
Retrieval-Augmented Technology (RAG) strategies improve the capabilities of huge language fashions (LLMs) by incorporating exterior information retrieved from huge corpora. This strategy is especially useful for open-domain query answering, the place detailed and correct responses are essential. By leveraging exterior info, RAG methods can overcome the restrictions of relying solely on the parametric information embedded in LLMs, making them simpler in dealing with advanced queries.
A major problem in RAG methods is the imbalance between the retriever and reader elements. Conventional frameworks typically use brief retrieval models, equivalent to 100-word passages, requiring the retriever to sift by giant quantities of knowledge. This design burdens the retriever closely whereas the reader’s job stays comparatively easy, resulting in inefficiencies and potential semantic incompleteness as a result of doc truncation. This imbalance restricts the general efficiency of RAG methods, necessitating a re-evaluation of their design.
Present strategies in RAG methods embrace strategies like Dense Passage Retrieval (DPR), which focuses on discovering exact, brief retrieval models from giant corpora. These strategies typically contain recalling many models and using advanced re-ranking processes to attain excessive accuracy. Whereas efficient to some extent, these approaches nonetheless have to work on inherent inefficiency and incomplete semantic illustration as a result of their reliance on brief retrieval models.
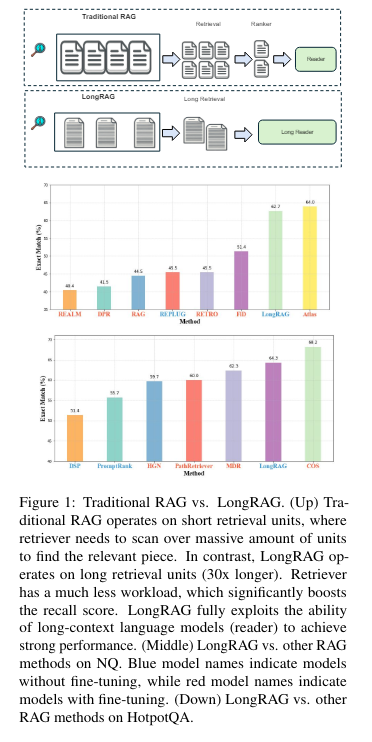
To deal with these challenges, the analysis staff from the College of Waterloo launched a novel framework known as LongRAG. This framework contains a “lengthy retriever” and a “lengthy reader” part, designed to course of longer retrieval models of round 4K tokens every. By growing the scale of the retrieval models, LongRAG reduces the variety of models from 22 million to 600,000, considerably easing the retriever’s workload and bettering retrieval scores. This progressive strategy permits the retriever to deal with extra complete info models, enhancing the system’s effectivity and accuracy.
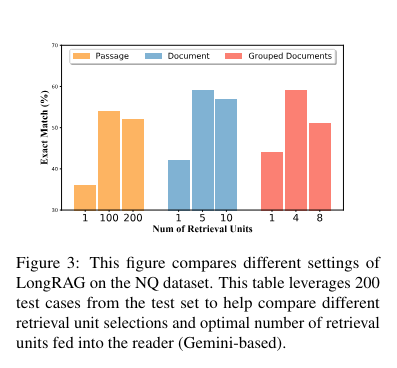
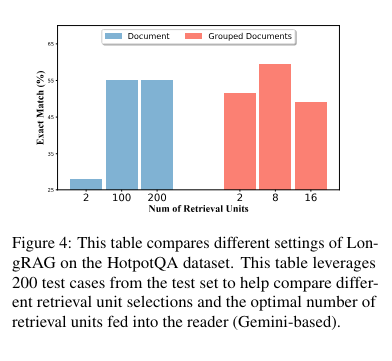
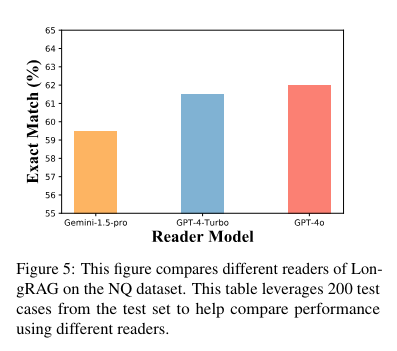
The LongRAG framework operates by grouping associated paperwork into lengthy retrieval models, which the lengthy retriever then processes to establish related info. To extract the ultimate solutions, the retriever filters the highest 4 to eight models, concatenated and fed right into a long-context LLM, equivalent to Gemini-1.5-Professional or GPT-4o. This technique leverages the superior capabilities of long-context fashions to course of giant quantities of textual content effectively, guaranteeing a radical and correct extraction of data.
In-depth, the methodology entails utilizing an encoder to map the enter query to a vector and a unique encoder to map the retrieval models to vectors. The similarity between the query and the retrieval models is calculated to establish probably the most related models. The lengthy retriever searches by these models, decreasing the corpus measurement and bettering the retriever’s precision. The retrieved models are then concatenated and fed into the lengthy reader, which makes use of the context to generate the ultimate reply. This strategy ensures that the reader processes a complete set of data, bettering the system’s total efficiency.
The efficiency of LongRAG is actually exceptional. On the Pure Questions (NQ) dataset, it achieved a precise match (EM) rating of 62.7%, a major leap ahead in comparison with conventional strategies. On the HotpotQA dataset, it reached an EM rating of 64.3%. These spectacular outcomes show the effectiveness of LongRAG, matching the efficiency of state-of-the-art fine-tuned RAG fashions. The framework diminished the corpus measurement by 30 instances and improved the reply recall by roughly 20 share factors in comparison with conventional strategies, with a solution recall@1 rating of 71% on NQ and 72% on HotpotQA.
LongRAG’s capacity to course of lengthy retrieval models preserves the semantic integrity of paperwork, permitting for extra correct and complete responses. By decreasing the burden on the retriever and leveraging superior long-context LLMs, LongRAG provides a extra balanced and environment friendly strategy to retrieval-augmented technology. The analysis from the College of Waterloo not solely offers beneficial insights into modernizing RAG system design but in addition highlights the thrilling potential for additional developments on this discipline, sparking optimism for the way forward for retrieval-augmented technology methods.
In conclusion, LongRAG represents a major step ahead in addressing the inefficiencies and imbalances in conventional RAG methods. Using lengthy retrieval models and leveraging the capabilities of superior LLMs’ capabilities enhances the accuracy and effectivity of open-domain question-answering duties. This progressive framework improves retrieval efficiency and units the stage for future developments in retrieval-augmented technology methods.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular information with the primary compound AI system, Gretel Navigator, now usually out there! [Advertisement]
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.