
We’re thrilled to announce the discharge of Tower, a multilingual 7B parameter giant language mannequin (LLM) optimized for translation-related duties. Tower is constructed on prime of LLaMA2 [1] and at the moment helps 10 languages: English, German, French, Spanish, Chinese language, Portuguese, Italian, Russian, Korean, and Dutch. It matches state-of-the-art fashions on translation in addition to GPT3.5, and it surpasses bigger open fashions, akin to ALMA 13B [5] and LLaMA-2 70B. Tower additionally masters a variety of different translation-related duties, starting from pre-translation duties, akin to grammatical error correction, to translation and analysis duties, akin to machine translation (MT), computerized post-editing (APE), and translation rating. If you happen to’re engaged on multilingual NLP and associated issues, go forward and take a look at Tower.
The coaching and launch of the Tower mannequin is a joint effort of Unbabel, the SARDINE Lab at Instituto Superior Técnico, and the MICS lab at CentraleSupélec on the College of Paris-Saclay. The objective of this launch is to advertise collaborative and reproducible analysis to facilitate data sharing and to drive additional developments to multilingual LLMs and associated analysis. As such, we’re joyful to:
- Launch the weights of our two Tower fashions: TowerBase and TowerInstruct.
- Launch the information that we used to fine-tune these fashions: TowerBlocks
- Launch the analysis knowledge and code: TowerEval, the primary LLM analysis repository for MT-related duties.
From LLaMA2 to Tower: how we reworked an English-centric LLM right into a multilingual one
Massive language fashions took the world by storm final yr. From GPT-3.5 to LLaMA and Mixtral, closed and open-source LLMs have demonstrated more and more robust capabilities for fixing pure language duties. Machine translation is not any exception: GPT-4 was amongst final yr’s greatest translation techniques for a number of language instructions within the WMT2023’s Common Translation observe, essentially the most established benchmark within the area.
Sadly, the story just isn’t the identical with present open-source fashions; these are predominantly constructed with English knowledge and little to no multilingual knowledge and are but to make a big dent in translation and associated duties, like computerized post-edition, computerized translation analysis, amongst others. We wanted to bridge this hole, so we got down to construct a state-of-the-art multilingual mannequin on prime of LLaMA2.
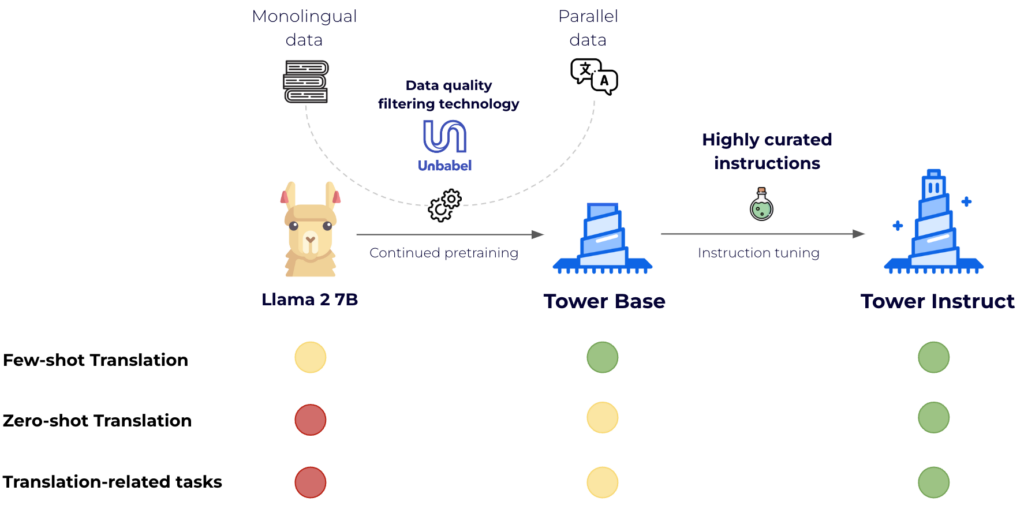
This required two steps: continued pre-training and instruction tuning. The previous is crucial to enhance LLaMA2’s help to different languages, and the latter takes the mannequin to the following stage when it comes to fixing particular duties in a 0-shot vogue.
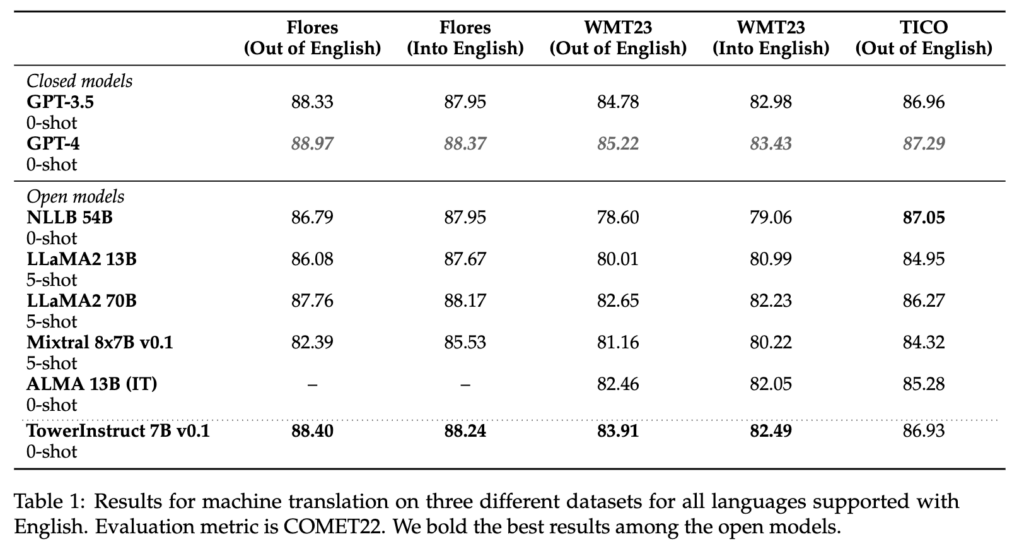
For continued pretraining, we leveraged 20 billion tokens of textual content evenly cut up amongst languages. Two-thirds of the tokens come from monolingual knowledge sources — a filtered model of the mc4 [3] dataset — and one-third are parallel sentences from numerous public sources akin to OPUS [5]. Crucially, we leverage Unbabel expertise, COMETKiwi [2], to filter for high-quality parallel knowledge. The result is a considerably improved model of LLaMA2 for the goal languages that maintains its capabilities in English: TowerBase. The languages supported by the present model are English, German, French, Chinese language, Spanish, Portuguese, Italian, Dutch, Korean, and Russian.
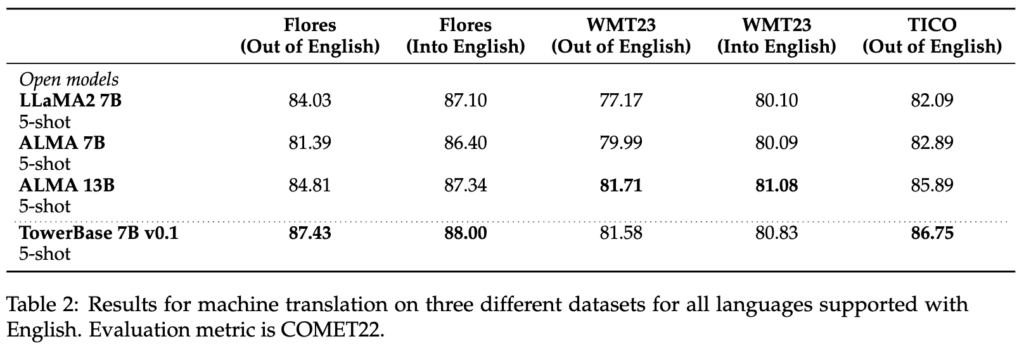
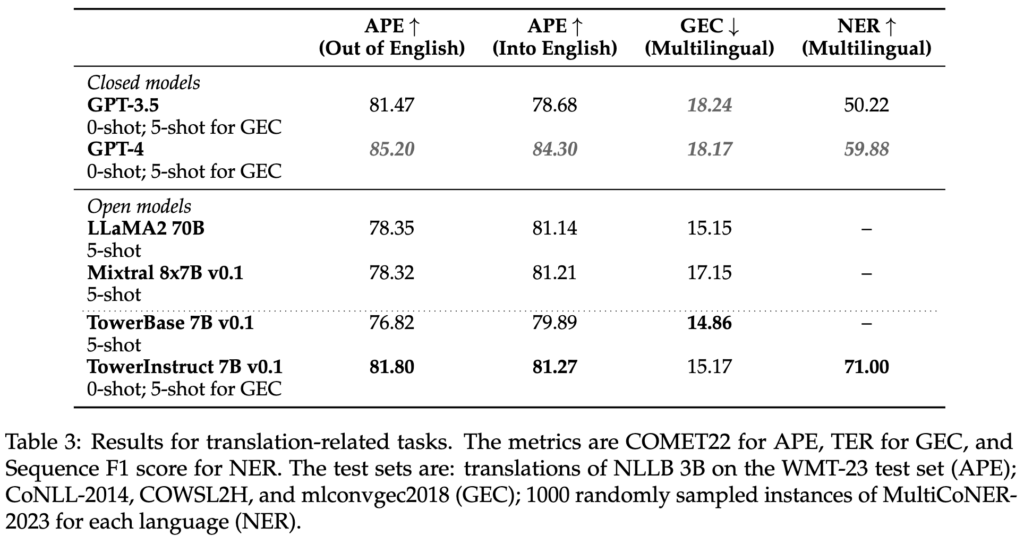
For supervised fine-tuning, we rigorously constructed a dataset with various, high-quality task-specific data, in addition to conversational knowledge and code directions. We manually constructed tons of of various prompts throughout all duties, together with zero and few-shot templates. Our dataset, TowerBlocks, consists of knowledge for a number of translation-related duties, akin to computerized publish version, machine translation and its totally different variants (e.g., context-aware translation, terminology-aware translation, multi-reference translation), named-entity recognition, error span prediction, paraphrase technology, and others. The info data have been rigorously filtered utilizing totally different heuristics and high quality filters, akin to COMETKiwi, to make sure the usage of high-quality knowledge at fine-tuning time. Greater than some other issue, this filtering, mixed with cautious alternative of hyperparameters, performed an important position in acquiring important enhancements over the continued pre-trained mannequin. The ensuing mannequin, TowerInstruct, handles a number of duties seamlessly in a 0-shot vogue — enhancing effectivity at inference time — and might remedy different held-out duties with acceptable immediate engineering. Particularly, for machine translation, TowerInstruct is aggressive and might outperform GPT3.5 and Mixtral 8x7B [6], whereas for computerized post-edition, named-entity recognition and supply error correction, it outperforms GPT3.5 and Mixtral 8x7B throughout the board, and might go so far as outperforming GPT4.
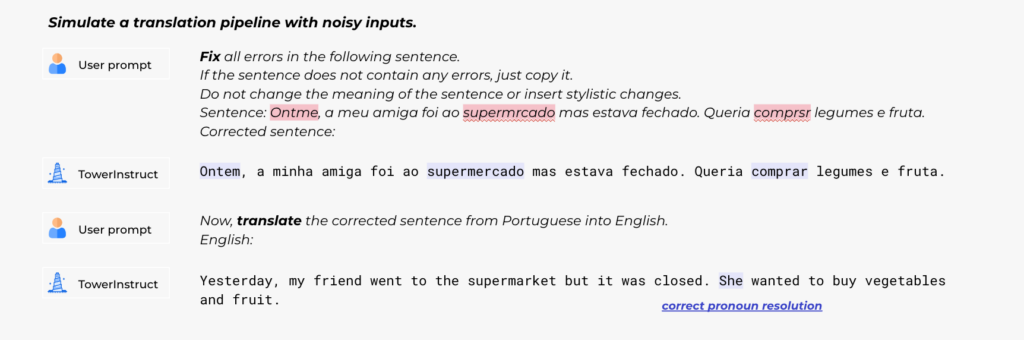


Utilizing the Tower fashions
We’re releasing each pre-trained and instruction-tuned mannequin weights, in addition to the instruction tuning and analysis knowledge. We will even launch TowerEval, an analysis repository targeted on MT and associated duties that can permit customers to breed our benchmarks and consider their very own LLMs. We invite you to go to our Huggingface web page and GitHub repository and begin utilizing them!
These Tower fashions are solely the start: internally, we’re engaged on leveraging Unbabel expertise and knowledge to enhance our translation platform. Transferring ahead, we plan to make much more thrilling releases, so keep tuned!
Acknowledgments
A part of this work was supported by the EU’s Horizon Europe Analysis and Innovation Actions (UTTER, contract 101070631), by the challenge DECOLLAGE (ERC-2022-CoG 101088763), and by the Portuguese Restoration and Resilience Plan by means of challenge C645008882- 00000055 (Middle for Accountable AI). We thank GENCI-IDRIS for the technical help and HPC sources used to partially help this work.
References
[1] Llama 2: Open Basis and Nice-Tuned Chat Fashions. Technical report
[2] Scaling up CometKiwi: Unbabel-IST 2023 Submission for the High quality Estimation Shared Process. WMT23
[4] Parallel Information, Instruments and Interfaces in OPUS. LREC2012