
In transformer architectures, the computational prices and activation reminiscence develop linearly with the rise within the hidden layer width of feedforward (FFW) layers. This scaling difficulty poses a big problem, particularly as fashions turn into bigger and extra complicated. Overcoming this problem is important for advancing AI analysis, because it instantly impacts the feasibility of deploying large-scale fashions in real-world functions, similar to language modeling and pure language processing duties.
Present strategies addressing this problem make the most of Combination-of-Consultants (MoE) architectures, which deploy sparsely activated professional modules as an alternative of a single dense FFW layer. This method permits mannequin dimension to be decoupled from computational value. Regardless of the promise of MoEs, as demonstrated by researchers like Shazeer et al. (2017) and Lepikhin et al. (2020), these fashions face computational and optimization challenges when scaling past a small variety of consultants. The effectivity positive factors typically plateau with growing mannequin dimension on account of a hard and fast variety of coaching tokens. These limitations stop the total potential of MoEs from being realized, particularly in duties requiring intensive and continuous studying.
The Researchers from Google DeepMind suggest a novel method known as Parameter Environment friendly Knowledgeable Retrieval (PEER), which particularly addresses the constraints of current MoE fashions. PEER leverages the product key method for sparse retrieval from an enormous pool of tiny consultants, numbering over 1,000,000. This method enhances the granularity of MoE fashions, leading to a greater performance-compute trade-off. The innovation lies in the usage of a discovered index construction for routing, enabling environment friendly and scalable professional retrieval. This methodology decouples computational value from parameter depend, representing a big development over earlier architectures. PEER layers exhibit substantial enhancements in effectivity and efficiency for language modeling duties.
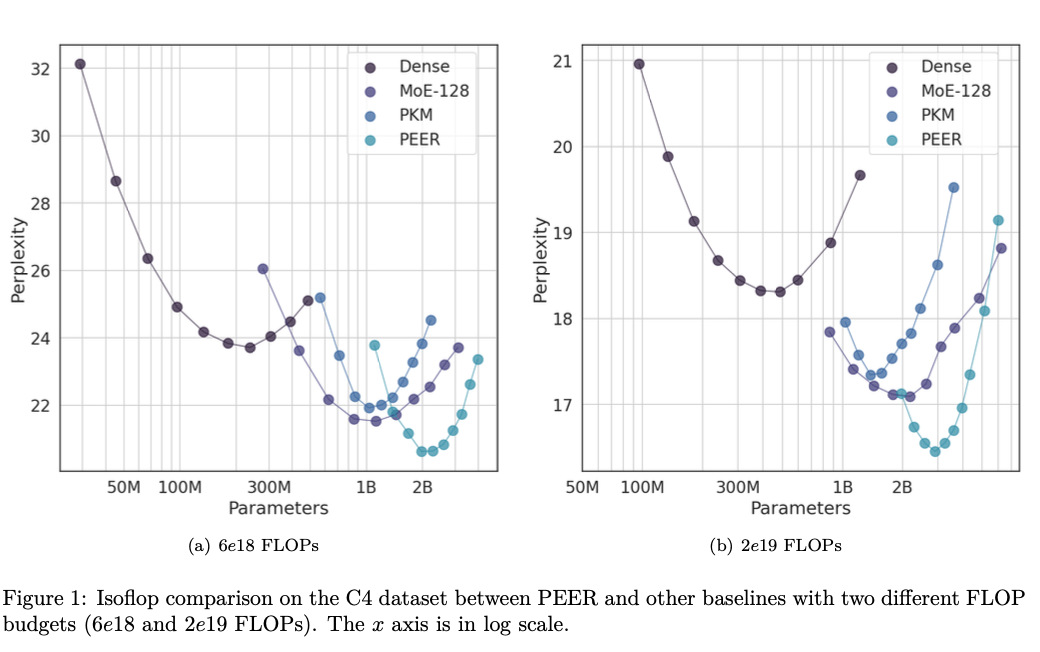
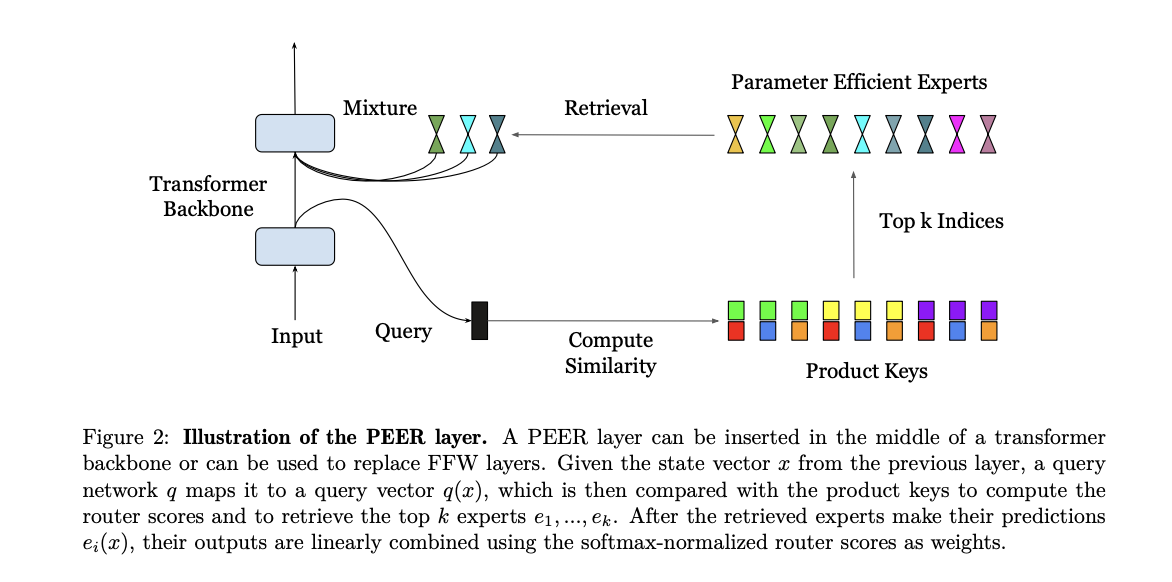
The PEER layer operates by mapping an enter vector to a question vector, which is then in contrast with a set of product keys to retrieve the highest ok consultants. These consultants are single-neuron multi-layer perceptrons (MLPs) that contribute to the ultimate output by a weighted mixture primarily based on router scores. The product key retrieval method reduces the complexity of professional retrieval, making it possible to deal with over 1,000,000 consultants effectively. The dataset used for experiments is the C4 dataset, with isoFLOP evaluation carried out to match PEER with dense FFW, coarse-grained MoEs, and Product Key Reminiscence (PKM) layers. The experiments concerned various the mannequin dimension and the variety of coaching tokens to determine compute-optimal configurations.
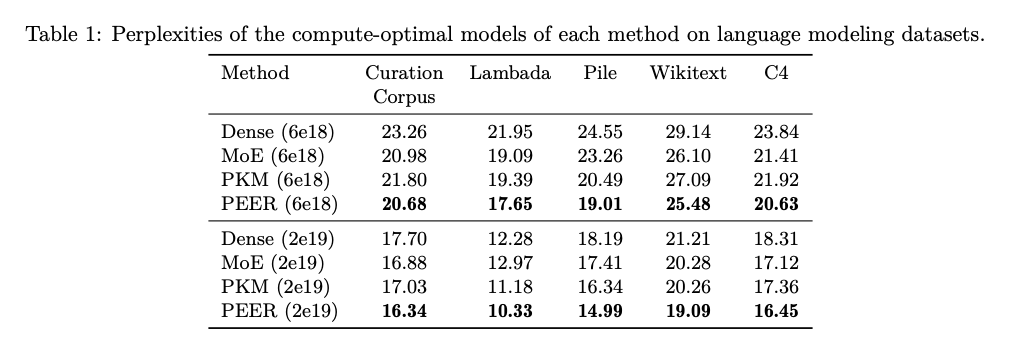
The outcomes present that PEER layers considerably outperform dense FFWs and coarse-grained MoEs by way of performance-compute trade-off. When utilized to a number of language modeling datasets, together with the Curation Corpus, Lambada, the Pile, Wikitext, and C4, the PEER fashions achieved notably decrease perplexity scores. For example, with a FLOP price range of 2e19, PEER fashions reached a perplexity of 16.34 on the C4 dataset, which is decrease in comparison with 17.70 for dense fashions and 16.88 for MoE fashions. These findings spotlight the effectivity and effectiveness of the PEER structure in enhancing the scalability and efficiency of transformer fashions.
In conclusion, this proposed methodology represents a big contribution to AI analysis by introducing the PEER structure. This novel method addresses the computational challenges related to scaling transformer fashions by leveraging an enormous variety of tiny consultants and environment friendly routing methods. The PEER mannequin’s superior performance-compute trade-off, demonstrated by intensive experiments, highlights its potential to advance AI analysis by enabling extra environment friendly and highly effective language fashions. The findings recommend that PEER can successfully scale to deal with intensive and steady knowledge streams, making it a promising answer for lifelong studying and different demanding AI functions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.