
This publish is the second a part of our two-part sequence on the most recent efficiency enhancements of stateful pipelines. The primary a part of this sequence is roofed in Efficiency Enhancements for Stateful Pipelines in Apache Spark Structured Streaming – we advocate studying the primary half earlier than studying this publish.
Within the Venture Lightspeed replace weblog, we supplied a high-level overview of the assorted efficiency enhancements we have added for stateful pipelines. On this part, we’ll dig deeper into the assorted points we noticed whereas analyzing efficiency and description particular enhancements now we have carried out to deal with these points.
Enhancements within the RocksDB State Retailer Supplier
Reminiscence Administration
RocksDB primarily makes use of reminiscence for memtables, the block cache, and different pinned blocks. Beforehand, all of the updates inside a micro-batch had been buffered in reminiscence utilizing WriteBatchWithIndex. Moreover, customers may solely configure particular person occasion reminiscence limits for write buffer and block cache utilization. This allowed for unbounded reminiscence use on a per-instance foundation, compounding the issue when a number of state retailer situations had been scheduled on a single employee node.
To handle these issues, we now enable customers to implement bounded reminiscence utilization by leveraging the write buffer supervisor function in RocksDB. This allows customers to set a single international reminiscence restrict to manage block cache, write buffer, and filter block reminiscence use throughout state retailer situations on a single executor node. Furthermore, we eliminated the reliance on WriteBatchWithIndex fully in order that updates are not buffered unbounded and as an alternative written on to the database.
Database Write/Flush Efficiency
With the most recent enhancements, we not explicitly want the write forward log (WAL) since all updates are safely written regionally as SST recordsdata and subsequently backed to persistent storage as a part of the checkpoint listing for every micro-batch.
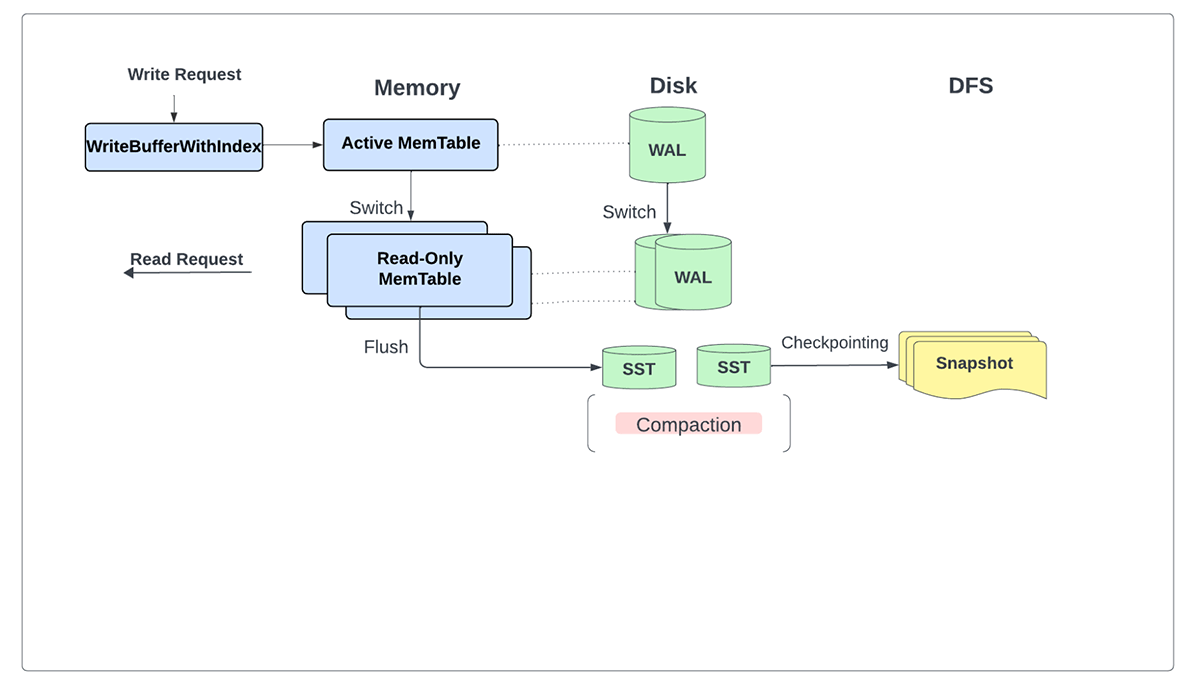
Along with serving all reads and writes primarily from reminiscence, this modification permits us to flush writes to storage periodically when changelog checkpointing is enabled quite than on every micro-batch.
Changelog Checkpointing
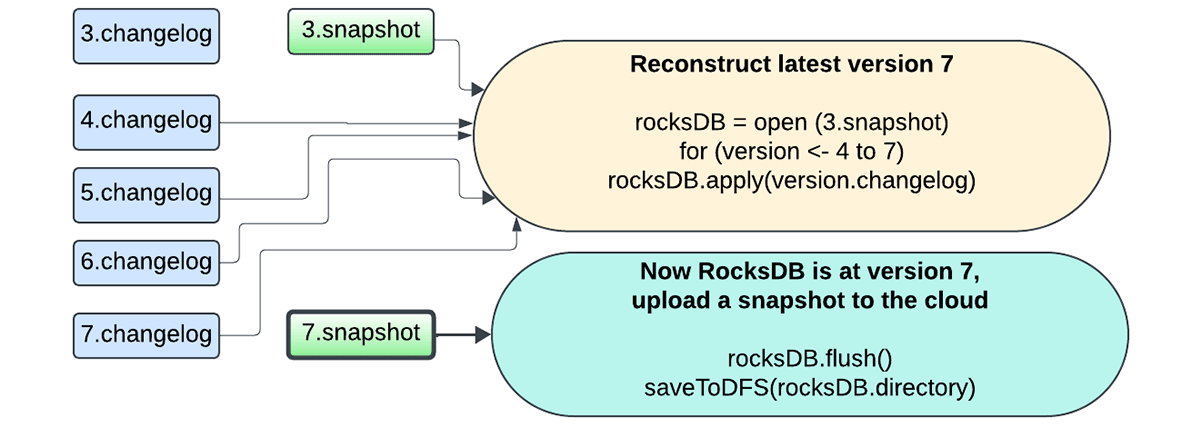
We recognized state checkpointing latency as one of many main efficiency bottlenecks for stateful streaming queries. This latency was rooted within the periodic pauses of RocksDB situations related to background operations and the snapshot creation and add course of that was a part of committing the batch.
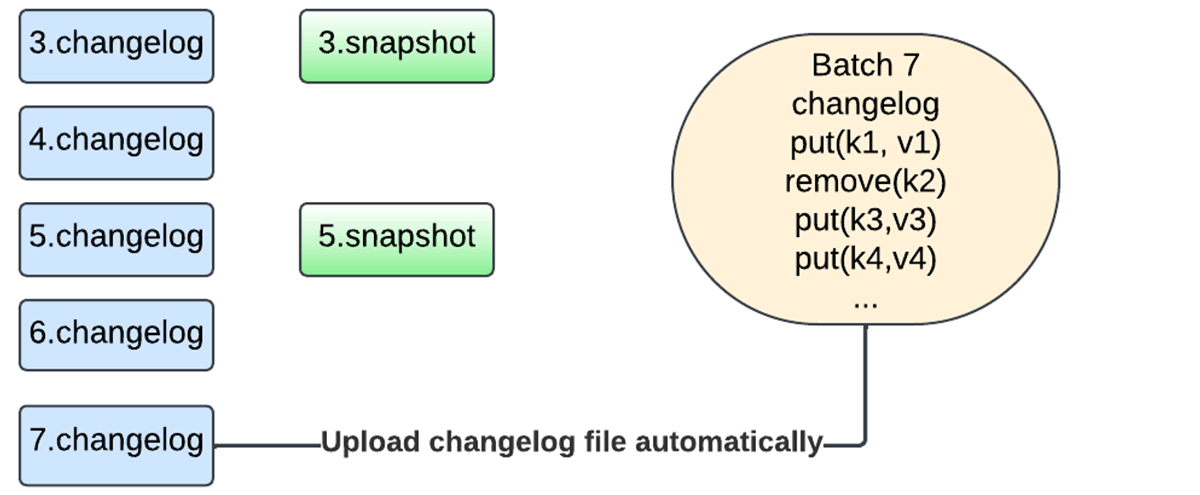
Within the new design, we not must snapshot all the state to the checkpoint location. As a substitute, we at the moment are leveraging changelog checkpointing, which makes the state of a micro-batch sturdy by storing simply the modifications for the reason that final checkpoint on every micro-batch commit.
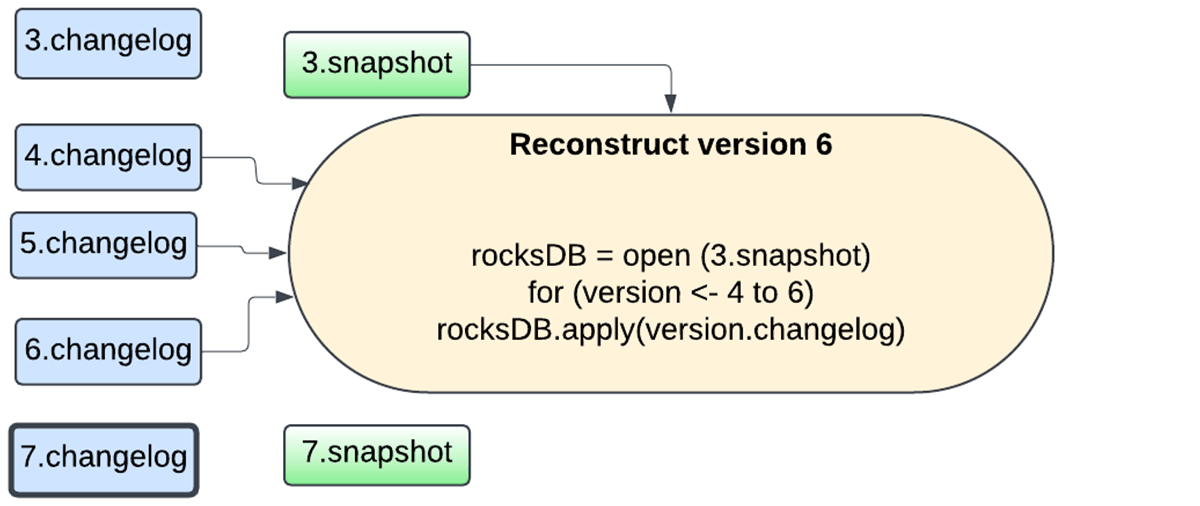
Furthermore, the snapshotting course of is now dealt with by the identical database occasion performing the updates, and the snapshots are uploaded asynchronously utilizing the background upkeep activity to keep away from blocking activity execution. The person now has the pliability of configuring the snapshot interval to commerce off between failure restoration and useful resource utilization. Any model of the state could be reconstructed by selecting a snapshot and replaying changelogs created after that snapshot. This permits for sooner state checkpointing with the RocksDB state retailer supplier.
The next sequence of figures captures how the brand new mechanism works.
Sink-Particular Enhancements
As soon as a stateful operation is full, its state is saved to the state shops by calling commit. When the state has been saved efficiently, the partition information (the executor’s slice of the information) needs to be written to the sink. The executor communicates with the output commit coordinator on the driving force to make sure no different executor has dedicated outcomes for that very same slice of information. The commit can solely undergo after confirming that no different executors have dedicated to this partition; in any other case, the duty will fail with an exception.
This implementation resulted in some undesired RPC delays, which we decided might be bypassed simply for sinks that solely present “at-least-once” semantics. Within the new implementation, now we have eliminated this synchronous step for all DataSource V2 (DSv2) sinks with at-least-once semantics, resulting in improved latency. Be aware that end-to-end exactly-once pipelines use a mix of replayable sources and idempotent sinks, for which the semantic ensures stay unchanged.
Operator-Particular and Upkeep Job Enhancements
As a part of Venture Lightspeed, we additionally made enhancements for particular forms of operators, resembling stream-stream be part of queries. For such queries, we now help parallel commits of state shops for all situations related to a partition, thereby enhancing latency.
One other set of enhancements now we have made is expounded to the background upkeep activity, primarily chargeable for snapshotting and cleansing up the expired state. If this activity fails to maintain up, giant numbers of delta/changelog recordsdata may accumulate, resulting in slower replay. To keep away from this, we now help performing the deletions of expired states in parallel and likewise working the upkeep activity as a part of a thread pool in order that we’re not bottlenecked on a single thread servicing all loaded state retailer situations on a single executor node.
Conclusion
We encourage our prospects to attempt these newest enhancements on their stateful Structured Streaming pipelines. As a part of Venture Lightspeed, we’re centered on enhancing the throughput and latency of all streaming pipelines at decrease TCO. Please keep tuned for extra updates on this space within the close to future!
Availability
All of the options talked about above can be found from the DBR 13.3 LTS launch.