
In human-computer interplay, multimodal programs that make the most of textual content and pictures promise a extra pure and fascinating means for machines to speak with people. Such programs, nevertheless, are closely depending on datasets that mix these components meaningfully. Conventional strategies for creating these datasets have usually fallen brief, counting on static picture databases with restricted selection or elevating vital privateness and high quality issues when sourcing pictures from the true world.
Introducing MAGID (Multimodal Augmented Generative Pictures Dialogues), a groundbreaking framework born out of the collaborative efforts of researchers from the esteemed College of Waterloo and the progressive AWS AI Labs. This cutting-edge strategy is about to redefine the creation of multimodal dialogues by seamlessly integrating numerous and high-quality artificial pictures with textual content dialogues. The essence of MAGID lies in its skill to rework text-only conversations into wealthy, multimodal interactions with out the pitfalls of conventional dataset augmentation methods.
MAGID’s coronary heart is a meticulously designed pipeline consisting of three core elements:
- An LLM-based scanner
- A diffusion-based picture generator
- A complete high quality assurance module
The method begins with the scanner figuring out textual content utterances inside dialogues that may profit from visible augmentation. This choice is important, because it determines the contextual relevance of the photographs to be generated.
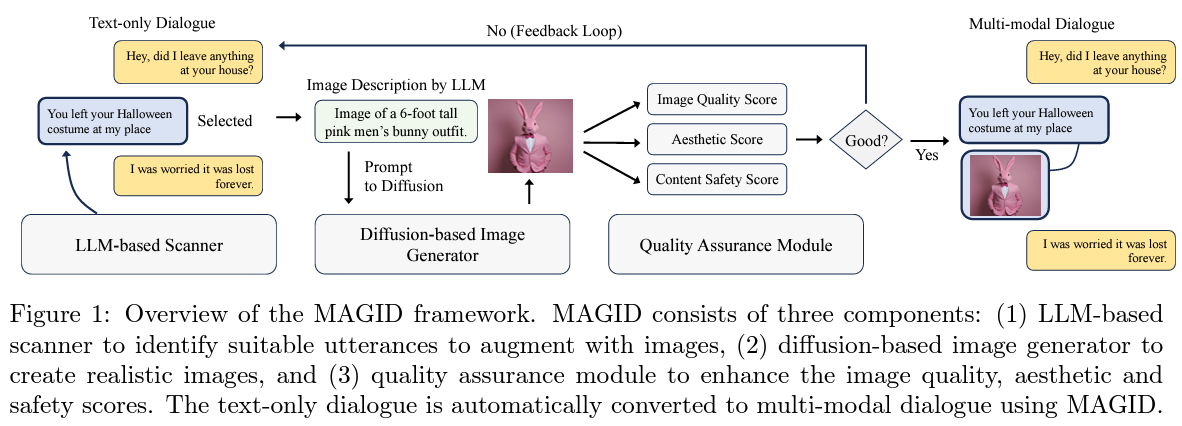
Following the choice, the diffusion mannequin takes middle stage, producing pictures that complement the chosen utterances and enrich the general dialogue. This mannequin excels at producing assorted and contextually aligned pictures, drawing from varied visible ideas to make sure the generated dialogues replicate the range of real-world conversations.
Nevertheless, the era of pictures is simply a part of the equation. MAGID incorporates a meticulously designed and complete high quality assurance module to make sure the augmented dialogues’ utility and integrity. This module evaluates the generated pictures on a number of fronts, together with their alignment with the corresponding textual content, aesthetic high quality, and adherence to security requirements. It ensures that every picture matches the textual content in context and content material, meets excessive visible requirements, and avoids inappropriate content material.
The efficacy of MAGID was rigorously examined towards state-of-the-art baselines and thru complete human evaluations. The outcomes had been nothing wanting outstanding, with MAGID not solely matching however usually surpassing different strategies in creating multimodal dialogues that had been participating, informative, and aesthetically pleasing. Particularly, human evaluators persistently rated MAGID-generated dialogues as superior, notably noting the relevance and high quality of the photographs when in comparison with these produced by retrieval-based strategies. Together with numerous and contextually aligned pictures considerably enhanced the dialogues’ realism and engagement, as evidenced by MAGID’s favorable comparability to actual datasets in human analysis metrics.
MAGID affords a strong resolution to the longstanding challenges in multimodal dataset era via its refined mix of generative fashions and high quality assurance. By eschewing reliance on static picture databases and mitigating privateness issues related to real-world pictures, MAGID paves the best way for creating wealthy, numerous, and high-quality multimodal dialogues. This development is not only a technical achievement however a stepping stone towards realizing the total potential of multimodal interactive programs. As these programs change into more and more integral to our digital lives, frameworks like MAGID, guarantee they’ll evolve in methods which are each progressive and aligned with the nuanced dynamics of human dialog.
In abstract, the introduction of MAGID by the workforce from the College of Waterloo and AWS AI Labs marks a major leap ahead in AI and human-computer interplay. By addressing the important want for high-quality, numerous multimodal datasets, MAGID permits the event of extra refined and fascinating multimodal programs. Its skill to generate artificial dialogues which are just about indistinguishable from actual human conversations underscores the immense potential of AI to bridge the hole between people and machines, making interactions extra pure, pleasing, and, finally, human.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our Telegram Channel
You might also like our FREE AI Programs….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a concentrate on Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.