
Language fashions (LMs) are a cornerstone of synthetic intelligence analysis, specializing in the power to grasp and generate human language. Researchers intention to reinforce these fashions to carry out numerous complicated duties, together with pure language processing, translation, and inventive writing. This area examines how LMs study, adapt, and scale their capabilities with growing computational assets. Understanding these scaling behaviors is crucial for predicting future capabilities and optimizing the assets required for coaching and deploying these fashions.
The first problem in language mannequin analysis is knowing how mannequin efficiency scales with the quantity of computational energy and information used throughout coaching. This scaling is essential for predicting future capabilities and optimizing useful resource use. Conventional strategies require intensive coaching throughout a number of scales, which is computationally costly and time-consuming. This creates a major barrier for a lot of researchers and engineers who want to grasp these relationships to enhance mannequin improvement and software.
Present analysis contains numerous frameworks and fashions for understanding language mannequin efficiency. Notable amongst these are compute scaling legal guidelines, which analyze the connection between computational assets and mannequin capabilities. Instruments just like the Open LLM Leaderboard, LM Eval Harness, and benchmarks like MMLU, ARC-C, and HellaSwag are generally used. Furthermore, fashions equivalent to LLaMA, GPT-Neo, and BLOOM present various examples of how scaling legal guidelines might be practiced. These frameworks and benchmarks assist researchers consider and optimize language mannequin efficiency throughout totally different computational scales and duties.
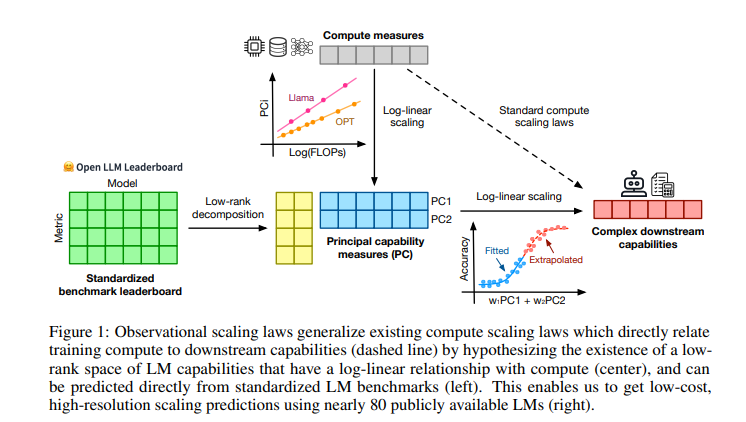
Researchers from Stanford College, College of Toronto, and Vector Institute launched observational scaling legal guidelines to enhance language mannequin efficiency predictions. This methodology makes use of publicly accessible fashions to create scaling legal guidelines, lowering the necessity for intensive coaching. By leveraging current information from roughly 80 fashions, the researchers may construct a generalized scaling legislation that accounts for variations in coaching compute efficiencies. This revolutionary method provides an economical and environment friendly method to predict mannequin efficiency throughout totally different scales and capabilities, setting it other than conventional scaling strategies.
The methodology analyzes efficiency information from about 80 publicly accessible language fashions, together with the Open LLM Leaderboard and standardized benchmarks equivalent to MMLU, ARC-C, and HellaSwag. The researchers hypothesized that mannequin efficiency might be mapped to a low-dimensional functionality house. They developed a generalized scaling legislation by analyzing variations in coaching compute efficiencies amongst totally different mannequin households. This course of concerned utilizing principal element evaluation (PCA) to establish key functionality measures and becoming these measures right into a log-linear relationship with compute assets, enabling correct and high-resolution efficiency predictions.
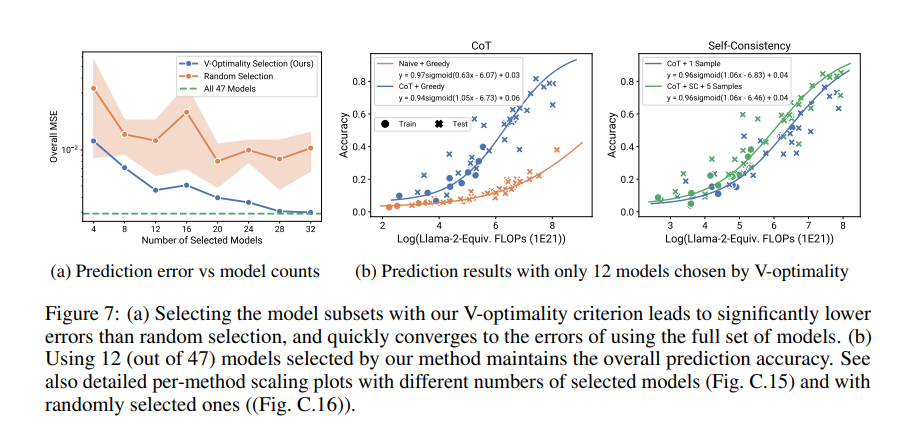
The analysis demonstrated important success with observational scaling legal guidelines. For example, utilizing less complicated fashions, the tactic precisely predicted the efficiency of superior fashions like GPT-4. Quantitatively, the scaling legal guidelines confirmed a excessive correlation (R² > 0.9) with precise efficiency throughout numerous benchmarks. Emergent phenomena, equivalent to language understanding and reasoning skills, adopted a predictable sigmoidal sample. The outcomes additionally indicated that the impression of post-training interventions, like Chain-of-Thought and Self-Consistency, might be reliably predicted, displaying efficiency enhancements of as much as 20% in particular duties.
To conclude, the analysis introduces observational scaling legal guidelines, leveraging publicly accessible information from round 80 fashions to foretell language mannequin efficiency effectively. By figuring out a low-dimensional functionality house and utilizing generalized scaling legal guidelines, the research reduces the necessity for intensive mannequin coaching. The outcomes confirmed excessive predictive accuracy for superior mannequin efficiency and post-training interventions. This method saves computational assets and enhances the power to forecast mannequin capabilities, providing a helpful device for researchers and engineers in optimizing language mannequin improvement.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 42k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.