
In deep studying, the hunt for effectivity has led to a paradigm shift in how we finetune large-scale fashions. The analysis spearheaded by Soufiane Hayou, Nikhil Ghosh, and Bin Yu from the College of California, Berkeley, introduces a big enhancement to the Low-Rank Adaptation (LoRA) methodology, termed LoRA+. This novel strategy is designed to optimize the finetuning strategy of fashions characterised by their huge variety of parameters, which frequently run into the tens or lots of of billions.
Adapting large fashions to particular duties has been difficult as a result of computational burden. Researchers have navigated this by freezing the unique weights of the mannequin and adjusting solely a small subset of parameters via strategies like immediate tuning, adapters, and LoRA. The final, specifically, includes coaching a low-rank matrix added to the pretrained weights, thus lowering the variety of parameters that want adjustment.
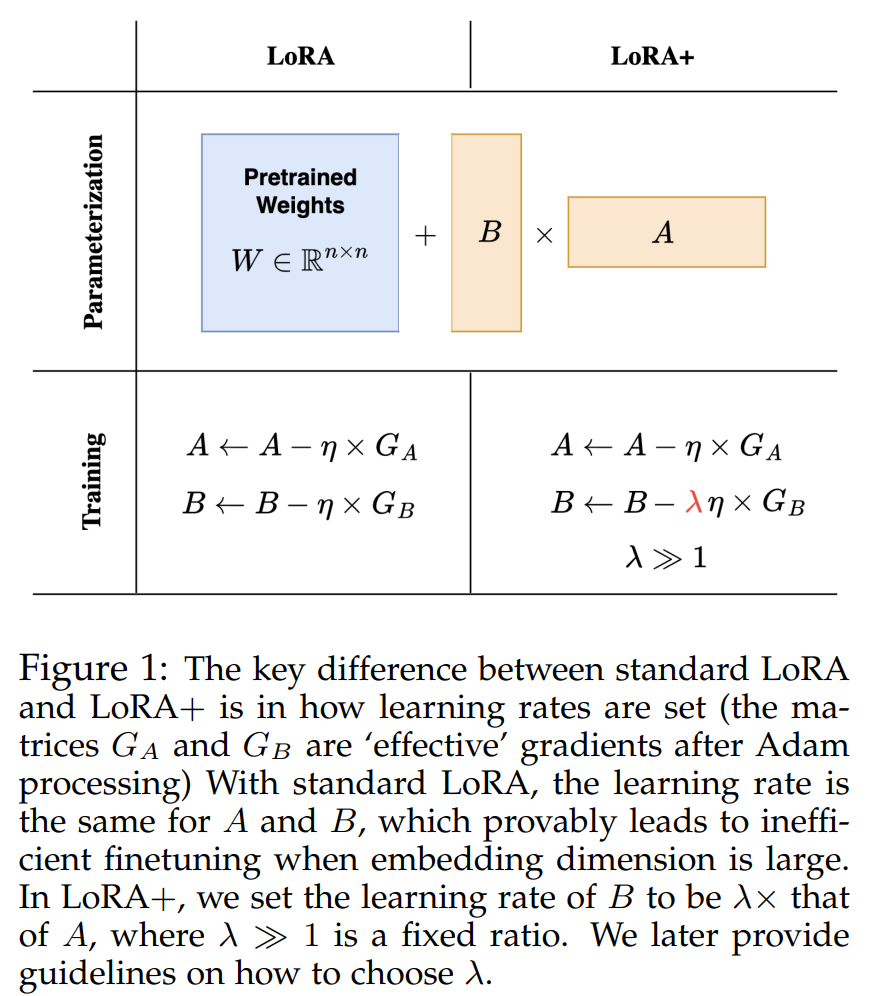
As recognized by the UC Berkeley crew, the crux of the inefficiency within the present LoRA methodology lies within the uniform studying fee utilized to the adapter matrices A and B. Given the vastness of the mannequin width, greater than a one-size-fits-all strategy to the training fee is required, resulting in suboptimal function studying. The introduction of LoRA+ addresses this by implementing differentiated studying charges for matrices A and B, optimized via a hard and fast ratio. This nuanced strategy ensures a tailor-made studying fee that higher fits the size and dynamics of huge fashions.
The crew’s rigorous experimentation offers strong backing for the prevalence of LoRA+ over the standard LoRA methodology. By way of complete testing throughout varied benchmarks, together with these involving Roberta-base and GPT-2 fashions, LoRA+ constantly showcased enhanced efficiency and finetuning velocity. Notably, the tactic achieved efficiency enhancements starting from 1% to 2% and a finetuning speedup of as much as roughly 2X whereas sustaining the identical computational prices. Such empirical proof underscores the potential of LoRA+ to revolutionize the finetuning course of for big fashions.
Particularly, when utilized to the Roberta-base mannequin throughout totally different duties, LoRA+ achieved exceptional check accuracies, with a notable enhance in ‘tougher’ duties reminiscent of MNLI and QQP in comparison with simpler ones like SST2 and QNLI. This variation in efficiency amplifies the significance of environment friendly function studying, notably in advanced duties the place the pretrained mannequin’s alignment with the finetuning activity is much less simple. Moreover, the Llama-7b mannequin’s adaptation utilizing LoRA+ on the MNLI dataset and the Flan-v2 dataset solidified the tactic’s efficacy, showcasing vital efficiency positive aspects.
The methodology behind LoRA+, involving setting totally different studying charges for LoRA adapter matrices with a hard and fast ratio, is not only a technical tweak however a strategic overhaul of the finetuning course of. This strategy permits for a extra refined adaptation of the mannequin to the specificities of the duty at hand, enabling a stage of customization beforehand unattainable with uniform studying fee changes.
In sum, the introduction of LoRA+ by the analysis crew from UC Berkeley marks a pivotal development in deep studying. By addressing the inefficiencies within the LoRA methodology via an modern adjustment of studying charges, LoRA+ paves the best way for simpler and environment friendly finetuning large-scale fashions. This breakthrough enhances the efficiency and velocity of mannequin adaptation and broadens the horizon for future analysis and functions in optimizing the finetuning processes of neural networks. The findings from this examine, substantiated by rigorous empirical proof, invite a reevaluation of present practices and supply a promising avenue for leveraging the complete potential of huge fashions in varied functions.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
You may additionally like our FREE AI Programs….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible functions. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.