

Posted by Mark Sherwood – Senior Product Supervisor and Juhyun Lee – Workers Software program Engineer

TensorFlow Lite has been a strong instrument for on-device machine studying since its launch in 2017, and MediaPipe additional prolonged that energy in 2019 by supporting full ML pipelines. Whereas these instruments initially targeted on smaller on-device fashions, right now marks a dramatic shift with the experimental MediaPipe LLM Inference API.
This new launch permits Massive Language Fashions (LLMs) to run absolutely on-device throughout platforms. This new functionality is especially transformative contemplating the reminiscence and compute calls for of LLMs, that are over 100 instances bigger than conventional on-device fashions. Optimizations throughout the on-device stack make this doable, together with new ops, quantization, caching, and weight sharing.
The experimental cross-platform MediaPipe LLM Inference API, designed to streamline on-device LLM integration for net builders, helps Net, Android, and iOS with preliminary assist for 4 overtly accessible LLMs: Gemma, Phi 2, Falcon, and Steady LM. It provides researchers and builders the pliability to prototype and take a look at fashionable overtly accessible LLM fashions on-device.
On Android, the MediaPipe LLM Inference API is meant for experimental and analysis use solely. Manufacturing purposes with LLMs can use the Gemini API or Gemini Nano on-device by Android AICore. AICore is the brand new system-level functionality launched in Android 14 to supply Gemini-powered options for high-end gadgets, together with integrations with the most recent ML accelerators, use-case optimized LoRA adapters, and security filters. To start out utilizing Gemini Nano on-device together with your app, apply to the Early Entry Preview.
LLM Inference API
Beginning right now, you’ll be able to take a look at out the MediaPipe LLM Inference API by way of our net demo or by constructing our pattern demo apps. You’ll be able to experiment and combine it into your tasks by way of our Net, Android, or iOS SDKs.
Utilizing the LLM Inference API permits you to deliver LLMs on-device in just some steps. These steps apply throughout net, iOS, and Android, although the SDK and native API will likely be platform particular. The next code samples present the online SDK.
1. Choose mannequin weights appropriate with certainly one of our supported mannequin architectures
2. Convert the mannequin weights right into a TensorFlow Lite Flatbuffer utilizing the MediaPipe Python Package deal
from mediapipe.duties.python.genai import converter config = converter.ConversionConfig(...) converter.convert_checkpoint(config)
3. Embrace the LLM Inference SDK in your utility
import { FilesetResolver, LlmInference } from "https://cdn.jsdelivr.web/npm/@mediapipe/tasks-genai”
4. Host the TensorFlow Lite Flatbuffer alongside together with your utility.
5. Use the LLM Inference API to take a textual content immediate and get a textual content response out of your mannequin.
const fileset = await FilesetResolver.forGenAiTasks("https://cdn.jsdelivr.web/npm/@mediapipe/tasks-genai/wasm"); const llmInference = await LlmInference.createFromModelPath(fileset, "mannequin.bin"); const responseText = await llmInference.generateResponse("Whats up, good to fulfill you"); doc.getElementById('output').textContent = responseText;
Please see our documentation and code examples for an in depth stroll by of every of those steps.
Listed below are actual time gifs of Gemma 2B operating by way of the MediaPipe LLM Inference API.
 |
| Gemma 2B operating on-device in browser by way of the MediaPipe LLM Inference API |
 |
| Gemma 2B operating on-device on iOS (left) and Android (proper) by way of the MediaPipe LLM Inference API |
Fashions
Our preliminary launch helps the next 4 mannequin architectures. Any mannequin weights appropriate with these architectures will work with the LLM Inference API. Use the bottom mannequin weights, use a group fine-tuned model of the weights, or positive tune weights utilizing your personal information.
|
Mannequin |
Parameter Dimension |
|
Falcon 1B |
1.3 Billion |
|
Gemma 2B |
2.5 Billion |
|
Phi 2 |
2.7 Billion |
|
Steady LM 3B |
2.8 Billion |
Mannequin Efficiency
By means of important optimizations, a few of that are detailed under, the MediaPipe LLM Inference API is ready to ship state-of-the-art latency on-device, specializing in CPU and GPU to assist a number of platforms. For sustained efficiency in a manufacturing setting on choose premium telephones, Android AICore can make the most of hardware-specific neural accelerators.
When measuring latency for an LLM, there are just a few phrases and measurements to think about. Time to First Token and Decode Pace would be the two most significant as these measure how shortly you get the beginning of your response and the way shortly the response generates as soon as it begins.
|
Time period |
Significance |
Measurement |
|
Token |
LLMs use tokens moderately than phrases as inputs and outputs. Every mannequin used with the LLM Inference API has a tokenizer constructed through which converts between phrases and tokens. |
100 English phrases ≈ 130 tokens. Nevertheless the conversion relies on the particular LLM and the language. |
|
Max Tokens |
The utmost complete tokens for the LLM immediate + response. |
Configured within the LLM Inference API at runtime. |
|
Time to First Token |
Time between calling the LLM Inference API and receiving the primary token of the response. |
Max Tokens / Prefill Pace |
|
Prefill Pace |
How shortly a immediate is processed by an LLM. |
Mannequin and system particular. Benchmark numbers under. |
|
Decode Pace |
How shortly a response is generated by an LLM. |
Mannequin and system particular. Benchmark numbers under. |
The Prefill Pace and Decode Pace are depending on mannequin, {hardware}, and max tokens. They’ll additionally change relying on the present load of the system.
The next speeds have been taken on excessive finish gadgets utilizing a max tokens of 1280 tokens, an enter immediate of 1024 tokens, and int8 weight quantization. The exception being Gemma 2B (int4), discovered right here on Kaggle, which makes use of a blended 4/8-bit weight quantization.
Benchmarks
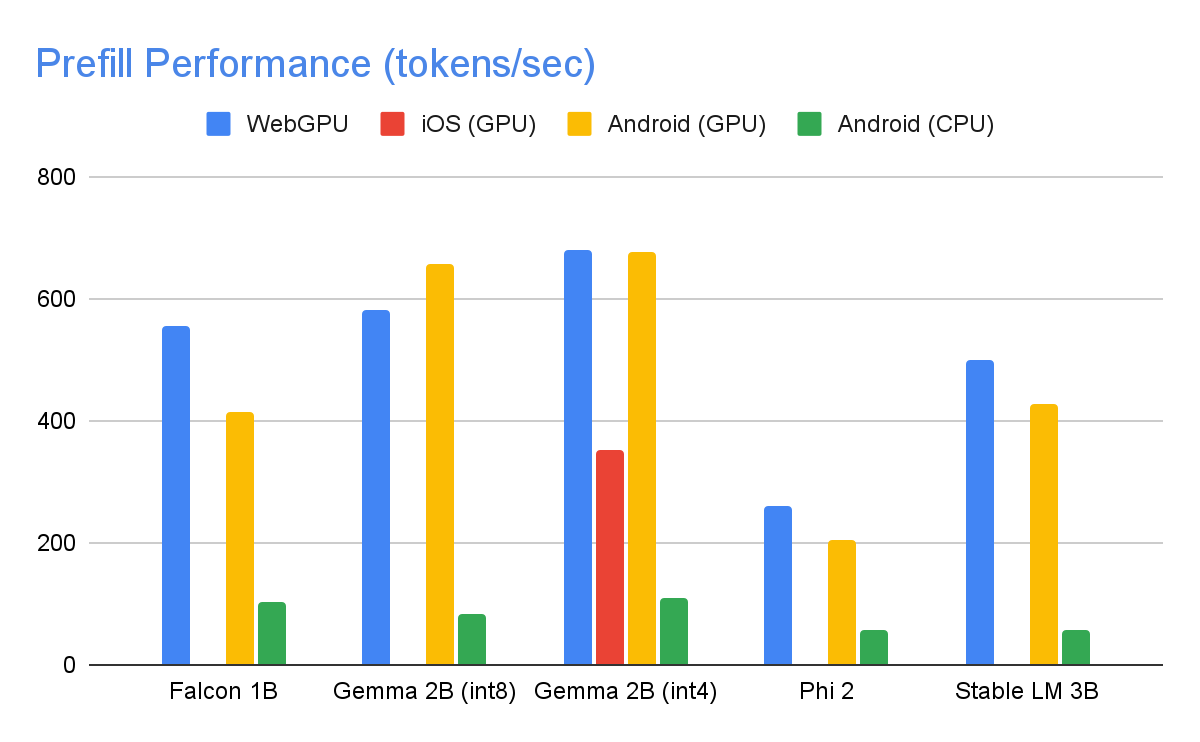 |
 |
| On the GPU, Falcon 1B and Phi 2 use fp32 activations, whereas Gemma and StableLM 3B use fp16 activations because the latter fashions confirmed larger robustness to precision loss based on our high quality eval research. The bottom bit activation information kind that maintained mannequin high quality was chosen for every. Word that Gemma 2B (int4) was the one mannequin we may run on iOS because of its reminiscence constraints, and we’re engaged on enabling different fashions on iOS as effectively. |
Efficiency Optimizations
To realize the efficiency numbers above, numerous optimizations have been made throughout MediaPipe, TensorFlow Lite, XNNPack (our CPU neural community operator library), and our GPU-accelerated runtime. The next are a choose few that resulted in significant efficiency enhancements.
Weights Sharing: The LLM inference course of includes 2 phases: a prefill part and a decode part. Historically, this setup would require 2 separate inference contexts, every independently managing assets for its corresponding ML mannequin. Given the reminiscence calls for of LLMs, we have added a characteristic that permits sharing the weights and the KV cache throughout inference contexts. Though sharing weights might sound simple, it has important efficiency implications when sharing between compute-bound and memory-bound operations. In typical ML inference situations, the place weights are usually not shared with different operators, they’re meticulously configured for every absolutely related operator individually to make sure optimum efficiency. Sharing weights with one other operator implies a lack of per-operator optimization and this mandates the authoring of latest kernel implementations that may run effectively even on sub-optimal weights.
Optimized Totally Related Ops: XNNPack’s FULLY_CONNECTED operation has undergone two important optimizations for LLM inference. First, dynamic vary quantization seamlessly merges the computational and reminiscence advantages of full integer quantization with the precision benefits of floating-point inference. The utilization of int8/int4 weights not solely enhances reminiscence throughput but in addition achieves exceptional efficiency, particularly with the environment friendly, in-register decoding of 4-bit weights requiring just one further instruction. Second, we actively leverage the I8MM directions in ARM v9 CPUs which allow the multiplication of a 2×8 int8 matrix by an 8×2 int8 matrix in a single instruction, leading to twice the velocity of the NEON dot product-based implementation.
Balancing Compute and Reminiscence: Upon profiling the LLM inference, we recognized distinct limitations for each phases: the prefill part faces restrictions imposed by the compute capability, whereas the decode part is constrained by reminiscence bandwidth. Consequently, every part employs completely different methods for dequantization of the shared int8/int4 weights. Within the prefill part, every convolution operator first dequantizes the weights into floating-point values earlier than the first computation, making certain optimum efficiency for computationally intensive convolutions. Conversely, the decode part minimizes reminiscence bandwidth by including the dequantization computation to the principle mathematical convolution operations.
 |
| Throughout the compute-intensive prefill part, the int4 weights are dequantized a priori for optimum CONV_2D computation. Within the memory-intensive decode part, dequantization is carried out on the fly, together with CONV_2D computation, to attenuate the reminiscence bandwidth utilization. |
Customized Operators: For GPU-accelerated LLM inference on-device, we rely extensively on customized operations to mitigate the inefficiency attributable to quite a few small shaders. These customized ops enable for particular operator fusions and numerous LLM parameters reminiscent of token ID, sequence patch measurement, sampling parameters, to be packed right into a specialised customized tensor used largely inside these specialised operations.
Pseudo-Dynamism: Within the consideration block, we encounter dynamic operations that improve over time because the context grows. Since our GPU runtime lacks assist for dynamic ops/tensors, we go for mounted operations with a predefined most cache measurement. To cut back the computational complexity, we introduce a parameter enabling the skipping of sure worth calculations or the processing of lowered information.
Optimized KV Cache Format: Because the entries within the KV cache finally function weights for convolutions, employed in lieu of matrix multiplications, we retailer these in a specialised format tailor-made for convolution weights. This strategic adjustment eliminates the need for further conversions or reliance on unoptimized layouts, and subsequently contributes to a extra environment friendly and streamlined course of.
What’s Subsequent
We’re thrilled with the optimizations and the efficiency in right now’s experimental launch of the MediaPipe LLM Inference API. That is simply the beginning. Over 2024, we’ll develop to extra platforms and fashions, provide broader conversion instruments, complimentary on-device elements, excessive degree duties, and extra.
You’ll be able to take a look at the official pattern on GitHub demonstrating all the pieces you’ve simply realized about and browse by our official documentation for much more particulars. Keep watch over the Google for Builders YouTube channel for updates and tutorials.
Acknowledgements
We’d wish to thank all crew members who contributed to this work: T.J. Alumbaugh, Alek Andreev, Frank Ban, Jeanine Banks, Frank Barchard, Pulkit Bhuwalka, Buck Bourdon, Maxime Brénon, Chuo-Ling Chang, Lin Chen, Linkun Chen, Yu-hui Chen, Nikolai Chinaev, Clark Duvall, Rosário Fernandes, Mig Gerard, Matthias Grundmann, Ayush Gupta, Mohammadreza Heydary, Ekaterina Ignasheva, Ram Iyengar, Grant Jensen, Alex Kanaukou, Prianka Liz Kariat, Alan Kelly, Kathleen Kenealy, Ho Ko, Sachin Kotwani, Andrei Kulik, Yi-Chun Kuo, Khanh LeViet, Yang Lu, Lalit Singh Manral, Tyler Mullen, Karthik Raveendran, Raman Sarokin, Sebastian Schmidt, Kris Tonthat, Lu Wang, Zoe Wang, Tris Warkentin, Geng Yan, Tenghui Zhu, and the Gemma crew.