
Within the quickly evolving discipline of synthetic intelligence, the event and software of enormous language fashions (LLMs) stand on the forefront of innovation, providing unparalleled knowledge processing and evaluation capabilities. These refined fashions, characterised by their huge parameter areas, have demonstrated distinctive proficiency in varied duties, from pure language processing to advanced problem-solving. Nonetheless, the deployment of LLMs has challenges, notably when balancing computational effectivity and sustaining high-performance ranges. The crux of the matter lies within the inherent trade-off: leveraging the complete energy of LLMs typically requires substantial computational assets, which might be each pricey and time-consuming.
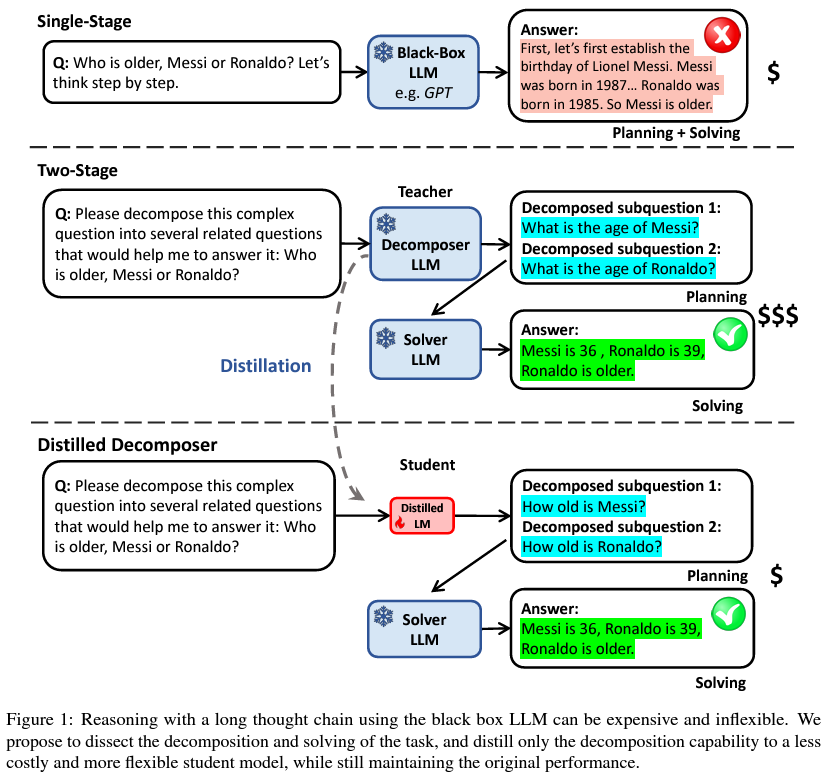
Recognizing this, researchers from the College of Michigan and tech big Apple launched into an formidable mission to refine the utilization of LLMs, particularly concentrating on the mannequin’s effectivity with out sacrificing its effectiveness. Their progressive method facilities on distillation, a course of designed to streamline the mannequin’s operations by specializing in two essential phases of activity execution: downside decomposition and problem-solving. The essence of their technique lies within the speculation that downside decomposition—the preliminary part the place advanced duties are damaged down into less complicated subtasks—might be distilled into smaller, extra manageable fashions with larger ease in comparison with the problem-solving part.
To check this speculation, the analysis group performed a collection of experiments to distill the decomposition functionality of LLMs into smaller fashions. This concerned separating the decomposition activity from the general problem-solving course of, permitting for a focused optimization of this preliminary part. The outcomes of their efforts had been compelling: not solely did the distilled decomposition fashions retain a excessive stage of efficiency throughout varied duties and datasets, however additionally they achieved this with considerably lowered computational calls for. In sensible phrases, this interprets to a less expensive and environment friendly use of LLMs, enabling quicker inference occasions with out compromising on the standard of outcomes.
A better examination of the efficiency metrics additional underscores the effectiveness of the distilled fashions. The analysis group noticed that the decomposed fashions demonstrated exceptional generalization capabilities of their experiments, performing constantly nicely throughout completely different duties and datasets. Particularly, the distilled fashions achieved a efficiency stage that carefully mirrored that of their bigger LLM counterparts however with a notable discount in inference prices. As an example, in duties associated to mathematical reasoning and query answering, the distilled fashions maintained efficiency ranges whereas considerably slicing down on the computational assets required.
This breakthrough analysis, spearheaded by the collaboration between the College of Michigan and Apple, marks a big development in synthetic intelligence. By efficiently distilling the decomposition part of LLMs into smaller fashions, the group has opened up new avenues for the environment friendly and efficient use of those highly effective instruments. Their findings not solely spotlight the potential for price financial savings and elevated accessibility to LLM know-how but additionally set the stage for additional exploration into optimizing LLMs for varied functions.
This work presents a compelling case for the focused distillation of LLM capabilities as a viable technique for enhancing mannequin effectivity. The implications of such an method are far-reaching, promising to speed up the adoption and software of LLMs throughout a broad spectrum of industries and analysis domains. As the sphere continues to evolve, the insights gained from this mission will undoubtedly contribute to the continued dialogue on how greatest to leverage the immense potential of enormous language fashions in a manner that’s each sustainable and impactful.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Overlook to affix our Telegram Channel
You may additionally like our FREE AI Programs….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible functions. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.