

Duplicate content material is a typical situation for web site homeowners and search engine optimization professionals. It will probably result in a myriad of issues, together with lowered search engine visibility, diluted hyperlink fairness and a irritating person expertise.
Regardless of the title, your organization’s content material director isn’t normally the precise individual to repair this. As an alternative, duplicate content material is often a technical drawback that requires a technical method to repair.
On this weblog publish, we’ll discover the frequent causes of duplicate content material points and, most significantly, offer you actionable methods for fixing these challenges!
Duplicate Content material Outlined
Earlier than we dig too deep into this matter, it’s finest to outline what “duplicate content material” means within the context of this text. Put merely, the time period duplicate content material refers to the incidence of 1 and the identical piece of content material or very comparable content material below a number of URLs.
Whereas it may be used to explain similar content material on totally different domains, on this article we’re concerned with what you are able to do about it when it happens inside one web site – also called “inner duplicate content material”.
I’ll be speaking about substantial blocks of content material that both fully match different content material on the identical website or are very comparable.
Basically, it’s when the identical or very comparable content material seems at a couple of internet tackle (URL).
What Is the Influence of Duplicate Content material on search engine optimization?
Google very clearly tells us that they “strive laborious to index and present pages with distinct data.”
“Our customers sometimes wish to see a various cross-section of distinctive content material once they do searches. In distinction, they’re understandably irritated once they see considerably the identical content material inside a set of search outcomes.”
Whereas any good search engine optimization ought to learn between the strains from Google, they’ve persistently emphasised the significance of distinctive content material, and we must always listen.
If particular person pages in your web site wrestle to supply distinctive data, you’re going to wrestle to win these high positions within the SERPs.
Web sites with duplicate content material endure from lowered natural search visitors and fewer listed pages, and in circumstances of manipulation, they run the danger of an algorithmic penalty. That is for just a few causes:
- Keep in mind that Googlebot isn’t a human. If it discovers 2 or extra pages with the identical content material, the algorithm then must determine which web page to rank. Although they will get this proper, they will additionally get it incorrect.
- Spreading content material throughout a number of URLs additionally spreads constructive ‘indicators’ resembling backlinks, social shares and engagement statistics. On this approach, every particular person URL advantages much less from these indicators than a single URL would.
- Duplicate content material requires Googlebot to spend extra time and sources on crawling your web site, regardless that there’s no profit for them to take action. You’re successfully losing their time (and your web site’s crawl price range).

Determine: Duplicate Content material – Writer: Seobility – License: CC BY-SA 4.0
search engine optimization already includes many components which can be out of our management, so it appears short-sighted to current a complicated mess of content material to Google and go away it as much as them to type out.
In the event you’re invited to an interview for a job you actually need, do you arrive in soiled garments, unprepared? Anybody who actually needs the place is properly offered and completely researched forward of time.
Natural search is simply changing into increasingly aggressive, so we wish to do the identical and current the very best, clearest model of our web site to Google so that they absolutely perceive it.
Widespread Causes of Duplicate Content material
Duplicate content material points can come up from quite a lot of causes. Various kinds of web sites resembling blogs, eCommerce web sites and so forth. all include a novel set of traits that may result in duplicate content material.
Under, I’ll stroll you thru a number of the commonest causes of duplicate content material that I see whereas performing technical search engine optimization audits on all kinds of shopper websites. I’ll then stroll you thru learn how to repair these points in case you uncover them by yourself web site!
Poor Content material Administration
Whereas there are completely many technical points that trigger duplicate content material, I might be remiss to not point out checking in along with your content material supervisor first.
Actually Duplicated Content material
Often, after I first check out an internet site, one of many first issues I’ll uncover is low-value, duplicate pages with URLs like:
- https://instance.com/test-page/
- https://instance.com/test-page-1/
- https://instance.com/test-page-2/
Usually, folks deliberately duplicate content material to make it simpler to create new pages with an identical format.
That is high-quality; the issue is that they neglect to scrub up.
Supply: https://ofm.od.nih.gov/
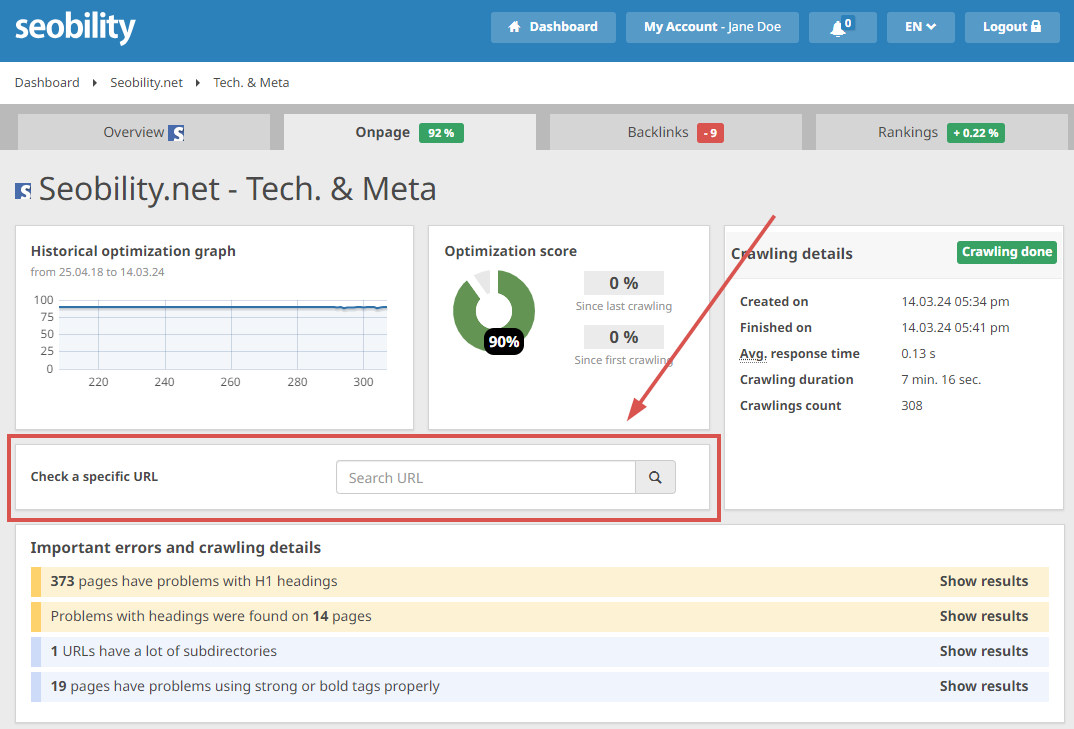
The excellent news is these are simply fastened by merely deleting the pages and serving both a 404 or 410 standing code. However earlier than you do that, be sure that there aren’t any inner hyperlinks in your web site that time to those pages, to keep away from damaged hyperlinks afterward. In the event you’re utilizing Seobility, you’ll be able to simply examine this by trying to find the URL you wish to delete within the “Verify a particular URL” search field:
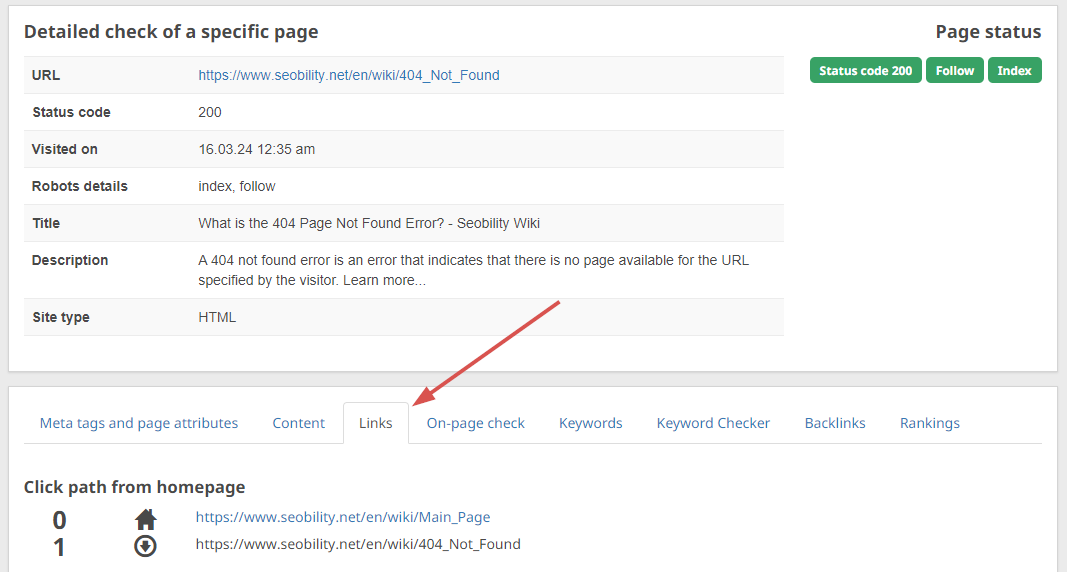
Then navigate to the “Hyperlinks” tab, to see all incoming hyperlinks to that web page:
Duplicated Touchdown Pages
Many consumers I work with are rising their natural search channels whereas working paid search and Fb adverts. To make it straightforward to generate touchdown pages for his or her adverts, they rapidly duplicate present pages.
It’s quite common to see the next:
- https://instance.com/service/
- https://instance.com/service-lp-facebook/
- https://instance.com/service-lp-googleads/
Whereas a number of the copy used on these pages is totally different from the unique, sometimes the title, meta description, and 90% of the textual content are similar.
On this state of affairs, the shopper needs to rank their /service/ web page in Google, so we actually wish to be clear within the message we’re sending to Google.
Any touchdown pages used for different sources of visitors can use the noindex directive, so that they gained’t be listed in Google’s index and gained’t compete with pages which can be “made for natural search.”
The exception to this rule is if we anticipate these different touchdown pages to earn social shares or backlinks. On this case, you’ll be able to preserve the web page indexable and set the canonical URL on all touchdown pages to the principle /service/ web page as a substitute.
The canonical URL tells Google that the principle /service/ web page is the “unique” supply of the content material that must be displayed within the search outcomes. It would additionally consolidate the constructive indicators coming from backlinks to the canonical web page.
Within the instance above, we would wish so as to add this canonical tag to the entire duplicated touchdown pages:
<hyperlink rel="canonical" href="https://instance.com/service/" />
In the event you use this methodology, do not forget that a web page shouldn’t be noindexed whereas pointing to a distinct canonical URL, to keep away from sending combined indicators to Google.
Google search advocate John Mueller confirms this:
“…you shouldn’t combine noindex & rel=canonical…they’re very contradictory items of data for us. We’ll usually decide the rel=canonical and use that over the noindex, however any time you depend on interpretation by a pc script, you cut back the load of your enter.”
Incorrect Server Configuration
Google formally introduced that HTTPS was a rating issue again in 2014, and in 2018, Google Chrome started marking internet pages loaded over HTTP as “not safe”.
All web sites must be secured, which is defined in additional element on this information on switching from HTTP to HTTPS.
For a lot of websites served over HTTPS nonetheless, an all too frequent reason for duplication comes from a scarcity of redirects, which permits the identical piece of content material to be considered at 2 or extra URLs.
In easy phrases, in case your web site is accessible by each HTTP and HTTPS, with no redirects between the 2 variations, it will end in duplicate content material. And never only for one web page, however for all of the sub-pages in your complete web site!
Your web site shouldn’t be obtainable at https://instance.com and http://instance.com.
Equally, it shouldn’t be obtainable on a subdomain in addition to the basis area, resembling https://www.instance.com and https://instance.com.
However even when you have your area dealing with sorted out, there are different culprits that may result in duplication points, resembling a easy trailing slash being hooked up to your URLs. https://instance.com/service shouldn’t be obtainable at https://instance.com/service/, and vice-versa.
For all of those situations, it’s vital to have redirects in place that mechanically redirect guests to your one most popular URL variant. This could at all times be the HTTPS model to supply a safe connection for all web site guests. From there, you’ll must determine learn how to arrange your subdomains (www or non-www generally) and permalinks (with or with out a trailing slash).
My most popular answer is to arrange web sites with out www, and at all times with a trailing slash.
In the event you’re unsure whether or not these redirects are configured appropriately in your web site, Seobility’s free Redirect Checker will provide help to discover out:
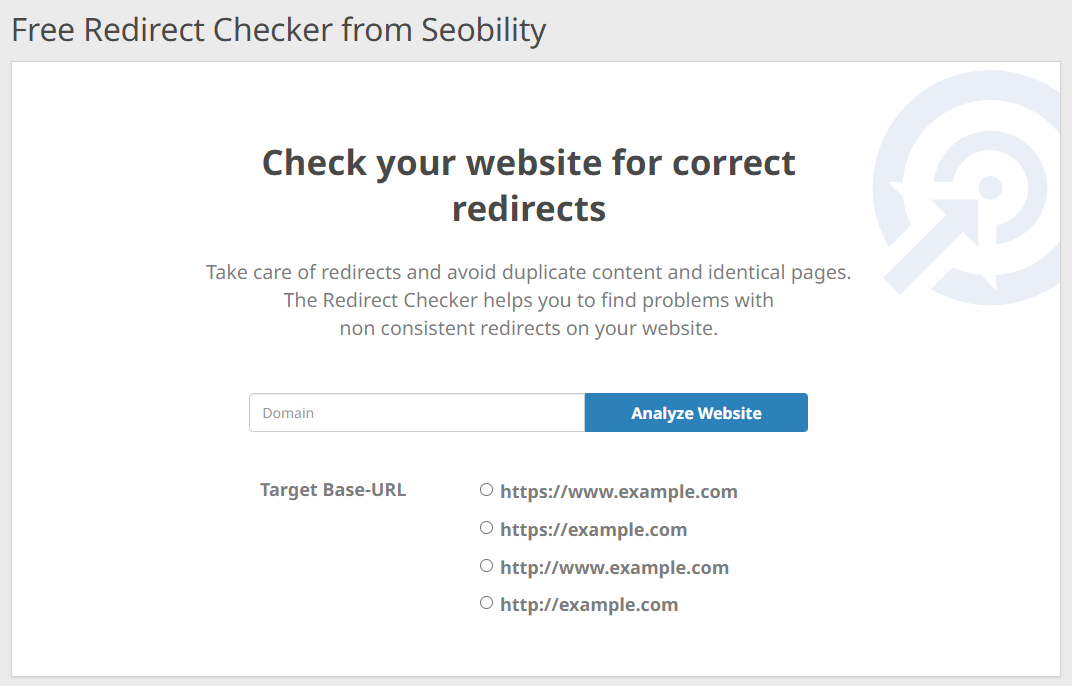
Simply enter your area and choose your most popular URL format and the device will mechanically examine in case your https/www redirects work as supposed.
On the backside of the outcomes web page, you’ll additionally discover a Redirect Generator that may generate the required code to repeat and paste into your .htaccess file on Apache or NGINX server config to arrange these guidelines appropriately, if that’s not already the case.
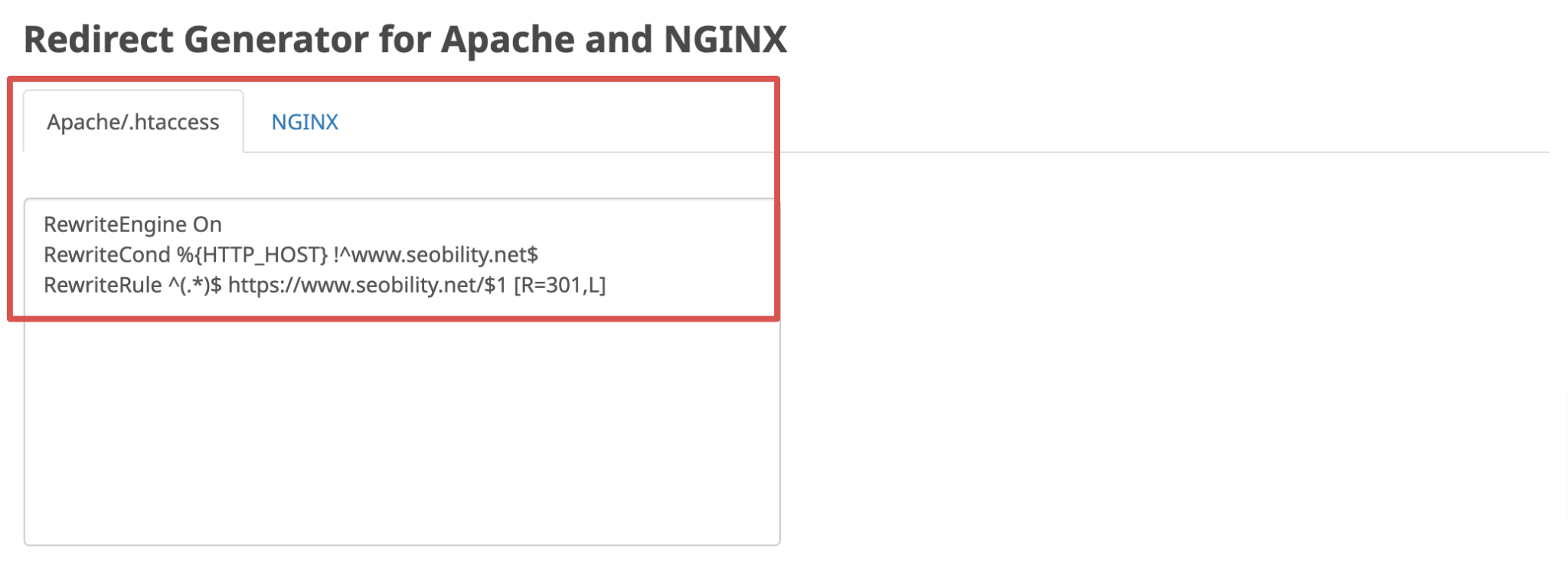
Along with establishing the redirects appropriately, you also needs to be sure that the canonical tags are right.
They typically get ignored, however in case you’re utilizing HTTPS and your canonical tag factors to HTTP, Google will index HTTP. The problem is that if HTTP then additionally redirects to HTTPS, it creates an infinite loop, which doesn’t please Google.
On WordPress, the most well-liked search engine optimization plugins, like Yoast and Rankmath, will doubtless change the canonical tags mechanically whenever you swap from HTTP to HTTPS. Nonetheless, you might need to alter the principle website tackle URL within the settings.
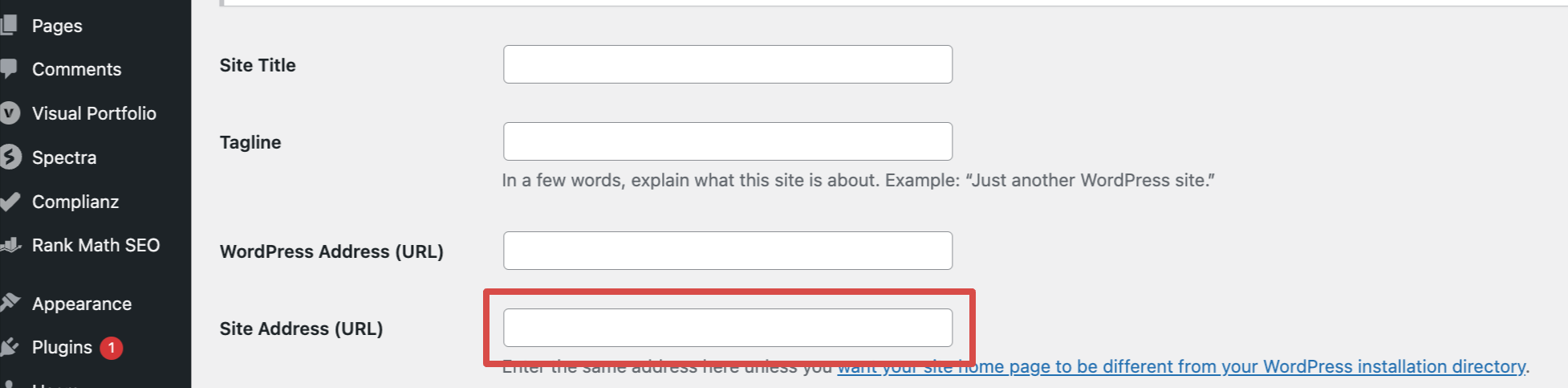
In the event you’re not utilizing an search engine optimization plugin, you’ll want so as to add/edit the canonical tags manually. They need to be added inside the <head> part of your HTML and level to the HTTPS model of every web page.
For instance, the web page https://instance.com/page-1 ought to have a self-referential canonical tag pointing to https://instance.com/page-1 (i.e. the identical URL) to make it clear that that is the web page you need Google to index.
Multi-Language Administration Points
In an identical vein to content material administration, quite a lot of content material websites have points with duplicate content material attributable to partially or wholly un-translated content material.
In the event you use WordPress, you may be aware of multi-language plugins like Polylang and WPML. These plugins make it straightforward to clone present content material in your major language with the intention of translating it into a brand new language.
In lots of circumstances although, content material is usually cloned and forgotten about, as group members don’t typically browse the positioning in a distinct language. Blocks of content material, and even complete pages and weblog posts find yourself being obtainable in English, regardless of the web page’s hreflang denoting a distinct language.
In case you are utilizing considered one of these plugins, take the time to evaluate every web page and publish of content material, in every language to make sure that 100% of it’s translated. Seobility’s Duplicate Content material Evaluation can prevent quite a lot of time right here, particularly when you have 1000’s of URLs price of content material (extra on this later).
After discovering untranslated content material, both process your content material group with translating it, translate it mechanically, or contemplate deleting that piece of untranslated content material within the particular language.
In the event you determine to delete the content material solely, be sure to:
- Take away or change any inner hyperlinks pointing to the content material (as defined within the part “Actually Duplicated Content material”)
- Alter hreflang hyperlinks out of your multi-language plugin dashboard
- Replace your sitemap if essential to replicate Google the modifications you’ve made
Product Pages on eCommerce Web sites
Ecommerce search engine optimization managers have gotten more and more detail-oriented, however for the longest time auto-generated product pages based mostly on imported product listings was the secret.
In product ranges with numerous variations, resembling automotive elements or clothes, duplicate content material could be frequent.
Right here’s an instance from the wild:
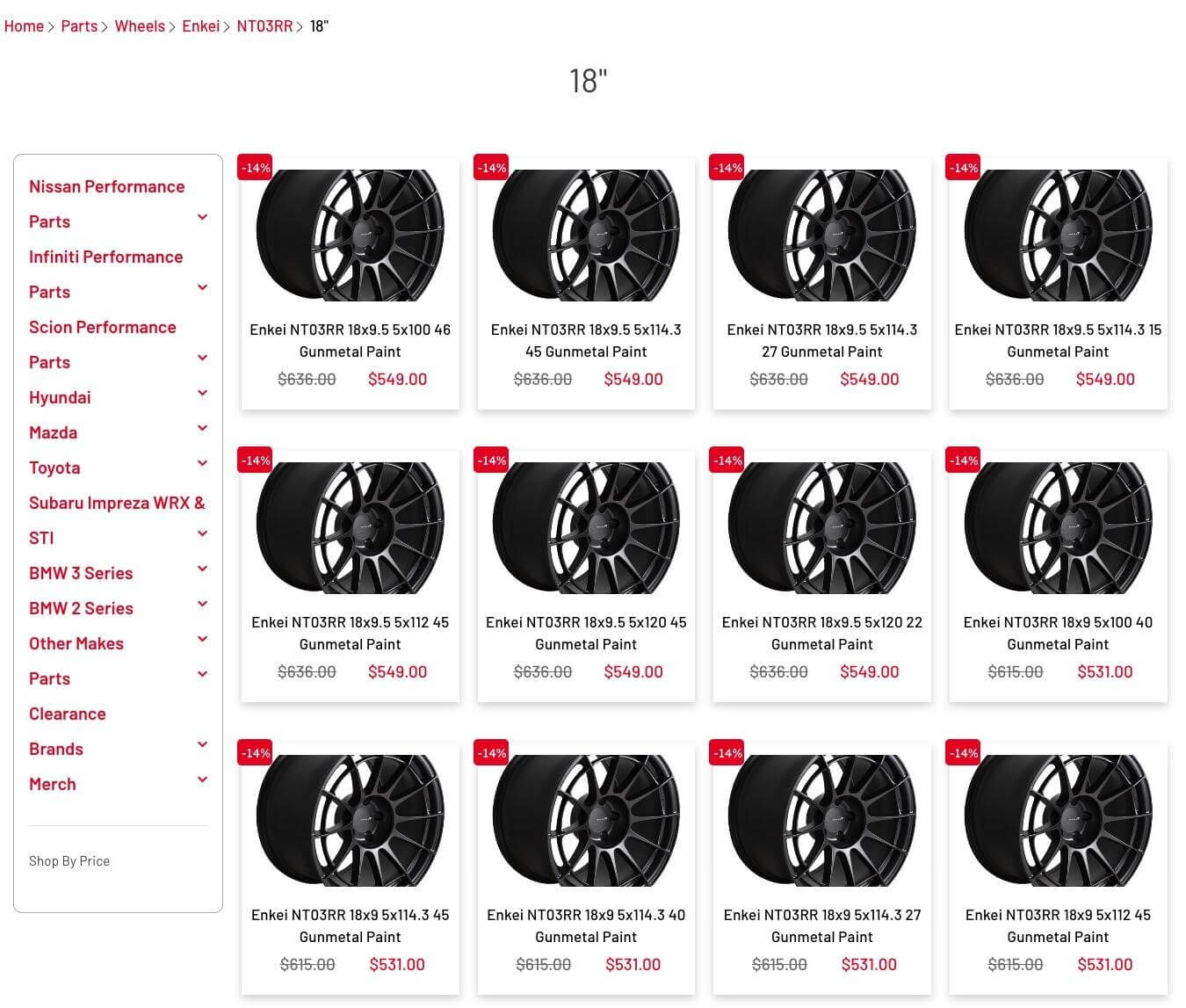
Each single product variation has a distinct URL. Although the title is partially distinctive, the picture and product descriptions are similar.
Whereas one may argue that particular person merchandise may rank for very particular long-tail key phrases (and that’s true), let’s be actual – in case you’re not taking the care to supply distinctive product information on every web page, it’s not going to carry out.
This website proprietor is much better off with a single product URL that gives 12 variations through a drop-down menu.
For extra data on learn how to optimize your eCommerce website’s product pages, together with learn how to deal with comparable merchandise in addition to product variations, take a look at Seobility’s in-depth information on search engine optimization for eCommerce product pages.
Pagination is a method used to divide giant teams of content material into a number of pages. Image the weblog residence web page on an internet site that has 2,500 weblog posts or an ecommerce web site with 200 merchandise in every of its 12 classes.
As an alternative of loading all of the content material in a single, prolonged web page that’s gradual to load and has too many hyperlinks, pagination permits customers to navigate by smaller, extra manageable chunks of content material.
By clicking by lists of posts or merchandise through hyperlinks (sometimes numbered) on the backside of every web page, person expertise, website pace, and search engine optimization are improved. Google itself offers instance of this on its outcomes pages:

Generally although, paginated class pages could have a prolonged introduction block on the web page or supporting content material under the product record, and that is repeated each time it’s paginated, creating duplicate content material.
To keep away from this, ask your self if you actually need pagination within the first place. If the content material can simply be displayed on one web page with out affecting load instances and person expertise, then you need to go for it, as it would take away quite a lot of complexity out of your website.
Nonetheless, when you have lots of or 1000’s of things in a class, this gained’t be an possibility.
On this case, you need to solely use the content material on web page 1 of your pagination and take away it from all subsequent pages. This is not going to solely keep away from duplicate content material, however can even give Google an vital trace to show web page 1 of your pagination in its search outcomes, fairly than selecting one other web page. To additional cut back the chance of Google displaying web page 4 or 5 of your pagination as a substitute of web page 1, you’ll be able to “de-optimize” the paginated pages, for instance by selecting a title resembling “Outcomes web page 4 of class …”.
If this isn’t doable attributable to technical limitations of your CMS or comparable causes, an different answer is to set all pages ranging from web page 2 of your pagination to noindex. Nonetheless, this answer has a significant downside: Google will finally cease following all hyperlinks on noindexed pages. Which means that when you have vital hyperlinks in your paginated pages (e.g. hyperlinks to product pages), you should be sure that Google can entry the linked pages in different methods earlier than implementing this answer, e.g. by offering an optimized XML Sitemap that features these hyperlinks.
One methodology of coping with paginated content material that’s typically prompt by SEOs, however which Google doesn’t suggest, is to set the canonical tag on pages 2, 3, and so forth. to the primary web page of the pagination. The aim of this methodology is to get the primary web page listed by Google and to consolidate all of the constructive rating indicators on that first web page whereas avoiding points like duplicate content material. Nonetheless, this isn’t what canonical tags are supposed for. In the event you use them on this approach, this could sign to Google that you’ve just one class web page, fairly than a paginated sequence, and because of this it could not uncover the pages listed on web page 2, 3, and so forth.
If you wish to dig deeper into this matter, this information on SEJ offers an incredible overview of search engine optimization finest practices in addition to frequent myths about pagination.
Tags, Classes and Writer Archives on WordPress Web sites
Certainly one of my favourite optimization alternatives on WordPress websites is to show shut consideration to tags, classes and creator archives.
It’s considered one of many actions we evaluate when working by our “search engine optimization launchpad” course of at Dialed Labs. None of those are inherently dangerous. It’s solely that they’re usually misused or produce very low-value pages.
Skinny Content material in Archives
Whereas this isn’t instantly associated to duplicate content material, it’s one thing that must be talked about when speaking about archive pages on WordPress web sites.
Each classes and tags are nice methods to arrange and categorize weblog posts. However many website homeowners and content material creators are unaware that WordPress mechanically creates an archive web page for every new class and tag they create.
Classes are extra intuitive, so that they appear to be used appropriately on most websites. Tags, however, appear to be seen as some form of search engine optimization powerup, the place folks attempt to use as many as doable on their posts.
Because of this, quite a few websites find yourself with an extreme variety of tags, resulting in numerous pages with skinny content material that provide subsequent to no worth.
This follow could stem from the outdated notion that “extra pages equal higher visibility.” I disagree. A small, highly effective web site that’s filled with high-value pages is my choice any day!
If this drawback sounds acquainted to you, take into consideration which tags you actually need to your website and preserve solely these. You probably have tags that solely include 1-2 articles, readers who wish to discover extra of your website’s content material gained’t discover a lot worth in these tags.
Tags that don’t add worth to guests might be deleted solely, however be sure to redirect the URLs to an identical web page if they’ve exterior hyperlinks pointing to them.
In the event you don’t wish to delete the pages, you may as well contemplate setting them to noindex. The preferred WordPress search engine optimization plugins, resembling Yoast search engine optimization and Rankmath, make it straightforward to noindex these pages from their plugin settings.
An exception to the noindex rule is when the archive pages are incomes natural visitors on their very own. For instance, your creator may be a well-known creator whose title will get searched naturally. In circumstances like this, you wish to preserve the web page listed to proceed gaining visitors from Google.
Duplicate Content material in Archives
As if skinny content material wasn’t sufficient, archive pages also can result in duplicate content material points if not dealt with correctly.
In website themes that don’t restrict archive pages to utilizing solely an excerpt of content material, weblog content material might be displayed in its entirety on the house web page, in an creator archive, class archive and a number of tag archives earlier than we even contemplate the precise publish URL.
An exception to the noindex rule is when the archive pages are incomes natural visitors on their very own. For instance, your creator may be a well-known creator whose title will get searched naturally. In circumstances like this, you wish to preserve the web page listed to proceed gaining visitors from Google.

The above picture exhibits when an creator web page is displaying an excessive amount of of the article content material (no excerpt restrict), resulting in duplicate content material points.
Any content material displayed on class/creator/tag archive pages ought to solely use a small excerpt to keep away from duplication. You are able to do this by utilizing the built-in ”Extra” block” in WordPress, which is able to mechanically make the excerpt solely 10-25 phrases. For the earlier picture, that is how the distinction would appear to be:

One other reason for duplicates in archive pages are redundant tags and classes. For instance, in case you run a digital advertising and marketing weblog and you’ve got a class known as ‘content material advertising and marketing’, however you additionally create a tag for ‘content material advertising and marketing ideas’, then each pages are more likely to include the identical articles, leading to duplicate content material.
To keep away from this, be sure to use distinctive tags and classes that don’t repeat one another and preserve this categorization system as clear as doable. Your classes must be extra normal and point out the broad matter of your posts, whereas tags are normally extra particular and assist folks discover comparable content material after studying considered one of your posts.
In case your web site already suffers from duplicate content material points attributable to redundant classes and tags, it’s time for a clear up. As described within the part “Skinny Content material in Archives”, take into consideration which of those pages you actually need and delete / noindex the whole lot that doesn’t present worth.
Easy methods to Uncover Duplicate Content material
One of many quickest methods to determine duplicate content material is thru software program. An auditing device like Seobility, which crawls each web page in your website, is far sooner than trawling for duplicate content material manually.
If you kick off a Web site Audit in Seobility, the device will mechanically examine your web site for every type of technical and on-page search engine optimization points, together with varied levels of duplicate content material.
In the event you’re already a person, yow will discover this by the Onpage > Content material > Duplicate content material part.
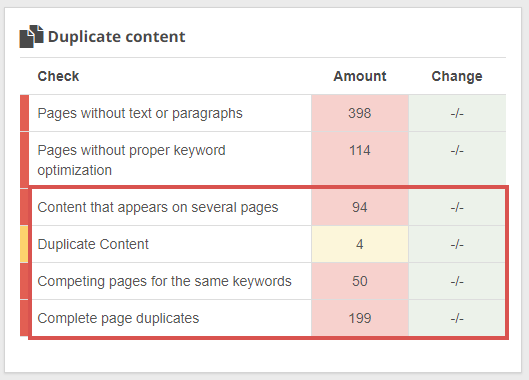
Inside Seobility, the kinds of duplicate content material which can be checked are outlined as:
- Full web page duplicates: similar pages, right down to the HTML
- Duplicate Content material: pages with similar textual content content material (however not full HTML duplicates)
- Content material that seems on a number of pages: textual content blocks which can be used on a number of pages
- Competing pages for a similar key phrases: key phrase cannibalization
Whereas key phrase cannibalization isn’t strictly a replica content material situation, it’s carefully associated and completely price reviewing by a content material audit.
Monitor and Audit Your Content material Efficiency
Content material duplication can critically damage your search engine optimization efforts, impeding crawl effectivity and tanking your rankings.
The excellent news is that easy proactive measures may also help you determine and resolve duplicate content material points, safeguarding your web site’s place within the SERPs.
Join a free 14-day trial of Seobility and begin an internet site audit right this moment to make certain that you’ll uncover any bother with duplicate content material in your website earlier than Google does!
PS: Get weblog updates straight to your inbox!