
That is half 1 of a weblog collection the place we glance again on the main areas of progress for Databricks SQL in 2023, and in our first submit we’re specializing in efficiency. Efficiency for an information warehouse is essential as a result of it makes for a extra responsive person expertise and higher value/efficiency, particularly within the fashionable SaaS world the place compute time drives value. Now we have been working onerous to ship the following set of efficiency developments for Databricks SQL whereas lowering the necessity for guide tuning by using AI.
AI-optimized Efficiency
Trendy knowledge warehouses are stuffed with workload-specific configurations that must be manually tuned by a educated administrator on a steady foundation as new knowledge, extra customers or new use instances are available. These “knobs” vary from how knowledge is bodily saved to how compute is utilized and scaled. Over the previous yr, we’ve got been making use of AI to take away these efficiency and administrative knobs in alignment with Databricks’ imaginative and prescient for a Information Intelligence Platform:
- Serverless Compute is the inspiration for Databricks SQL, offering the perfect efficiency with immediate and elastic compute that lowers prices and lets you deal with delivering essentially the most worth to your corporation moderately than managing infrastructure.
- Predictive I/O eliminates efficiency tuning like indexing by intelligently prefetching knowledge utilizing neural networks. It additionally achieves quicker writes utilizing merge-on-read strategies with out efficiency tradeoffs. Early prospects have benefited from a outstanding 35x enchancment in level lookup effectivity, spectacular efficiency boosts of 2-6x for MERGE operations and 2-10x for DELETE operations.
- Automated knowledge format intelligently optimizes file sizes to offer the perfect efficiency robotically based mostly on question patterns. This self-manages value and efficiency.
- Outcomes caching improves question outcome caching by utilizing a two-tier system with an area cache and a persistent distant cache throughout all serverless warehouses in a workspace. These caching mechanisms are robotically managed based mostly on the question necessities and obtainable sources.
- Predictive Optimization (public preview, weblog) Databricks will seamlessly optimize file sizes and clustering by operating OPTIMIZE, VACUUM, ANALYZE and CLUSTERING instructions for you. With this function, Anker Improvements benefited from a 2.2x increase to question efficiency whereas delivering 50% financial savings on storage prices.
- Liquid Clustering (public preview, weblog): robotically and intelligently adjusts the information format as new knowledge is available in based mostly on clustering keys. This avoids over- or under-partitioning issues that may happen and ends in as much as 2.5x quicker clustering relative to Z-order.
These improvements have enabled us to make important advances in efficiency with out growing complexity for the person or prices.
Continued Class-leading Efficiency and Value Effectivity for ETL Workloads
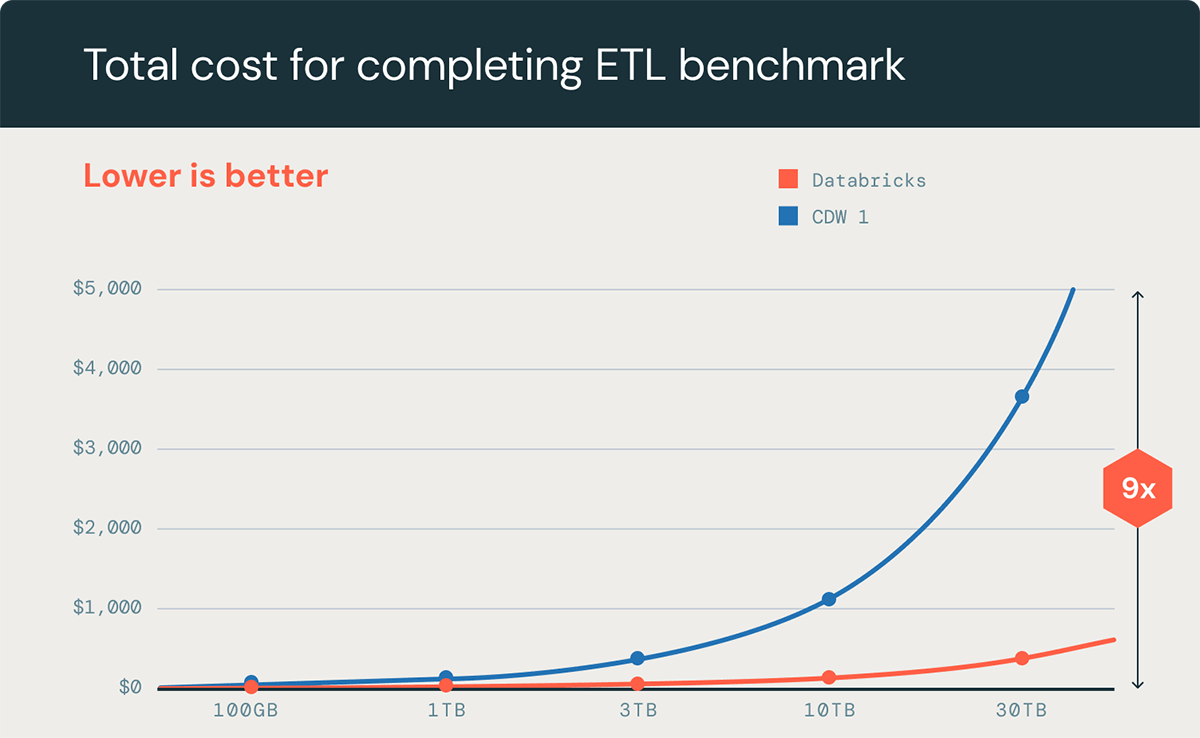
Databricks SQL has lengthy been a frontrunner when it comes to efficiency and value effectivity for ETL workloads. Our funding in AI-powered options, corresponding to Predictive IO, helps maintain that management place and improve value benefits as knowledge volumes proceed to develop. That is evident in our processing of ETL workloads the place Databricks SQL has as much as a 9x value benefit vs. main trade competitors (see benchmark beneath).
Delivering Low-Latency Efficiency with Class-Main Concurrency for BI
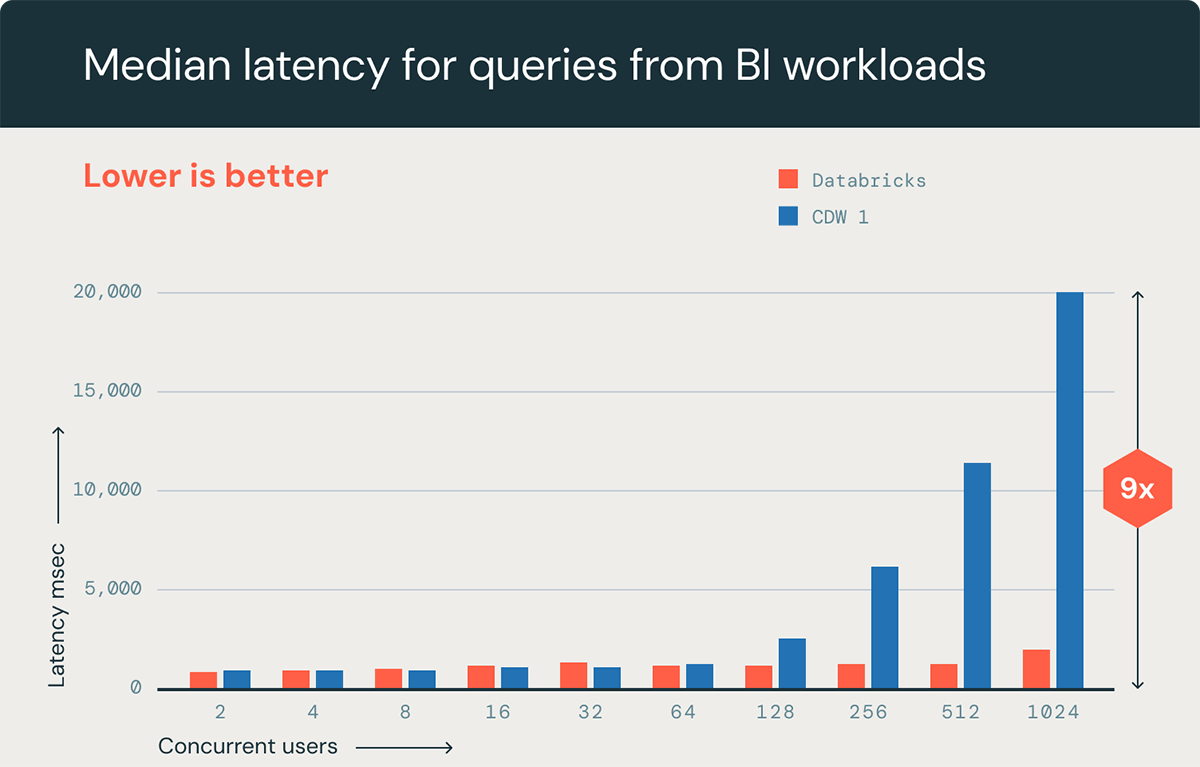
Databricks SQL now matches main trade competitors on low-latency question efficiency for smaller numbers of concurrent customers (< 100) and has 9x higher efficiency because the variety of concurrent customers grows to over one thousand (see benchmark beneath). Serverless compute may also begin a warehouse in a number of seconds proper when wanted, creating substantial value financial savings that avoids operating clusters on a regular basis or performing guide shutdowns. When the workload demand lowers, SQL Serverless robotically downscales clusters or shuts down the warehouse to maintain prices low.
The Method Ahead with AI-optimized Information Warehousing
Databricks SQL has unified governance, a wealthy ecosystem of your favourite instruments, and open codecs and APIs to keep away from lock-in — all a part of why the perfect knowledge warehouse is a lakehouse. If you wish to migrate your SQL workloads to a cost-optimized, high-performance, serverless and seamlessly unified fashionable structure, Databricks SQL is the answer. Speak to your Databricks consultant to get began on a proof-of-concept as we speak and expertise the advantages firsthand. Our crew is prepared that can assist you consider if Databricks SQL is the correct alternative that can assist you innovate quicker along with your knowledge.
To be taught extra about how we obtain best-in-class efficiency on Databricks SQL utilizing AI-driven optimizations, watch Reynold Xin’s keynote and Databricks SQL Serverless Beneath the Hood: How We Use ML to Get the Greatest Value/Efficiency from the Information+AI Summit.