
We’re excited to announce the Normal Availability of Delta Lake Liquid Clustering within the Databricks Information Intelligence Platform. Liquid Clustering is an modern information administration method that replaces desk partitioning and ZORDER so that you not should fine-tune your information format to obtain optimum question efficiency.
Liquid clustering considerably simplifies information layout-related selections and gives the pliability to redefine clustering keys with out information rewrites. It permits information format to evolve alongside analytic wants over time – one thing you would by no means do with partitioning on Delta.
For the reason that Public Preview of Liquid Clustering on the Information and AI Summit final yr, we’ve labored with tons of of shoppers who benefited from higher question efficiency with Liquid Clustering. Throughout that point, we have now 1000+ energetic prospects, and have written 100+ petabytes to and learn practically 20 exabytes from Liquid clustered tables. Prospects have seen Liquid enhance learn efficiency by 2-12x in comparison with conventional strategies.
Conventional approaches: exhausting to handle, minimal flexibility, no one-size-fits-all technique
Historically, prospects adopted a mix of hive-style partitioning + ZORDERing to hurry up learn queries and allow concurrent writers. This comes with just a few points:
Problem 1: determining the best partitioning technique for optimum efficiency is tough.
Selecting partitioning columns is a sophisticated course of. And when partition columns are poorly chosen, prospects expertise slower reads and poor question efficiency because of file sizes being too massive, or too small. To handle this, many shoppers resort to much more advanced workarounds, akin to utilizing generated columns to partition by high-cardinality columns.
Problem 2: ZORDERing jobs are costly and require longer write instances.
The ZORDER method ends in sooner reads than solely partitioning, however has important write amplification, as it’s not incremental, and can’t be carried out on-write. This ends in longer working clustering jobs and better compute prices. To make issues worse, ZORDER doesn’t optimize the info globally throughout all the dataset, stopping optimum question efficiency.
Problem 3: Partitioning methods are restricted by the necessity to concurrently write to the desk.
To stop conflicts, partitions are structured round columns that don’t essentially want partitioning. This results in ongoing upkeep, adjusting partitions with information rewrites as question patterns evolve with enterprise modifications. Furthermore, concurrent writes inside the similar partition aren’t attainable.
Introducing Liquid Clustering – self-tuning out-of-the-box efficiency that improves question efficiency by as much as 12x
Liquid Clustering is a breakthrough method that solves all these challenges by determining the best information format for you, delivering higher write and browse efficiency to manually tuned partitioned tables. Liquid is obtainable in Delta Lake and is now typically obtainable in Databricks from DBR 15.2. Inside Databricks, as a part of the Databricks Information Intelligence Platform, DatabricksIQ makes use of AI to supercharge Liquid with further concurrency and efficiency enhancements.
Utilizing Liquid is straightforward – merely outline the columns you need to cluster by:
-- Creating a brand new desk
CREATE TABLE table1(t timestamp, s string) CLUSTER BY (t);Profit 1: Liquid is straightforward – optimum clustering efficiency with minimal information format selections
In contrast to Hive partitioning, Liquid clustering keys might be chosen purely primarily based on question entry patterns, with no want to think about cardinality, key order, file dimension, potential information skew, and the way entry patterns would possibly change sooner or later. Within the instance above, we’re utilizing timestamp, a high-cardinality column, as our clustering key. Liquid is self-tuning and skew-resistant, producing constant file sizes, and avoiding over- and under-partitioning.
Utilizing Databricks modern Liquid Clustering, we have now noticed outstanding enhancements in question efficiency in comparison with the standard z-order strategies. Moreover, Liquid clustered tables have streamlined our information processing by eliminating partitioning bottlenecks, enhancing scanning, and lowering information skews.
— Edward Goo, Director of ETL Engineering, YipitData
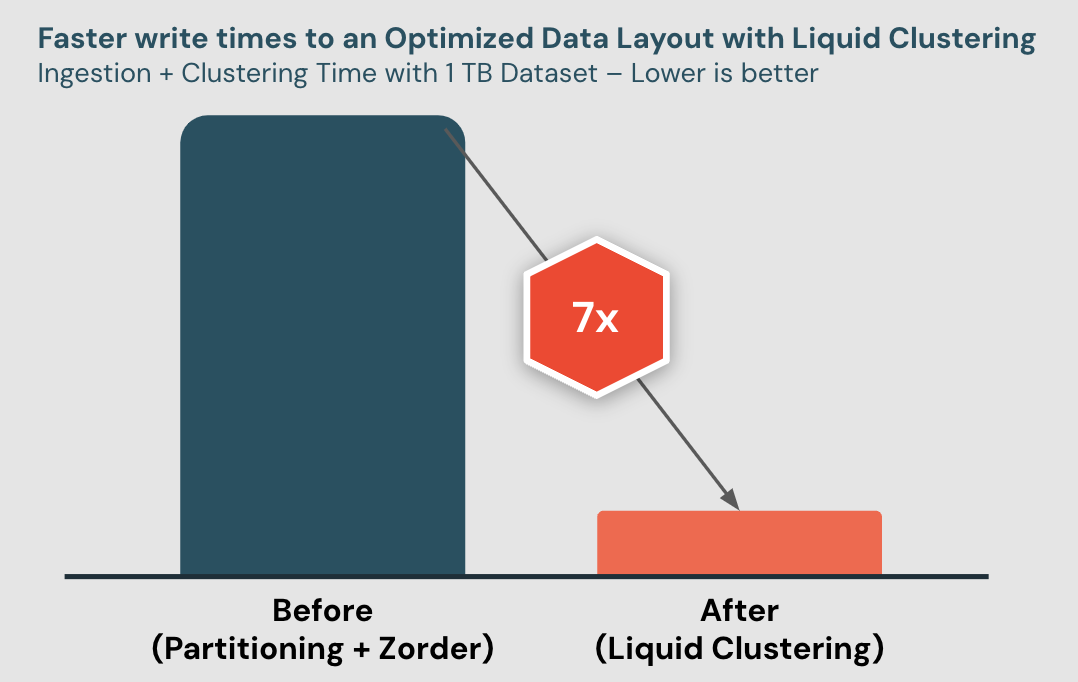
Profit 2: Writing to Liquid clustered tables is quick – optimized information layouts for decrease prices
Liquid gives cost-effective incremental clustering with low write amplification. We see that Liquid achieves 7x sooner write instances than partitioning + Zorder, in our inner benchmarks the place we incrementally ingested and clustered information from an industry-standard information warehousing datasets.
Furthermore, utilizing DatabricksIQ, we are able to apply Liquid Clustering on the write time (clustering-on-write) on new information throughout ingestion. Clustering-on-write kicks in mechanically with no further configuration. Much like partitioning, Liquid ensures that information in all fairness well-clustered instantly on write, making a performant information format for purchasers out-of-the-box.
Profit 3: Concurrency Ensures – DatabricksIQ gives record-level concurrency help with Liquid clustering
Databricks is the one lakehouse that gives row-level concurrency. Prospects not should depend on partitioning for concurrency or design their workloads to keep away from conflicts on Liquid clustered tables.
With all these advantages, prospects not should fine-tune their information format simply to squeeze out efficiency. A big manufacturing agency noticed Liquid dashing up level queries by 12x, accelerating their use instances of trying up IDs in time sequence information.
Delta Lake Liquid Clustering improved our time sequence queries as much as 10x and was remarkably easy to implement on our Lakehouse. It permits us to cluster on columns with out worrying about cardinality or file dimension and considerably reduces the quantity of information it must learn – one thing we have now at all times needed to handle ourselves with Delta partitioning and z-order fine-tuning.
— Bryce Bartmann, Chief Digital Expertise Advisor, Shell
As well as, many shoppers have praised the aptitude’s simplicity, flexibility, and out-of-the-box efficiency.
Liquid clustering has significantly improved the power of our researchers to research advanced datasets for particular traits and occasions. We stay up for watching this function develop and be adopted as a key function of the Delta ecosystem.
— Robert Batts, Massive Information Lead, Cisco
Get began as we speak
You possibly can allow Liquid Clustering in seconds in your Delta tables. Liquid Clustering is GA’ed in DBR 15.2. (documentation: AWS | Azure | GCP). For utilizing Liquid Clustering exterior of Databricks, please consult with delta.io documentation.