL, Postgres, Oracle, and SQL Server engines. Now, groups are one step additional in unifying their knowledge governance technique in Amazon DataZone to ship self-service analytics throughout their organizations for all of their knowledge.
As a ultimate thought, the answer defined on this publish introduces a replicable sample that may be prolonged to different relational databases. The sample relies on entry grants by way of environment-specific credentials which are shared as secrets and techniques in AWS Secrets and techniques Supervisor. For knowledge sources with completely different authentication and authorization strategies, the answer will be prolonged to supply the required means to grant entry to them (equivalent to by way of AWS Id and Entry Administration (IAM) roles and insurance policies). We encourage groups to experiment with this method as effectively.
get began
With the “Steerage for Connecting Knowledge Merchandise with Amazon DataZone” answer, you might have a number of assets to study extra, check it, and make it your personal.
You may study extra on the AWS Options Library options web page. You may obtain the supply code from GitHub and comply with the README file to study extra of its underlying elements and methods to set it up and deploy it in a single or multi-account surroundings. You may also use it to discover ways to consider prices when utilizing the answer. Lastly, it explains how greatest practices from the AWS Nicely-Architected Framework have been included within the answer.
You may comply with the answer’s hands-on lab both with the assistance of the AWS Options Architect staff or by yourself. The lab will take you thru the whole workflow described on this publish for every of the supported database engines (MySQL, PostgreSQL, Oracle, and SQL Server). We encourage you to begin right here earlier than making an attempt the answer in your personal testing environments and your personal pattern datasets. After getting full readability on methods to arrange and use the answer, you’ll be able to check it together with your workloads and even customise it to make it your personal.
The implementation information is an asset for purchasers desirous to customise or lengthen the answer to their particular challenges and wishes. It supplies an in-depth description of the code repository construction and the answer’s underlying elements, in addition to all the main points to know the mechanisms used to trace all subscriptions dealt with by the answer.
Concerning the authors
 Jose Romero is a Senior Options Architect for Startups at AWS, based mostly in Austin, TX, US. He’s obsessed with serving to prospects architect fashionable platforms at scale for knowledge, AI, and ML. As a former senior architect with AWS Skilled Companies, he enjoys constructing and sharing options for frequent complicated issues in order that prospects can speed up their cloud journey and undertake greatest practices. Join with him on LinkedIn..
Jose Romero is a Senior Options Architect for Startups at AWS, based mostly in Austin, TX, US. He’s obsessed with serving to prospects architect fashionable platforms at scale for knowledge, AI, and ML. As a former senior architect with AWS Skilled Companies, he enjoys constructing and sharing options for frequent complicated issues in order that prospects can speed up their cloud journey and undertake greatest practices. Join with him on LinkedIn..
 Leonardo Gómez is a Principal Huge Knowledge / ETL Options Architect at AWS, based mostly in Florida, US. He has over a decade of expertise in knowledge administration, serving to prospects across the globe deal with their enterprise and technical wants. Join with him on LinkedIn.
Leonardo Gómez is a Principal Huge Knowledge / ETL Options Architect at AWS, based mostly in Florida, US. He has over a decade of expertise in knowledge administration, serving to prospects across the globe deal with their enterprise and technical wants. Join with him on LinkedIn.