

Have you ever ever questioned how huge enterprise and shopper apps deal with that sort of scale with concurrent customers? To deploy high-performance purposes at scale, a rugged operational database is important. Cloudera Operational Database (COD) is a high-performance and extremely scalable operational database designed for powering the largest information purposes on the planet at any scale. Powered by Apache HBase and Apache Phoenix, COD ships out of the field with Cloudera Knowledge Platform (CDP) within the public cloud. It’s additionally multi-cloud prepared to fulfill your enterprise the place it’s as we speak, whether or not AWS, Microsoft Azure, or GCP.
Assist for cloud storage is a vital functionality of COD that, along with the pre-existing help for HDFS on native storage, presents a alternative of worth efficiency traits to the purchasers.
To know how COD delivers one of the best cost-efficient efficiency to your purposes, let’s dive into benchmarking outcomes evaluating COD utilizing cloud storage vs COD on premises.
Take a look at Setting:
The efficiency comparability was achieved to measure the efficiency variations between COD utilizing storage on Hadoop Distributed File System (HDFS) and COD utilizing cloud storage. We examined for 2 cloud storages, AWS S3 and Azure ABFS. These efficiency measurements have been achieved on COD 7.2.15 runtime model.
The efficiency benchmark was achieved to measure the next facets:
- Learn-write workloads
- Learn solely workloads
The next configuration was used to setup a sidecar cluster:
- Runtime model: 7.2.15
- Variety of employee nodes: 10
The cluster working with HBase on cloud storage was configured with a mixed bucket cache dimension throughout the cluster as 32TB, with L2 bucket cache configured to make use of file-based cache storage on ephemeral storage volumes of 1.6TB capability every. We ensured that this bucket cache was warmed up virtually fully, i.e. all of the areas on all of the area servers have been learn into the bucket cache. That is achieved routinely at any time when the area servers are began.
All of the checks have been run utilizing YCSB benchmarking device on COD with the next configurations:
- Amazon AWS
- COD Model: 1.22
- CDH: 7.2.14.2
- Apache HBase on HDFS
- No. of grasp nodes: 2 (m5.8xlarge)
- No. of chief nodes: 1 (m5.2xlarge)
- No. of gateway nodes: 1 (m5.2xlarge)
- No. of employee nodes: 20 (m5.2xlarge) (Storage as HDFS with HDD)
- Apache HBase on S3
- No. of grasp nodes: 2 (m5.2xlarge)
- No. of chief nodes: 1 (m5.2xlarge)
- No. of gateway nodes: 1 (m5.2xlarge)
- No. of employee nodes: 20 (i3.2xlarge) (Storage as S3)
- Microsoft Azure
- Apache HBase on HDFS
- No. of grasp nodes: 2 (Standard_D32_V3)
- No. of chief nodes: 1 (Standard_D8_V3)
- No. of gateway nodes: 1 (Standard_D8_V3)
- No. of employee nodes: 20 (Standard_D8_V3)
- Apache Hbase on ABFS
- No. of grasp nodes: 2 (Standard_D8a_V4)
- No. of chief nodes: 1 (Standard_D8a_V4)
- No. of gateway node: 1 (Standard_D8a_V4)
- No. of employee nodes: 20 (Standard_L8s_V2)
- Apache HBase on HDFS
Right here is a few essential data concerning the take a look at methodology:
- Knowledge dimension
- Desk was loaded from 10 sidecar employee nodes (2 billion rows per sidecar node) onto 20 COD DB cluster employee nodes
- Efficiency benchmarking was achieved utilizing the next YCSB workloads
- YCSB Workload C
- YCSB Workload A
- Replace heavy workload
- 50% learn, 50% write
- YCSB Workload F
- Learn-Modify-Replace workload
- 50% learn, 25% replace, 25% read-modify-update
The next parameters have been used to run the workloads utilizing YCSB:
- Every workload was run for 15 min (900 secs)
- Pattern set for working the workloads
- 1 billion rows
- 100 million batch
- Following components have been thought-about whereas finishing up the next efficiency runs:
- Total CPU exercise was under 5% earlier than beginning the run to make sure no main actions have been ongoing on the cluster
- Area server cache was warmed up (in case of Amazon AWS, with S3 and in case of Microsoft Azure, with ABFS) to the total capability making certain most quantity of information was in cache
- No different actions like main compaction have been occurring on the time of beginning the workloads
Vital findings
The take a look at began by loading 20TB of information right into a COD cluster working HBase on HDFS. This load was carried out utilizing the ten node sidecar on the 20 node COD cluster working HBase on HDFS. Subsequently, a snapshot of this loaded information was taken and restored to the opposite COD clusters working HBase on Amazon S3 and Microsoft Azure ABFS. The next observations have been made throughout this exercise:
- Loading occasions = 52 hrs
- Snapshot time
- Cluster to cluster = ~70 min
- Cluster to cloud storage = ~70 min
- Cloud storage to cluster = ~3hrs
Key takeaways
The next desk exhibits the throughput noticed on working the efficiency benchmarks:

Based mostly on the information proven above, we made the next observations:
- Total, the typical efficiency was higher for a S3 primarily based cluster with ephemeral cache by an element of 1.7x as in comparison with HBase working on HDFS on HDD.
- Learn throughput for S3 primarily based cluster is best by round 1.8x for each HBase and Phoenix as in comparison with the HDFS primarily based cluster.
- Some components that have an effect on the efficiency of S3 are:
- Cache warming on S3: The cache needs to be warmed as much as its capability to get one of the best efficiency.
- AWS S3 throttling: With the rising variety of area servers and therefore, the variety of community requests to S3, AWS might throttle some requests for just a few seconds which can have an effect on the general efficiency. These limits are set on AWS assets for every account.
- Non atomic operations: Some operations like transfer do lots of information copy as an alternative of a easy rename and HBase depends closely on these operations.
- Gradual bulk delete operations: For every such operation, the motive force has to carry out a number of operations like itemizing, creating, deleting which ends up in a slower efficiency.
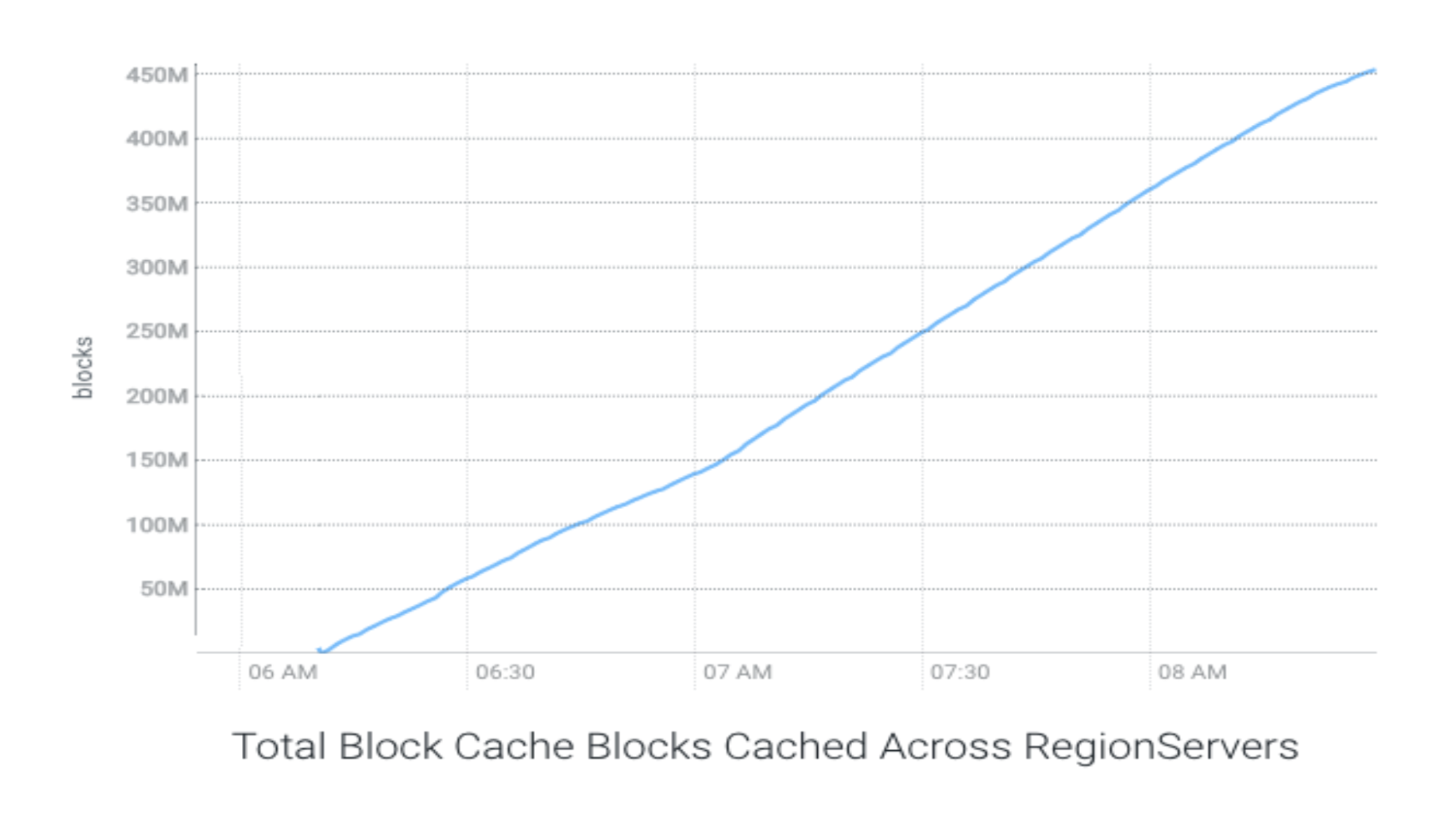
As talked about above, the cache was warmed to its full capability in case of S3 primarily based cluster. This cache warming took round 130 minutes with a median throughput of two.62 GB/s.
The next chart exhibits the cache warming throughput with S3:
The next charts present the throughput and latencies noticed in several run configurations:
The next few charts present comparative illustration of assorted parameters when HBase is working on HDFS as in comparison with HBase working on S3.
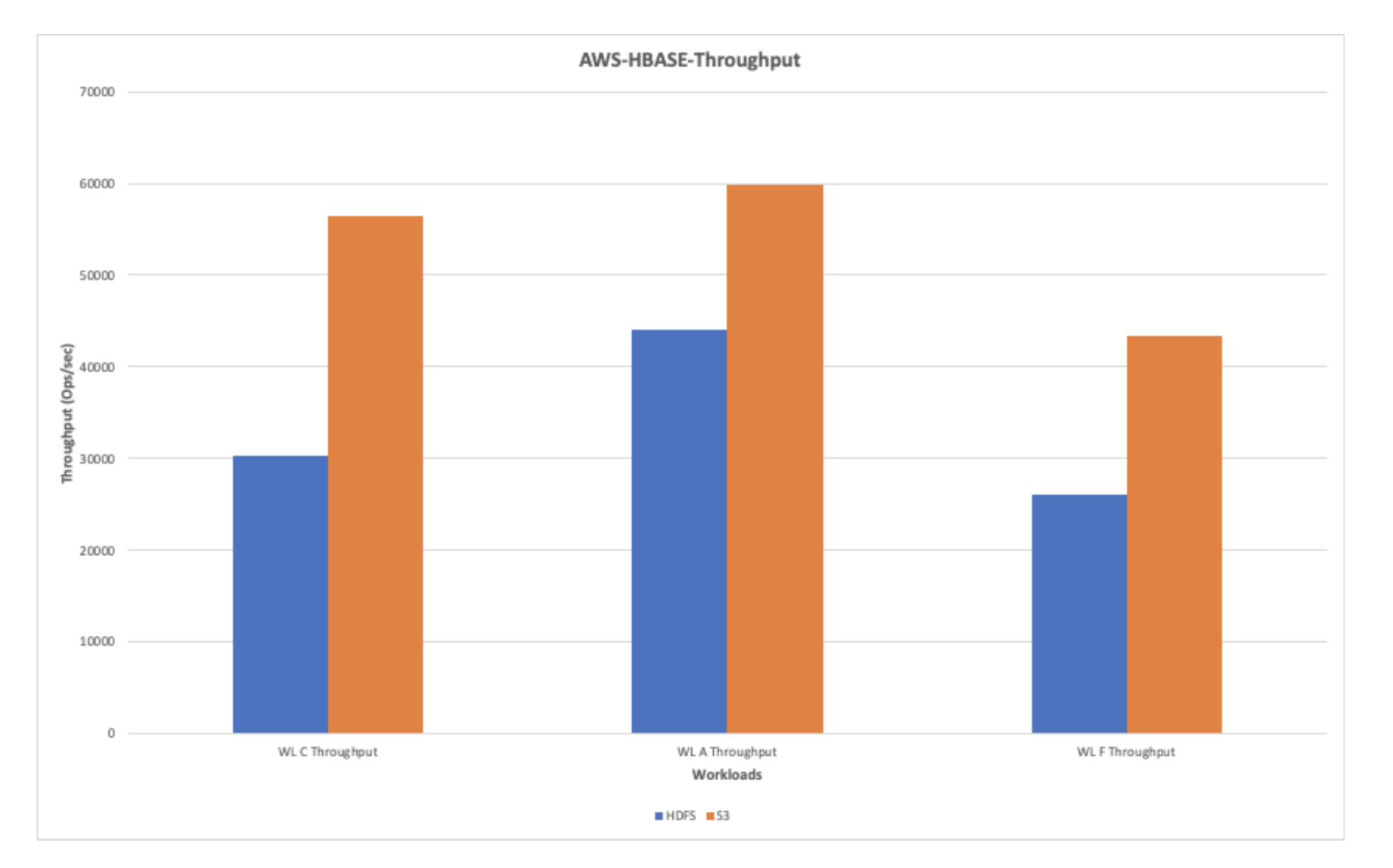
AWS-HBase-Throughput (Ops/sec)
The next chart exhibits the throughput noticed whereas working workloads on HDFS and AWS S3. Total, AWS exhibits a greater throughput efficiency as in comparison with HDFS.
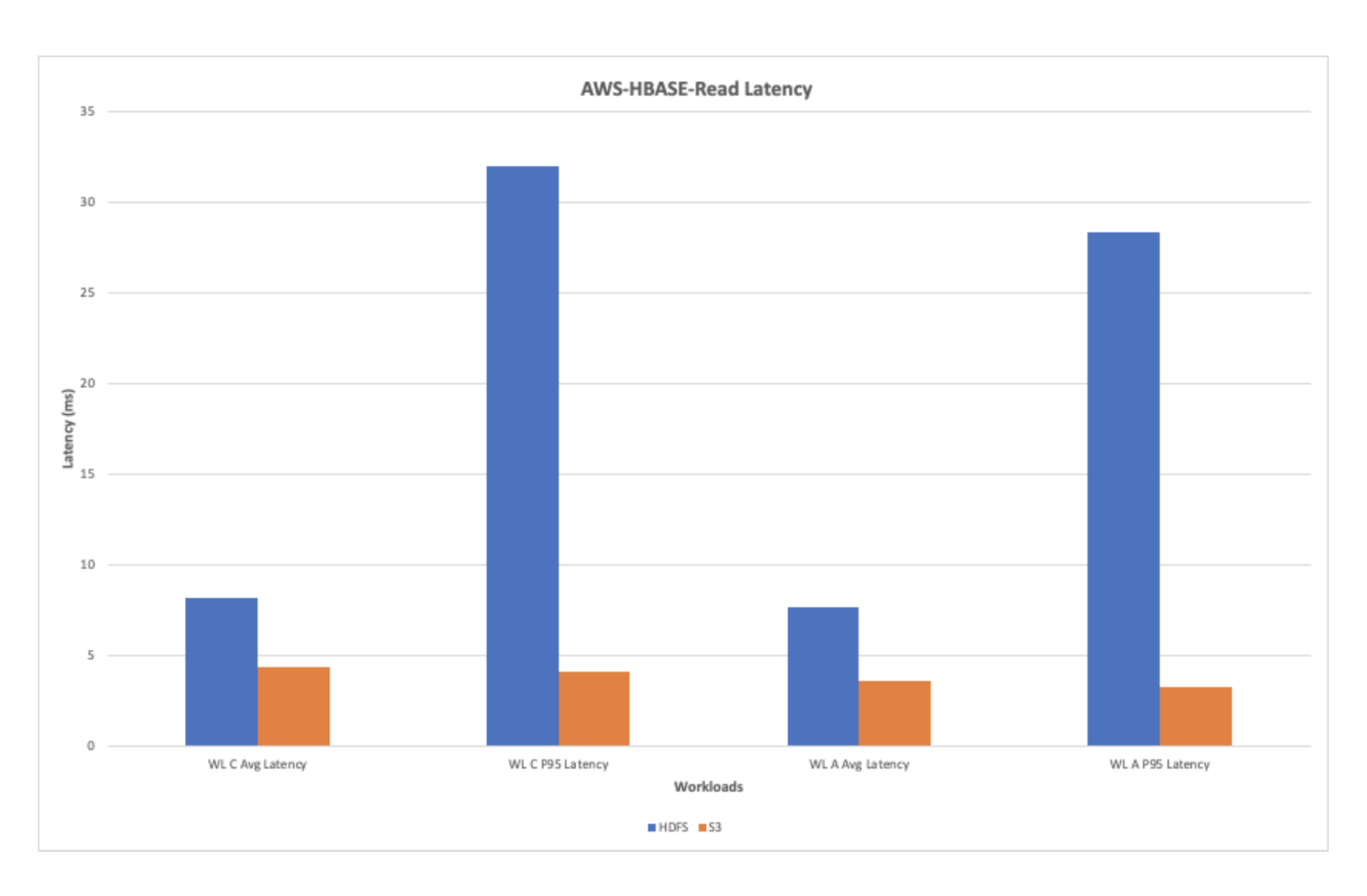
AWS-HBase-Learn Latency
The chart under exhibits the learn latency noticed whereas working the learn workloads. Total, the learn latency is improved with AWS with ephemeral storage when in comparison with the HDFS.
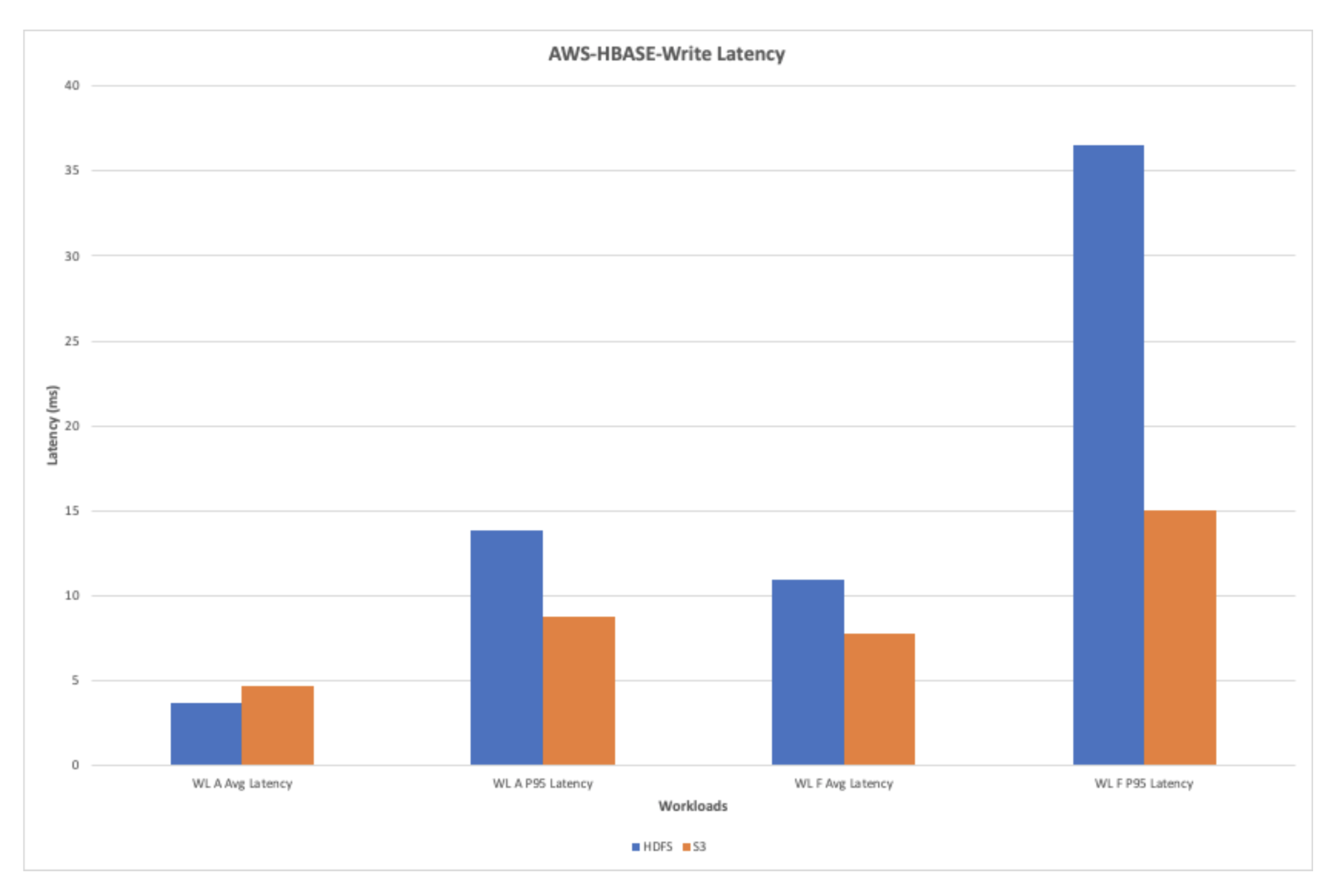
AWS-HBase-Write Latency
The chart under exhibits the write latency noticed whereas working the workloads A and F. The S3 exhibits an general enchancment within the write latency in the course of the write heavy workloads.
The checks have been additionally run to match the efficiency of Phoenix when run with HBase working on HDFS as in comparison with HBase working on S3. The next charts present the efficiency comparability of some key indicators.
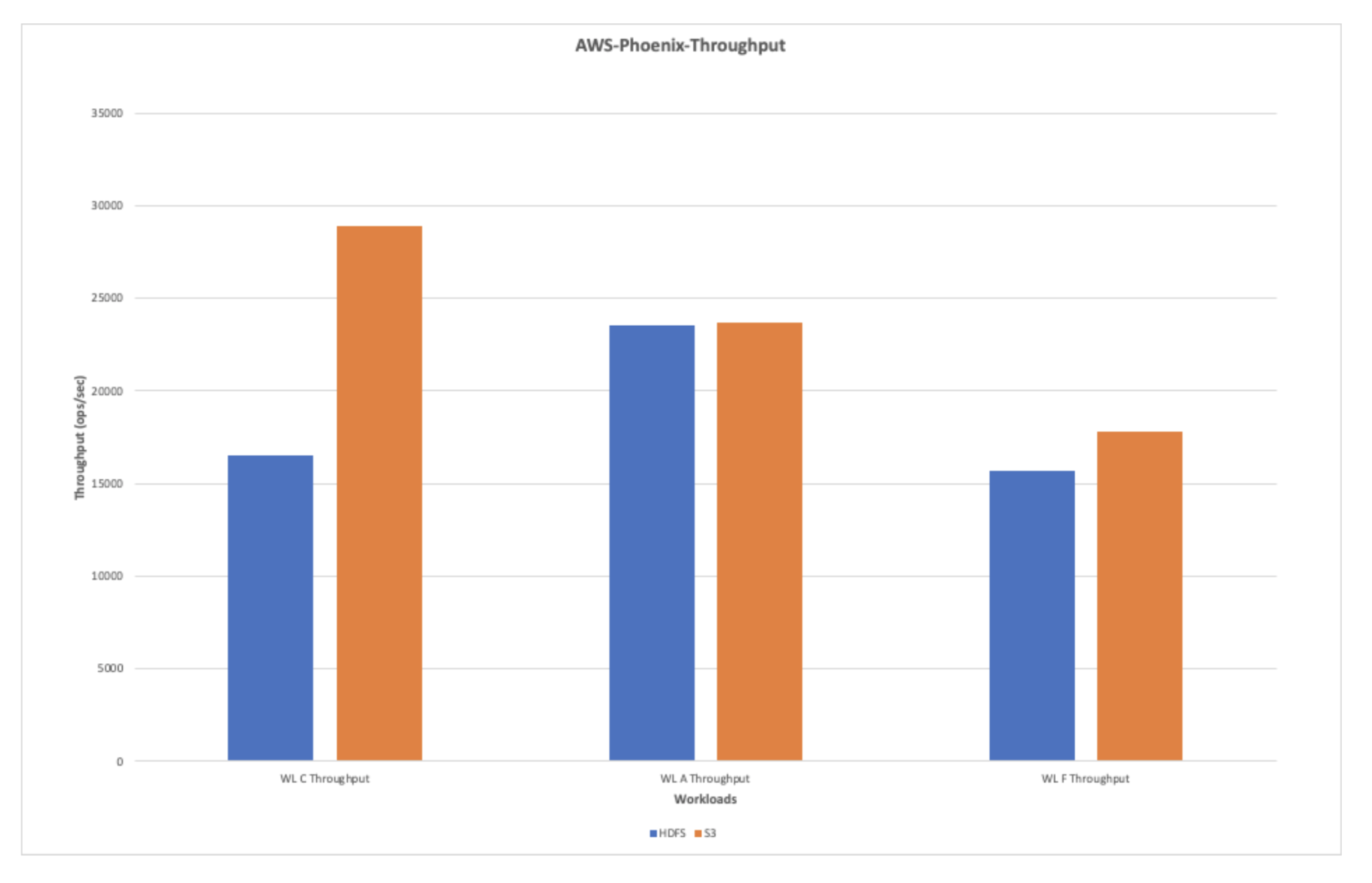
AWS-Phoenix-Throughput(ops/sec)
The chart under exhibits the typical throughput when the workloads have been run with Phoenix in opposition to HDFS and S3. The general learn throughput is discovered to be higher than the write throughput in the course of the checks.
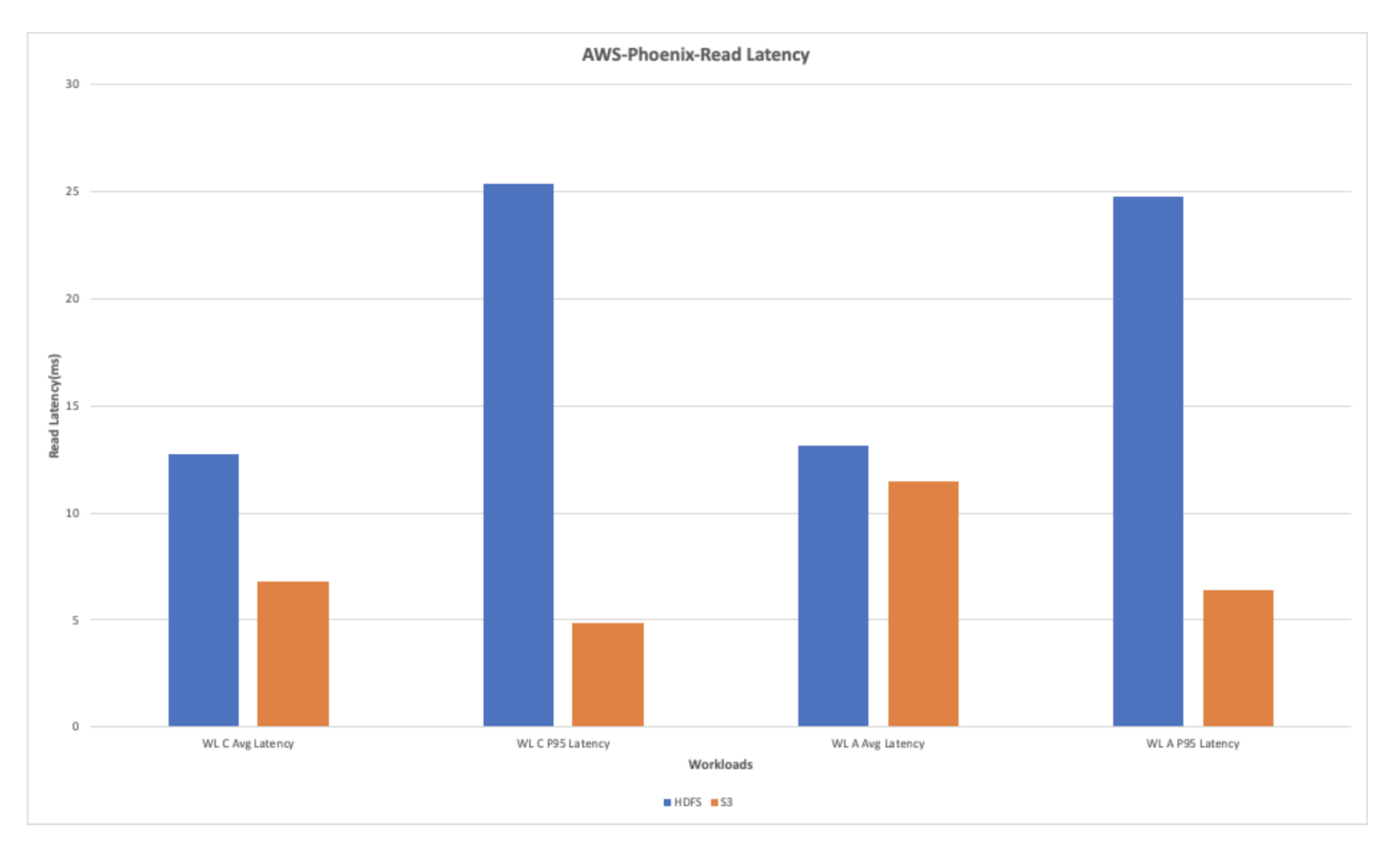
AWS-Phoenix Learn Latency
The general learn latency for the learn heavy workloads exhibits enchancment when utilizing S3. The chart under exhibits that the learn latency noticed with S3 is best by multifold when put next with the latency noticed whereas working the workloads on HDFS.
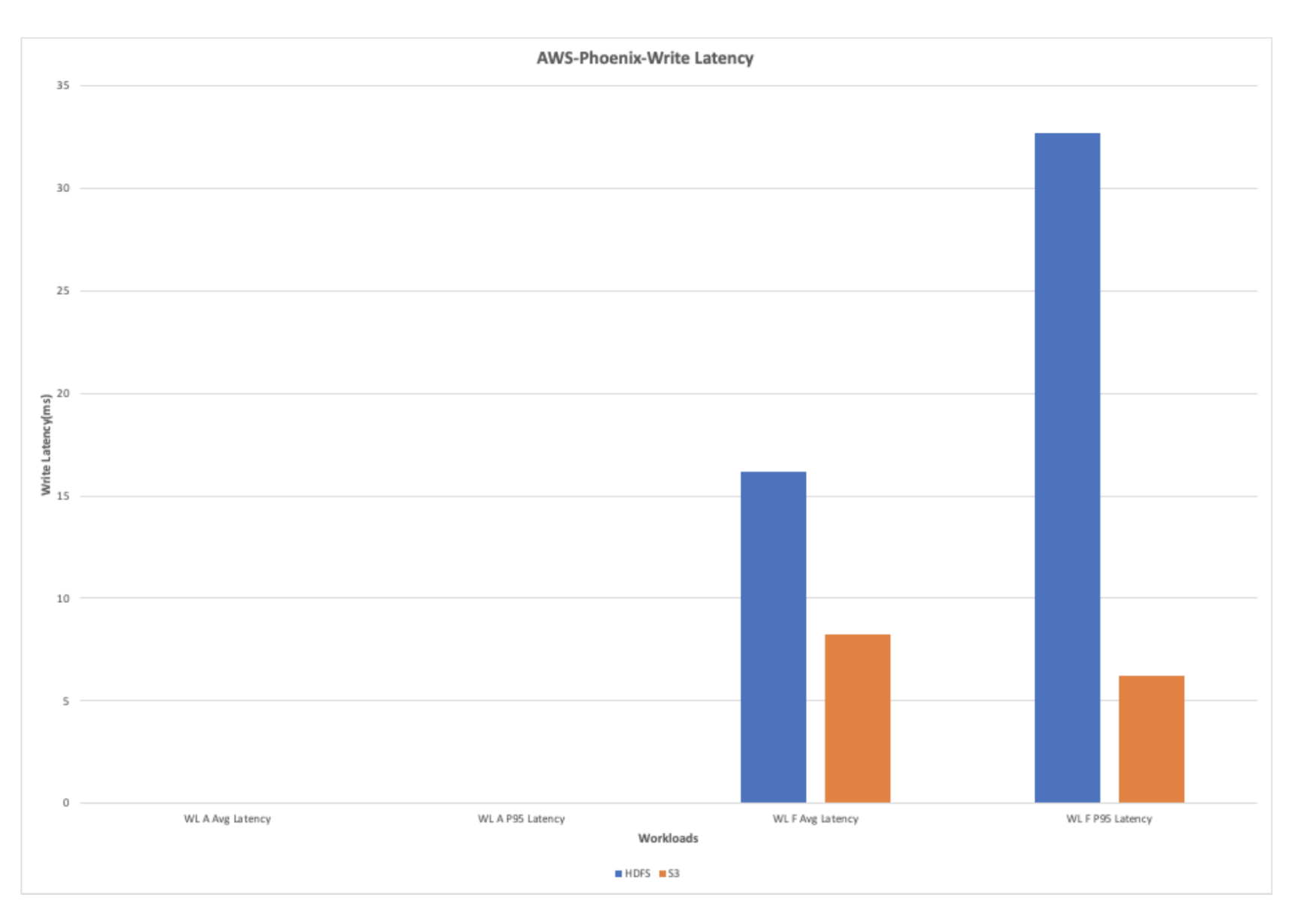
AWS-Phoenix-Write Latency
The write heavy workload exhibits large enchancment within the efficiency due to the decreased write latency in S3 when in comparison with HDFS.
Azure
The efficiency measurements have been additionally carried out on HBase working on Azure ABFS storage and the outcomes have been in contrast with HBase working on HDFS. The next few charts present the comparability of key efficiency metrics when HBase is working on HDFS vs. HBase working on ABFS.
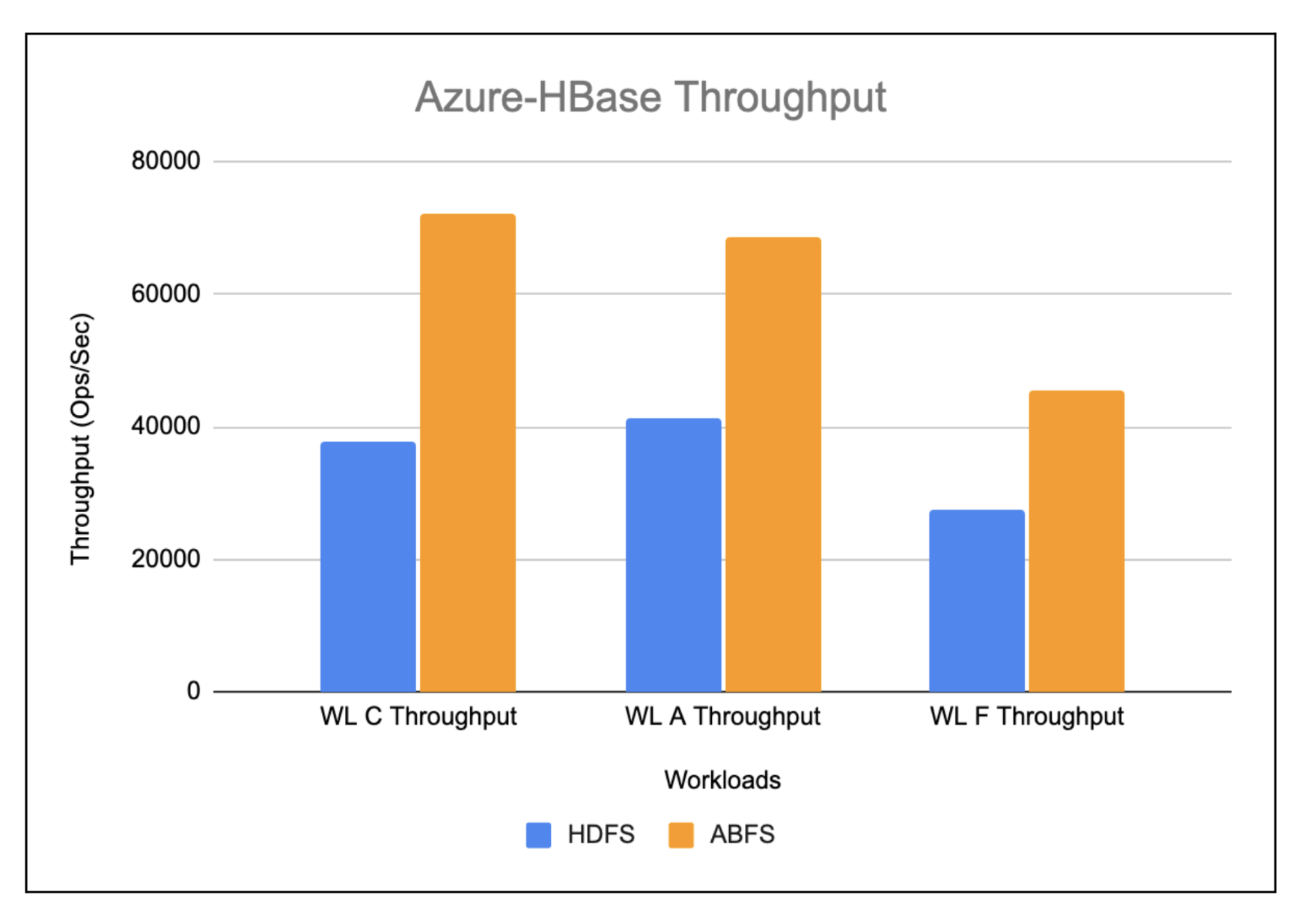
Azure-HBase-Throughput(ops/sec)
The workloads working on HBase ABFS present virtually 2x enchancment when in comparison with HBase working on HDFS as depicted within the chart under.
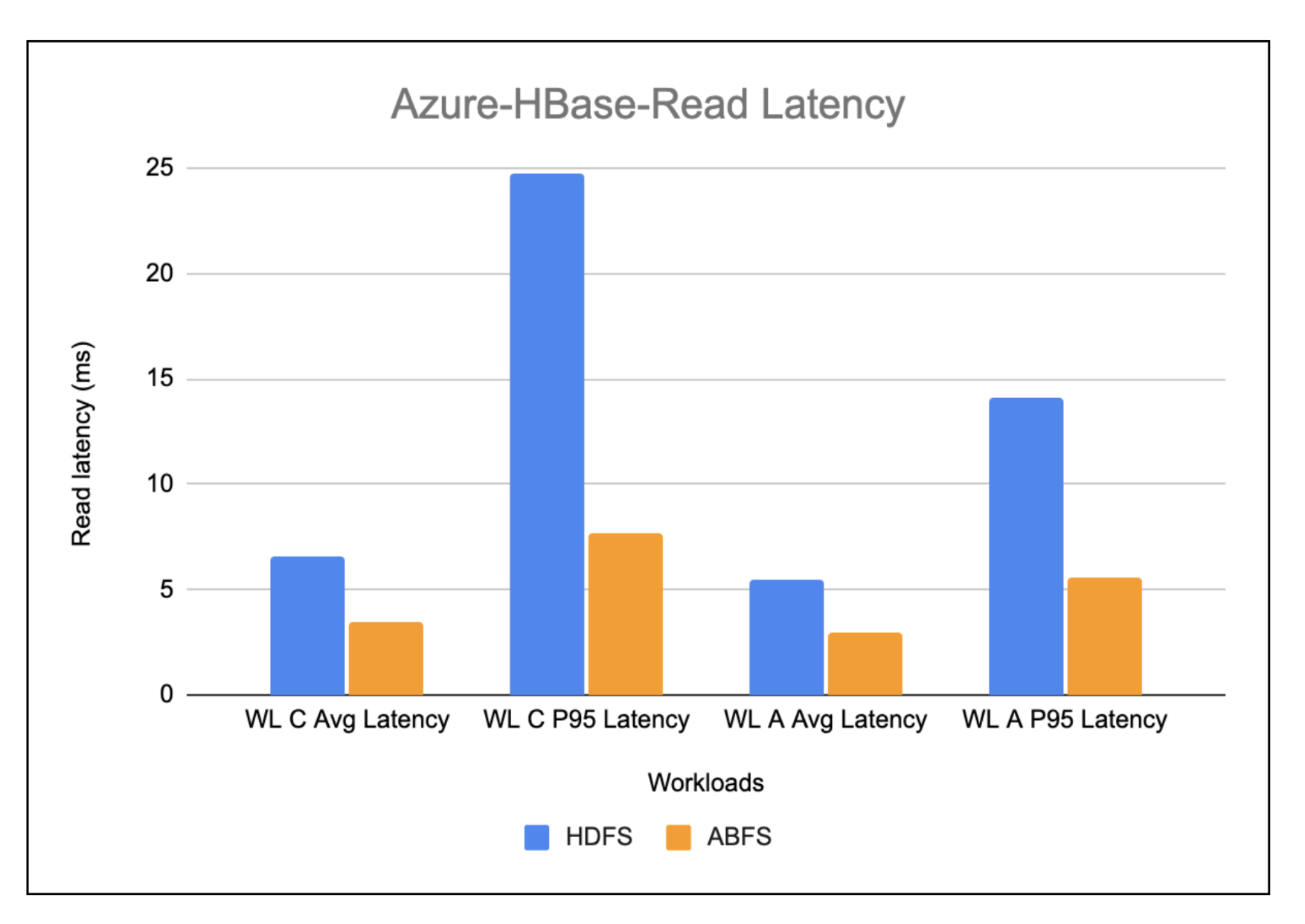
Azure-Hbase-Learn Latency
The chart under exhibits the learn latency noticed whereas working the learn heavy workloads on HBase working on HDFS vs. HBase working on ABFS. Total, the learn latency in HBase working on ABFS is discovered to be greater than 2x higher when in comparison with HBase working on HDFS.
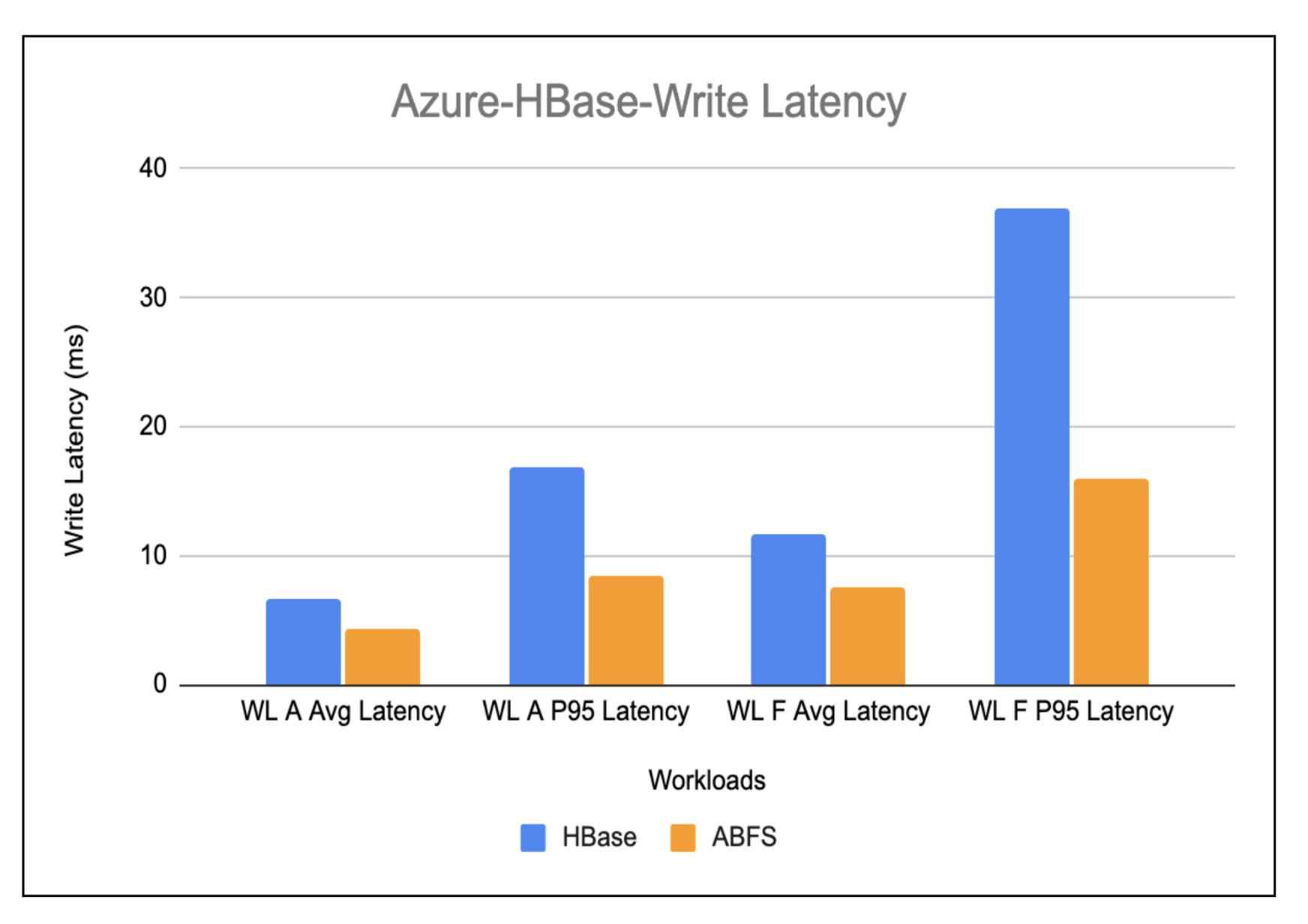
Azure-Hbase-Write Latency
The write-heavy workload outcomes proven within the under chart present an enchancment of virtually 1.5x within the write latency in HBase working on ABFS as in comparison with HBase working on HDFS.
Issues to think about when choosing the proper COD deployment atmosphere for you
- Cache warming whereas utilizing cloud storage
- After the preliminary creation of the cluster, a warming-up course of is initiated for the cache. This course of entails fetching information from cloud storage to progressively populate the cache. Consequently, the cluster’s responsiveness to queries would possibly expertise a short lived slowdown throughout this era. This slowdown is primarily resulting from queries needing to entry cloud storage for uncached blocks immediately, all whereas contending with the cache inhabitants for CPU assets.
The period of this warming-up section sometimes falls throughout the vary of three to 5 hours for a cluster configured with 1.5TB of cache per employee. This preliminary section ensures optimized efficiency as soon as the cache is totally populated and the cluster is working at its peak effectivity.
The inherent latency linked with such storage options is predicted to trigger slowness in retrieving information from cloud storage. And likewise, every entry ends in incurring a price. Nevertheless, the cloud storage’s built-in throttling mechanism stands as one other important issue that impacts efficiency and resilience. This mechanism confines the variety of allowed calls per second per prefix. Exceeding this restrict ends in unattended requests, with the potential consequence of halting cluster operations.
On this situation, cache warming takes on a pivotal position in avoiding such conditions. By proactively populating the cache with the information, the cluster can bypass a reliance on frequent and probably throttled storage requests.
- Non-atomic operations
- Operations inside cloud storage lack atomicity, as seen in circumstances like renames in S3. To handle this limitation, HBase has carried out a retailer file monitoring mechanism which minimizes the need for such operations within the essential path, successfully eliminating the dependency on these operations.
Conclusion
The desk under exhibits the full price of possession (TCO) for a cluster working COD on S3 with out ephemeral cache (DR situation) and with ephemeral cache (manufacturing situation) as in contrast with a cluster working COD on HDFS.
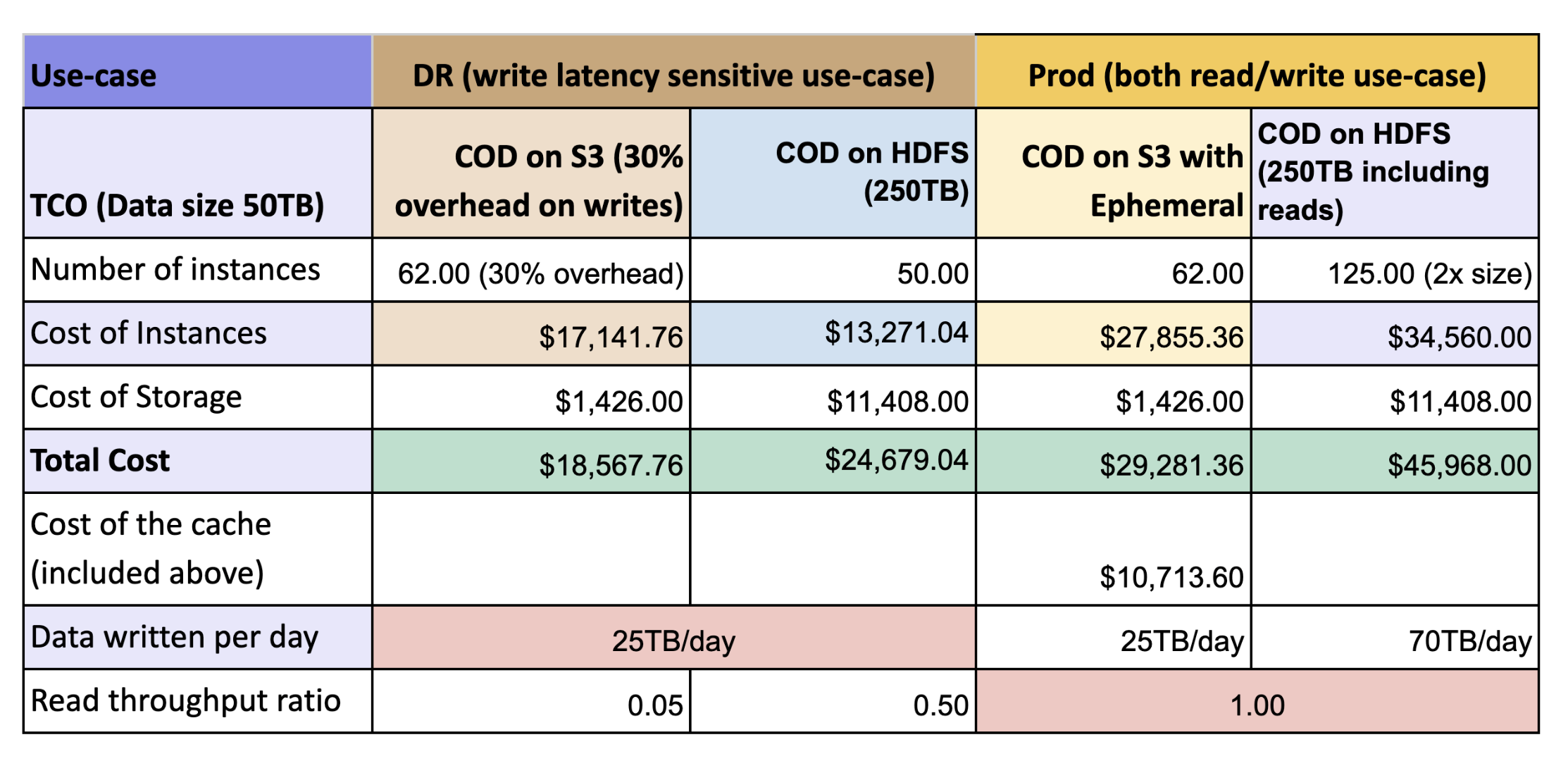
We noticed that the general throughput of HBase with cloud storages with bucket cache is best than HBase working on HDFS with HDD. Right here’s some highlights:
- With cached warm-up, cloud storage with cache yields 2x higher efficiency with low TCO as in comparison with HDFS. The efficiency with cloud storage is attributed to native cache primarily based on SSD the place HDFS utilizing costlier EBS-HDD requires 3 times of storage to account for replication.
- Write efficiency is predicted to be identical as each type components makes use of HDFS as the bottom for WAL however as we’re flushing and caching the information on the identical time there’s some 30% influence was seen
DR Cluster: This cluster is devoted to catastrophe restoration efforts and sometimes handles write operations from much less essential purposes. Leveraging cloud storage with out native storage to help cache, customers can count on to attain roughly 25% price financial savings in comparison with an HDFS-based cluster.
Prod Cluster: Serving as the first cluster, this atmosphere features because the definitive supply of reality for all learn and write actions generated by purposes. By using cloud storage resolution with native storage to help cache, customers can notice a considerable 40% discount in prices
Go to the product web page to study extra about Cloudera Operational Database or attain out to your account staff.