
Contrastive pre-training utilizing massive, noisy image-text datasets has develop into in style for constructing normal imaginative and prescient representations. These fashions align international picture and textual content options in a shared house by comparable and dissimilar pairs, excelling in duties like picture classification and retrieval. Nonetheless, they need assistance with fine-grained duties akin to localization and spatial relationships. Current efforts incorporate losses between picture patches and textual content tokens to seize finer particulars, enhancing efficiency in fine-grained retrieval, picture classification, object detection, and segmentation. Regardless of these developments, challenges like computational expense and reliance on pretrained fashions persist.
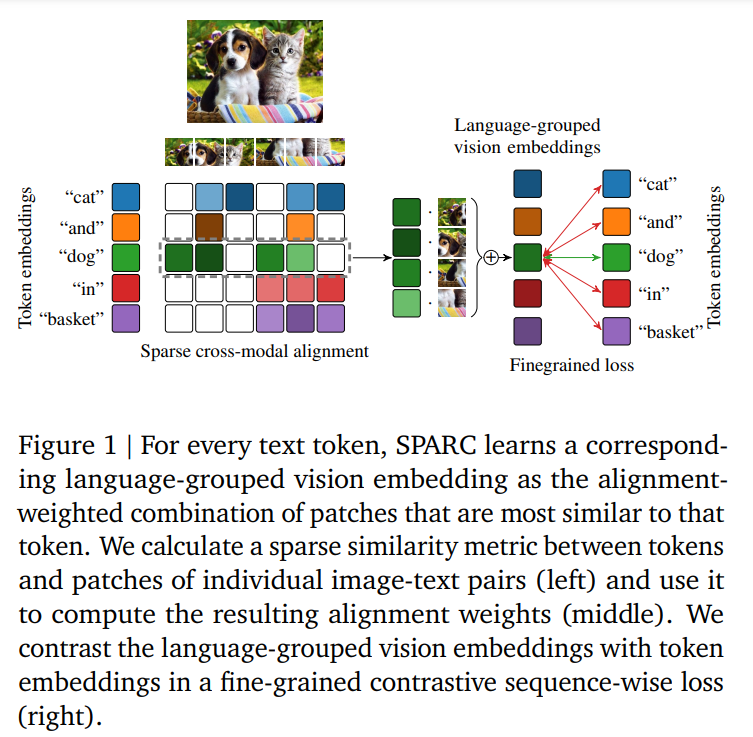
Researchers from Google DeepMind have developed SPARse Advantageous-grained Contrastive Alignment (SPARC), a technique for pretraining fine-grained multimodal representations from image-text pairs. SPARC focuses on studying teams of picture patches similar to particular person phrases in captions. It makes use of a sparse similarity metric to compute language-grouped imaginative and prescient embeddings for every token, permitting detailed info seize in a computationally environment friendly method. SPARC combines fine-grained sequence-wise loss with a contrastive loss, enhancing efficiency in coarse-grained duties like classification and fine-grained duties like retrieval, object detection, and segmentation. The tactic additionally improves mannequin faithfulness and captioning in foundational vision-language fashions.
Contrastive image-text pre-training strategies like CLIP and ALIGN have popularized studying normal visible representations by leveraging textual supervision from large-scale information scraped from the web.FILIP proposes a cross-modal late interplay mechanism to optimize the token-wise most similarity between picture and textual content tokens, addressing the issue of coarse visible illustration in international matching. PACL begins from CLIP-pre-trained imaginative and prescient and textual content encoders and trains an adapter by a contrastive goal to enhance fine-grained understanding. GLoRIA builds localized visible representations by contrasting attention-weighted patch embeddings with textual content tokens, but it surely turns into computationally intensive for big batch sizes.
SPARC is a technique for pretraining fine-grained multimodal representations from image-text pairs. It makes use of a sparse similarity metric between picture patches and language tokens to be taught a grouping of picture patches for every token within the caption. The token and language-grouped imaginative and prescient embeddings are then contrasted by a fine-grained sequence-wise loss that solely will depend on particular person samples, enabling detailed info to be discovered computationally inexpensively. SPARC combines this fine-grained loss with a contrastive loss between international picture and textual content embeddings to encode international and native info concurrently.
The SPARC research assesses its efficiency throughout image-level duties like classification and region-level duties akin to retrieval, object detection, and segmentation. It outperforms different strategies in each process varieties and enhances mannequin faithfulness and captioning in foundational vision-language fashions. Within the analysis, zero-shot segmentation is carried out by computing patch embeddings and figuring out class matches by cosine similarity with textual content embeddings of ground-truth courses. Intersection over Union (IoU) is then calculated to measure the accuracy of predicted and ground-truth segmentations for every class.
SPARC improves efficiency over competing approaches in image-level duties (classification) and region-level duties (retrieval, object detection, and segmentation). SPARC achieves improved mannequin faithfulness and captioning in foundational vision-language fashions. The analysis of SPARC contains zero-shot segmentation, the place patch embeddings of a picture are in comparison with textual content embeddings of ground-truth courses. The matching class for every patch is assigned primarily based on most cosine similarity, and IoU is calculated for every class. The research mentions utilizing Flamingo’s Perceiver Resampler in coaching SPARC, which suggests incorporating this methodology within the experimental setup.

In conclusion, SPARC is a technique that helps pretrain fine-grained multimodal representations from image-text pairs. To realize this, it makes use of fine-grained contrastive alignment and a contrastive loss between international picture and textual content embeddings. SPARC outperforms competing approaches in image-level duties akin to classification and region-level duties akin to retrieval, object detection, and segmentation. SPARC improves mannequin faithfulness and captioning in foundational vision-language fashions. To guage SPARC, zero-shot segmentation is used the place patch embeddings of a picture are in comparison with textual content embeddings of ground-truth courses. The research suggests utilizing Flamingo’s Perceiver Resampler in coaching SPARC and recommends incorporating it within the experimental setup.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
