
We’re excited to announce the Normal Availability of serverless compute for notebooks, jobs and Delta Dwell Tables (DLT) on AWS and Azure. Databricks prospects already take pleasure in quick, easy and dependable serverless compute for Databricks SQL and Databricks Mannequin Serving. The identical functionality is now out there for all ETL workloads on the Information Intelligence Platform, together with Apache Spark and Delta Dwell Tables. You write the code and Databricks offers speedy workload startup, automated infrastructure scaling and seamless model upgrades of the Databricks Runtime. Importantly, with serverless compute you’re solely billed for work finished as a substitute of time spent buying and initializing cases from cloud suppliers.
Our present serverless compute providing is optimized for quick startup, scaling, and efficiency. Customers will quickly have the ability to categorical different objectives similar to decrease value. We’re at present providing an introductory promotional low cost on serverless compute, out there now till October 31, 2024. You get a 50% value discount on serverless compute for Workflows and DLT and a 30% value discount for Notebooks.
“Cluster startup is a precedence for us, and serverless Notebooks and Workflows have made an enormous distinction. Serverless compute for notebooks make it simple with only a single click on; we get serverless compute that seamlessly integrates into workflows. Plus, it is safe. This long-awaited characteristic is a game-changer. Thanks, Databricks!”
— Chiranjeevi Katta, Information Engineer, Airbus
Let’s discover the challenges serverless compute helps resolve and the distinctive advantages it provides information groups.
Compute infrastructure is advanced and expensive to handle
Configuring and managing compute similar to Spark clusters has lengthy been a problem for information engineers and information scientists. Time spent on configuring and managing compute is time not spent offering worth to the enterprise.
Selecting the best occasion kind and measurement is time-consuming and requires experimentation to find out the optimum alternative for a given workload. Determining cluster insurance policies, auto-scaling, and Spark configurations additional complicates this job and requires experience. When you get clusters arrange and working, you continue to need to spend time sustaining and tuning their efficiency and updating Databricks Runtime variations so you may profit from new capabilities.
Idle time – time not spent processing your workloads, however that you’re nonetheless paying for – is one other expensive end result of managing your individual compute infrastructure. Throughout compute initialization and scale-up, cases have to boot up, software program together with Databricks Runtime must be put in, and so forth. You pay your cloud supplier for this time. Second, for those who over-provision compute through the use of too many cases or occasion varieties which have an excessive amount of reminiscence, CPU, and so forth., compute might be under-utilized but you’ll nonetheless pay for the entire provisioned compute capability.
Observing this value and complexity throughout thousands and thousands of buyer workloads led us to innovate with serverless compute.
Serverless compute is quick, easy and dependable
In basic compute, you give Databricks delegated permission through advanced cloud insurance policies and roles to handle the lifecycle of cases wanted to your workloads. Serverless compute removes this complexity since Databricks manages an enormous, safe fleet of compute in your behalf. You possibly can simply begin utilizing Databricks with none setup.
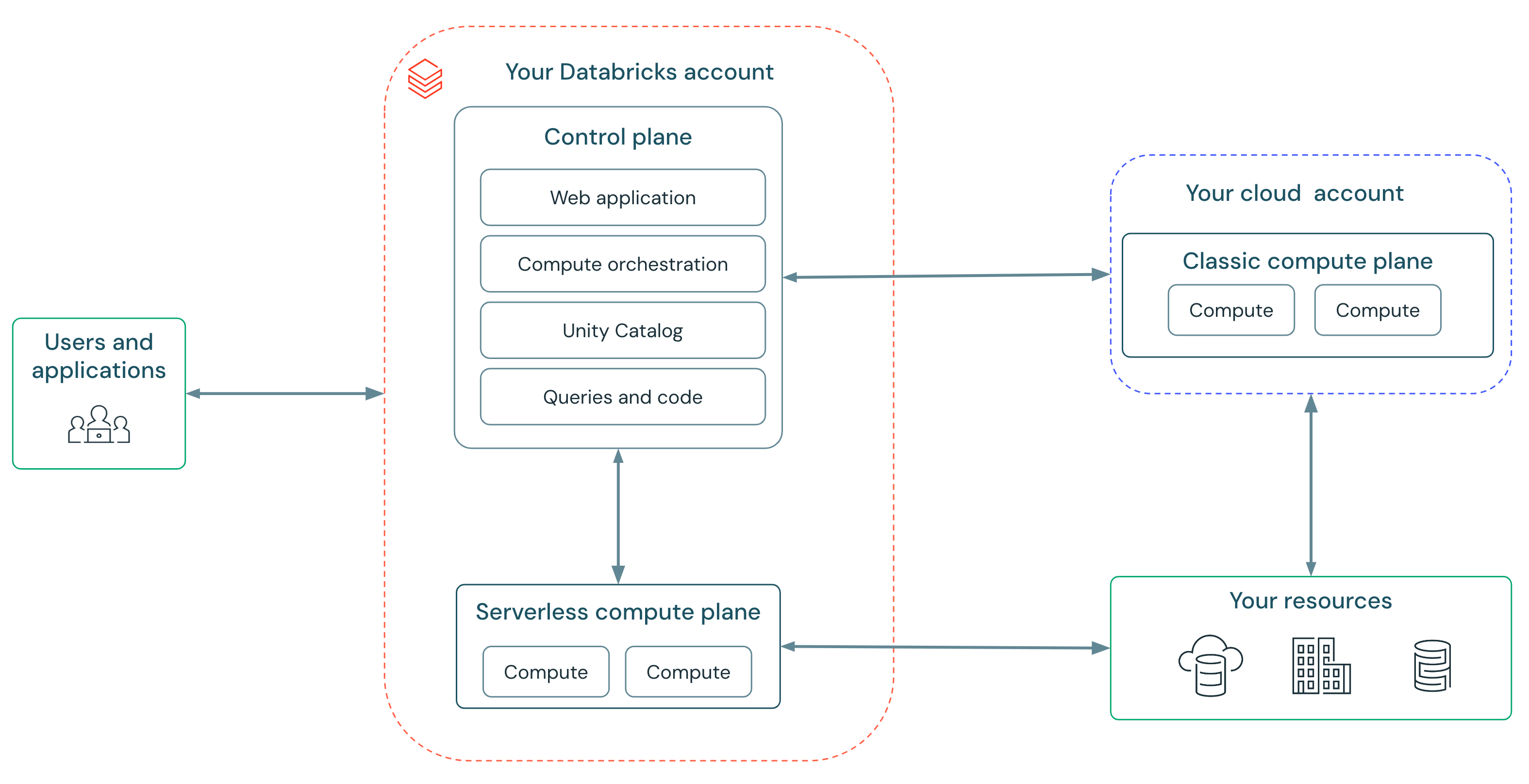
Serverless compute permits us to supply a service that’s quick, easy, and dependable:
- Quick: No extra ready for clusters — compute begins up in seconds, not minutes. Databricks runs “heat swimming pools” of cases in order that compute is prepared when you’re.
- Easy: No extra selecting occasion varieties, cluster scaling parameters, or setting Spark configs. Serverless features a new autoscaler which is smarter and extra conscious of your workload’s wants than the autoscaler in basic compute. Because of this each consumer is now in a position to run workloads with out hand-holding of infrastructure consultants. Databricks updates workloads robotically and safely improve to the newest Spark variations — making certain you at all times get the newest efficiency and safety advantages.
- Dependable: Databricks’ serverless compute shields prospects from cloud outages with automated occasion kind failover and a “heat pool” of cases buffering from availability shortages.
“It’s totally simple to maneuver workflows from Dev to Prod with out the necessity to decide on employee varieties. [The] vital enchancment in start-up time, mixed with lowered DataOps configuration and upkeep, enormously enhances productiveness and effectivity.”
— Gal Doron, Head of Information, AnyClip
Serverless compute payments for work finished
We’re excited to introduce an elastic billing mannequin for serverless compute. You’re billed solely when compute is assigned to your workloads and never for the time to amass and arrange compute cases.
The clever serverless autoscaler ensures that your workspace will at all times have the correct amount of capability provisioned so we are able to reply to demand e.g., when a consumer runs a command in a pocket book. It would robotically scale workspace capability up and down in graduated steps to satisfy your wants. To make sure sources are managed properly, we’ll cut back provisioned capability after a couple of minutes when the clever autoscaler predicts it’s now not wanted.
“Serverless compute for DLT was extremely simple to arrange and get working, and we’re already seeing main efficiency enhancements from our materialized views. Traditionally going from uncooked information to the silver layer took us about 16 minutes, however after switching to serverless, it is solely about 7 minutes. The time and price financial savings are going to be immense”
— Aaron Jespen, Director IT Operations, Jetlinx
Serverless compute is straightforward to handle
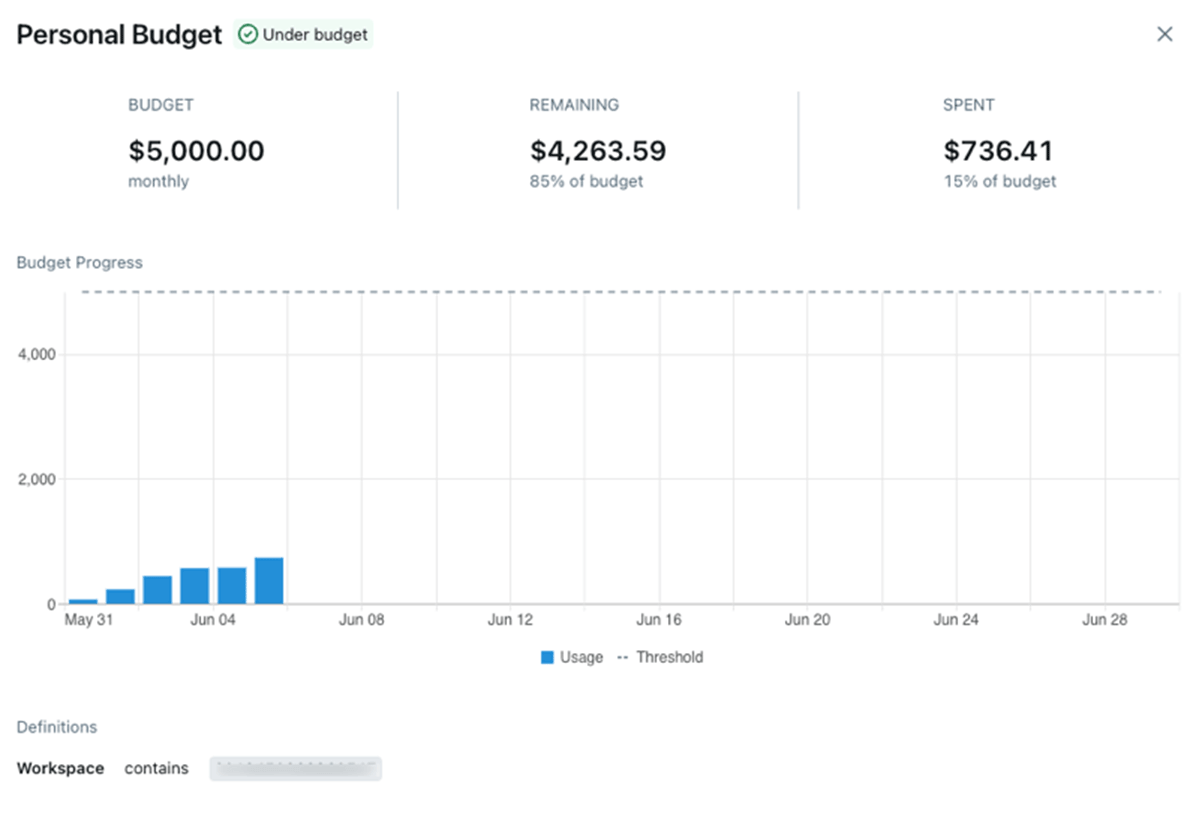
Serverless compute contains instruments for directors to handle prices and budgets. In spite of everything, simplicity shouldn’t imply funds overruns and stunning payments!
Information in regards to the utilization and prices of serverless compute is accessible in system tables. We offer pre-built dashboards that allow you to get an summary of prices and drill down into particular workloads.

Directors can use funds alerts (Preview) to group prices and arrange alerts. There’s a pleasant UI for managing budgets.
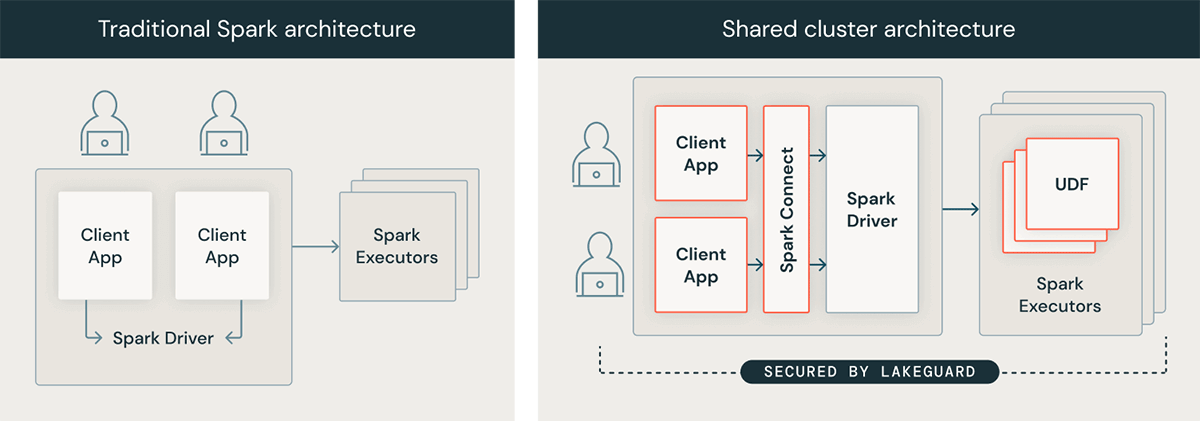
Serverless compute is designed for contemporary Spark workloads
Beneath the hood, serverless compute makes use of Lakeguard to isolate consumer code utilizing sandboxing strategies, an absolute necessity in a serverless setting. Consequently, some workloads require code modifications to proceed engaged on serverless. Serverless compute requires Unity Catalog for safe entry to information property, therefore workloads that entry information with out utilizing Unity Catalog might have modifications.
The best method to take a look at in case your workload is prepared for serverless compute is to first run it on a basic cluster utilizing shared entry mode on DBR 14.3+.
Serverless compute is able to use
We’re exhausting at work to make serverless compute even higher within the coming months:
- GCP help: We at the moment are starting a personal preview on serverless compute on GCP; keep tuned for our public preview and GA bulletins.
- Non-public networking and egress controls: Hook up with sources inside your personal community, and management what your serverless compute sources can entry on the general public Web.
- Enforceable attribution: Make sure that all notebooks, workflows, and DLT pipelines are appropriately tagged to be able to assign value to particular value facilities, e.g. for chargebacks.
- Environments: Admins will have the ability to set a base setting for the workspace with entry to personal repositories, particular Python and library variations, and setting variables.
- Value vs. efficiency: Serverless compute is at present optimized for quick startup, scaling, and efficiency. Customers will quickly have the ability to categorical different objectives similar to decrease value.
- Scala help: Customers will have the ability to run Scala workloads on serverless compute. To get able to easily transfer to serverless as soon as out there, transfer your Scala workloads to basic compute with Shared Entry mode.
To start out utilizing serverless compute in the present day: