
Overview
On this information, you’ll:
- Achieve a foundational understanding of RAG, its limitations and shortcomings
- Perceive the concept behind Self-RAG and the way it may result in higher LLM efficiency
- Discover ways to make the most of OpenAI API (GPT-4 mannequin) with the Rockset API suite (vector database) together with LangChain to carry out RAG (Retrieval-Augmented Era) and create an end-to-end net software utilizing Streamlit
- Discover an end-to-end Colab pocket book that you may run with none dependencies in your native working system: RAG-Chatbot Workshop
Massive Language Fashions and their Limitations
Massive Language Fashions (LLMs) are educated on giant datasets comprising textual content, pictures, or/and movies, and their scope is usually restricted to the subjects or data contained throughout the coaching information. Secondly, as LLMs are educated on datasets which are static and infrequently outdated by the point they’re deployed, they’re unable to offer correct or related details about current developments or tendencies. This limitation makes them unsuitable for situations the place real-time up-to-the-minute data is crucial, comparable to information reporting, and so forth.
As coaching LLMs is sort of costly, with fashions comparable to GPT-3 costing over $4.6 million, retraining the LLM is generally not a possible choice to handle these shortcomings. This explains why real-time situations, comparable to investigating the inventory market or making suggestions, can not rely upon or make the most of conventional LLMs.
Attributable to these aforementioned limitations, the Retrieval-Augmented Era (RAG) strategy was launched to beat the innate challenges of conventional LLMs.
What’s RAG?
RAG (Retrieval-Augmented Era) is an strategy designed to boost the responses and capabilities of conventional LLMs (Massive Language Fashions). By integrating exterior data sources with the LLM, RAG tackles the challenges of outdated, inaccurate, and hallucinated responses usually noticed in conventional LLMs.
How RAG Works
RAG extends the capabilities of an LLM past its preliminary coaching information by offering extra correct and up-to-date responses. When a immediate is given to the LLM, RAG first makes use of the immediate to drag related data from an exterior information supply. The retrieved data, together with the preliminary immediate, is then handed to the LLM to generate an knowledgeable and correct response. This course of considerably reduces hallucinations that happen when the LLM has irrelevant or partially related data for a sure topic.
Benefits of RAG
- Enhanced Relevance: By incorporating retrieved paperwork, RAG can produce extra correct and contextually related responses.
- Improved Factual Accuracy: Leveraging exterior data sources helps in lowering the probability of producing incorrect data.
- Flexibility: May be utilized to numerous duties, together with query answering, dialogue techniques, and summarization.
Challenges of RAG
- Dependency on Retrieval High quality: The general efficiency is closely depending on the standard of the retrieval step.
- Computational Complexity: Requires environment friendly retrieval mechanisms to deal with large-scale datasets in real-time.
- Protection Gaps: The mixed exterior data base and the mannequin’s parametric data may not all the time be enough to cowl a selected matter, resulting in potential mannequin hallucinations.
- Unoptimized Prompts: Poorly designed prompts can lead to combined outcomes from RAG.
- Irrelevant Retrieval: Situations the place retrieved paperwork don’t include related data can fail to enhance the mannequin’s responses.
Contemplating these limitations, a extra superior strategy referred to as Self-Reflective Retrieval-Augmented Era (Self-RAG) was developed.
What’s Self-RAG?
Self-RAG builds on the rules of RAG by incorporating a self-reflection mechanism to additional refine the retrieval course of and improve the language mannequin’s responses.
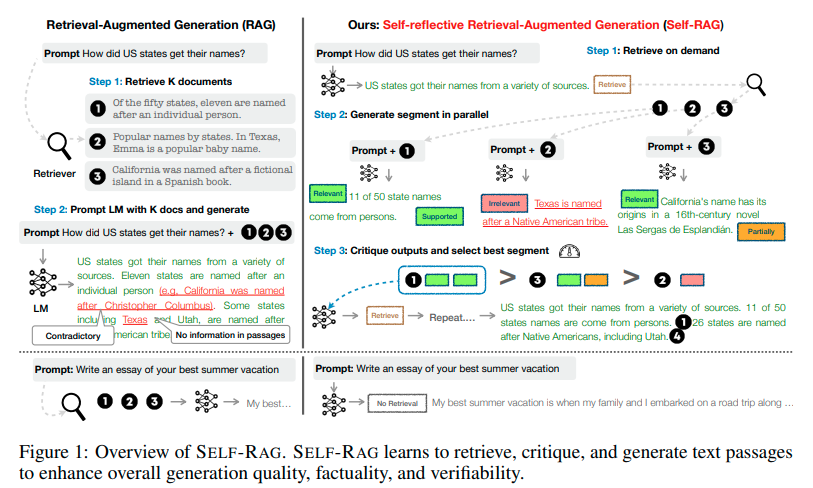
Key Options of Self-RAG
- Adaptive Retrieval: In contrast to RAG’s mounted retrieval routine, Self-RAG makes use of retrieval tokens to evaluate the need of data retrieval. It dynamically determines whether or not to have interaction its retrieval module primarily based on the precise wants of the enter, intelligently deciding whether or not to retrieve a number of occasions or skip retrieval altogether.
- Clever Era: If retrieval is required, Self-RAG makes use of critique tokens like IsRelevant, IsSupported, and IsUseful to evaluate the utility of the retrieved paperwork, making certain the generated responses are knowledgeable and correct.
- Self-Critique: After producing a response, Self-RAG self-reflects to judge the general utility and factual accuracy of the response. This step ensures that the ultimate output is best structured, extra correct, and enough.
Benefits of Self-RAG
- Larger High quality Responses: Self-reflection permits the mannequin to determine and proper its personal errors, resulting in extra polished and correct outputs.
- Continuous Studying: The self-critique course of helps the mannequin to enhance over time by studying from its personal evaluations.
- Better Autonomy: Reduces the necessity for human intervention within the refinement course of, making it extra environment friendly.
Comparability Abstract
- Mechanism: Each RAG and Self-RAG use retrieval and era, however Self-RAG provides a critique and refinement step.
- Efficiency: Self-RAG goals to supply greater high quality responses by iteratively bettering its outputs by means of self-reflection.
- Complexity: Self-RAG is extra complicated as a result of extra self-reflection mechanism, which requires extra computational energy and superior methods.
- Use Instances: Whereas each can be utilized in related purposes, Self-RAG is especially helpful for duties requiring excessive accuracy and high quality, comparable to complicated query answering and detailed content material era.
By integrating self-reflection, Self-RAG takes the RAG framework a step additional, aiming to boost the standard and reliability of AI-generated content material.
Overview of the Chatbot Utility
On this tutorial, we might be implementing a chatbot powered with Retrieval Augmented Era. Within the curiosity of time, we are going to solely make the most of conventional RAG and observe the standard of responses generated by the mannequin. We’ll maintain the Self-RAG implementation and the comparisons between conventional RAG and self-RAG for a future workshop.
We’ll be producing embeddings for a PDF referred to as Microsoft’s annual report with a view to create an exterior data base linked to our LLM to implement RAG structure. Afterward, we’ll create a Question Lambda on Rockset that handles the vectorization of textual content representing the data within the report and retrieval of the matched vectorized section(s) of the doc(s) along side the enter person question. On this tutorial, we’ll be utilizing GPT-4 as our LLM and implementing a perform in Python to attach retrieved data with GPT-4 and generate responses.
Steps to construct the RAG-Powered Chatbot utilizing Rockset and OpenAI Embedding
Step 1: Producing Embeddings for a PDF File
The next code makes use of Openai’s embedding mannequin together with Python’s ‘pypdf library to interrupt the content material of the PDF file into chunks and generate embeddings for these chunks. Lastly, the textual content chunks are saved together with their embeddings in a JSON file for later.
from openai import OpenAI
import json
from pypdf import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
shopper = OpenAI(api_key="sk-************************")
def get_embedding(textual content):
response = shopper.embeddings.create(
enter=[text],
mannequin="text-embedding-3-small"
)
embedding = response.information[0].embedding
return embedding
reader = PdfReader("/content material/microsoft_annual_report_2022.pdf")
pdf_texts = [p.extract_text().strip() for p in reader.pages if p.extract_text()]
character_splitter = RecursiveCharacterTextSplitter(
separators=["nn", "n"],
chunk_size=1000,
chunk_overlap=0
)
character_split_texts = character_splitter.split_text('nn'.be part of(pdf_texts))
data_for_json = []
for i, chunk in enumerate(character_split_texts, begin=1):
embedding = get_embedding(chunk) # Use OpenAI API to generate embedding
data_for_json.append({
"chunk_id": str(i),
"textual content": chunk,
"embedding": embedding
})
# Writing the structured information to a JSON file
with open("chunks_with_embeddings.json", "w") as json_file:
json.dump(data_for_json, json_file, indent=4)
print(f"Whole chunks: {len(character_split_texts)}")
print("Embeddings generated and saved in chunks_with_embeddings.json")
Step 2: Create a brand new Assortment and Add Knowledge
To get began on Rockset, sign-up without cost and get $300 in trial credit. After making the account, create a brand new assortment out of your Rockset console. Scroll to the underside and select File Add underneath Pattern Knowledge to add your information.

You will be directed to the next web page. Click on on Begin.

Click on on the file Add button and navigate to the file you need to add. We’ll be importing the JSON file created in step 1 i.e. chunks_with_embeddings.json. Afterward, you can overview it underneath Supply Preview.
Notice: In observe, this information may come from a streaming service, a storage bucket in your cloud, or one other linked service built-in with Rockset. Study extra concerning the connectors supplied by Rockset right here.

Now, you may be directed to the SQL transformation display to carry out transformations or function engineering as per your wants.
As we do not need to apply any transformation now, we’ll transfer on to the subsequent step by clicking Subsequent.

Now, the configuration display will immediate you to decide on your workspace together with the Assortment Title and several other different assortment settings.
It’s best to title the gathering after which proceed with default configurations by clicking Create.

Ultimately, your assortment might be arrange. Nevertheless, there could also be a delay earlier than the Ingest Standing switches from Initializing to Related.
After the standing has been up to date, you need to use Rockset’s question device to entry the gathering by means of the Question this Assortment button situated within the top-right nook of the picture under.

Step 3: Producing Question Lambda on Rockset
Question lambda is an easy parameterized SQL question that’s saved in Rockset so it may be executed from a devoted REST endpoint after which utilized in numerous purposes. To be able to present clean data retrieval on the run to the LLM, we’ll configure the Question Lambda with the next question:
SELECT
chunk_id,
textual content,
embedding,
APPROX_DOT_PRODUCT(embedding, VECTOR_ENFORCE(:query_embedding, 1536, 'float')) as similarity
FROM
workshops.external_data d
ORDER BY similarity DESC
LIMIT :restrict;
This parameterized question calculates the similarity utilizing APPROXDOTPRODUCT between the embeddings of the PDF file and a question embedding supplied as a parameter query_embedding.
We will discover probably the most related textual content chunks to a given question embedding with this question whereas permitting for environment friendly similarity search throughout the exterior information supply.
To construct this Question Lambda, question the gathering made in step 2 by clicking on Question this assortment and pasting the parameterized question above into the question editor.

Subsequent, add the parameters one after the other to run the question earlier than saving it as a question lambda.


Click on on Save within the question editor and title your question lambda to make use of it from endpoints later.

Every time this question is executed, it’ll return the chunk_id, textual content, embedding, and similarity for every document, ordered by the similarity in descending order whereas the LIMIT clause will restrict the whole variety of outcomes returned.
If you would like to know extra about Question lambdas, be happy to learn this weblog put up.
Step 4: Implementing RAG-based chatbot with Rockset Question Lambda
We’ll be implementing two features retrieve_information and rag with the assistance of Openai and Rockset APIs. Let’s dive into these features and perceive their performance.
- Retrieve_information
This perform queries the Rockset database utilizing an API key and a question embedding generated by means of Openai’s embedding mannequin. The perform connects to Rockset, executes a pre-defined question lambda created in step 2, and processes the outcomes into a listing object.
import rockset
from rockset import *
from rockset.fashions import *
rockset_key = os.environ.get('ROCKSET_API_KEY')
area = Areas.usw2a1
def retrieve_information( area, rockset_key, search_query_embedding):
print("nRunning Rockset Queries...")
rs = RocksetClient(api_key=rockset_key, host=area)
api_response = rs.QueryLambdas.execute_query_lambda_by_tag(
workspace="workshops",
query_lambda="chatbot",
tag="newest",
parameters=[
{
"name": "embedding",
"type": "array",
"value": str(search_query_embedding)
}
]
)
records_list = []
for document in api_response["results"]:
record_data = {
"textual content": document['text']
}
records_list.append(record_data)
return records_list
- RAG
The rag perform makes use of Openai’s chat.completions.create to generate a response the place the system is instructed to behave as a monetary analysis assistant. The retrieved paperwork from retrieve_information are fed into the mannequin together with the person’s authentic question. Lastly, the mannequin then generates a response that’s contextually related to the enter paperwork and the question thereby implementing an RAG move.
from openai import OpenAI
shopper = OpenAI()
def rag(question, retrieved_documents, mannequin="gpt-4-1106-preview"):
messages = [
{
"role": "system",
"content": "You are a helpful expert financial research assistant. You will be shown the user's question, and the relevant information from the annual report. Respond according to the provided information"
},
{"role": "user", "content": f"Question: {query}. n Information: {retrieved_documents}"}
]
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=messages,
)
content material = response.selections[0].message.content material
return content material
Step 5: Setting Up Streamlit for Our Chatbot
To make our chatbot accessible, we’ll wrap the backend functionalities right into a Streamlit software. Streamlit supplies a hassle-free front-end interface, enabling customers to enter queries and obtain responses immediately by means of the net app.
The next code snippet might be used to create a web-based chatbot utilizing Streamlit, Rockset, and OpenAI’s embedding mannequin. Here is a breakdown of its functionalities:
- Streamlit Tittle and Subheader: The code begins organising the webpage configuration with the title “RockGPT” and a subheader that describes the chatbot as a “Retrieval Augmented Era primarily based Chatbot utilizing Rockset and OpenAI“.
- Consumer Enter: It prompts customers to enter their question utilizing a textual content enter field labeled “Enter your question:“.
-
Submit Button and Processing:
- When the person presses the ‘Submit‘ button, the code checks if there’s any person enter.
- If there’s enter, it proceeds to generate an embedding for the question utilizing OpenAI’s embeddings.create perform.
- This embedding is then used to retrieve associated paperwork from a Rockset database by means of the getrsoutcomes perform.
-
Response Era and Show:
- Utilizing the retrieved paperwork and the person’s question, a response is generated by the rag perform.
- This response is then displayed on the webpage formatted as markdown underneath the header “Response:“.
- No Enter Dealing with: If the Submit button is pressed with none person enter, the webpage prompts the person to enter a question.
import streamlit as st
# Streamlit UI
st.set_page_config(page_title="RockGPT")
st.title("RockGPT")
st.subheader('Retrieval Augmented Era primarily based Chatbot utilizing Rockset and OpenAI',divider="rainbow")
user_query = st.text_input("Enter your question:")
if st.button('Submit'):
if user_query:
# Generate an embedding for the person question
embedding_response = shopper.embeddings.create(enter=user_query, mannequin="text-embedding-3-small")
search_query_embedding = embedding_response.information[0].embedding
# Retrieve paperwork from Rockset primarily based on the embedding
records_list = get_rs_results(area, rockset_key, search_query_embedding)
# Generate a response primarily based on the retrieved paperwork
response = rag(user_query, records_list)
# Show the response as markdown
st.markdown("**Response:**")
st.markdown(response)
else:
st.markdown("Please enter a question to get a response.")
Here is how our Streamlit software will initially seem within the browser:

Beneath is the entire code snippet for our Streamlit software, saved in a file named app.py. This script does the next:
- Initializes the OpenAI shopper and units up the Rockset shopper utilizing API keys.
- Defines features to question Rockset with the embeddings generated by OpenAI, and to generate responses utilizing the retrieved paperwork.
- Units up a easy Streamlit UI the place customers can enter their question, submit it, and examine the chatbot’s response.
import streamlit as st
import os
import rockset
from rockset import *
from rockset.fashions import *
from openai import OpenAI
# Initialize OpenAI shopper
shopper = OpenAI()
# Set your Rockset API key right here or fetch from surroundings variables
rockset_key = os.environ.get('ROCKSET_API_KEY')
area = Areas.usw2a1
def get_rs_results(area, rockset_key, search_query_embedding):
"""
Question the Rockset database utilizing the supplied embedding.
"""
rs = RocksetClient(api_key=rockset_key, host=area)
api_response = rs.QueryLambdas.execute_query_lambda_by_tag(
workspace="workshops",
query_lambda="chatbot",
tag="newest",
parameters=[
{
"name": "embedding",
"type": "array",
"value": str(search_query_embedding)
}
]
)
records_list = []
for document in api_response["results"]:
record_data = {
"textual content": document['text']
}
records_list.append(record_data)
return records_list
def rag(question, retrieved_documents, mannequin="gpt-4-1106-preview"):
"""
Generate a response utilizing OpenAI's API primarily based on the question and retrieved paperwork.
"""
messages = [
{"role": "system", "content": "You are a helpful expert financial research assistant. You will be shown the user's question, and the relevant information from the annual report. Respond according to the provided information."},
{"role": "user", "content": f"Question: {query}. n Information: {retrieved_documents}"}
]
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=messages,
)
return response.selections[0].message.content material
# Streamlit UI
st.set_page_config(page_title="RockGPT")
st.title("RockGPT")
st.subheader('Retrieval Augmented Era primarily based Chatbot utilizing Rockset and OpenAI',divider="rainbow")
user_query = st.text_input("Enter your question:")
if st.button('Submit'):
if user_query:
# Generate an embedding for the person question
embedding_response = shopper.embeddings.create(enter=user_query, mannequin="text-embedding-3-small")
search_query_embedding = embedding_response.information[0].embedding
# Retrieve paperwork from Rockset primarily based on the embedding
records_list = get_rs_results(area, rockset_key, search_query_embedding)
# Generate a response primarily based on the retrieved paperwork
response = rag(user_query, records_list)
# Show the response as markdown
st.markdown("**Response:**")
st.markdown(response)
else:
st.markdown("Please enter a question to get a response.")
Now that all the pieces is configured, we will launch the Streamlit software and question the report utilizing RAG, as proven within the image under:

By following the steps outlined on this weblog put up, you have discovered the best way to arrange an clever chatbot or search assistant able to understanding and responding successfully to your queries.
Do not cease there—take your tasks to the subsequent degree by exploring the wide selection of purposes potential with RAG, comparable to superior question-answering techniques, conversational brokers and chatbots, data retrieval, authorized analysis and evaluation instruments, content material suggestion techniques, and extra.
Cheers!!!