
The pure language processing (NLP) discipline is constantly evolving, with massive language fashions (LLMs) changing into integral to many functions. The push in direction of fine-tuning these fashions has turn into essential to boost their particular capabilities with out requiring in depth computational assets. Researchers have just lately explored methods to change LLMs to make sure they carry out optimally, even with restricted computational assets. One key growth is Low-Rank Adaptation (LoRA), a Parameter Environment friendly Superb-Tuning (PEFT) methodology that has proven promise in enhancing specialised fashions to outperform bigger, extra generalized ones. This methodology reduces the variety of trainable parameters, lowers reminiscence utilization, and retains accuracy.
The problem of fine-tuning is sustaining efficiency with out extreme computational demand. The analysis crew’s method revolves round leveraging LoRA, which introduces low-rank matrices to current layers of frozen mannequin weights. This methodology permits specialised fashions to realize efficiency ranges akin to full fine-tuning with no need a excessive variety of trainable parameters. LoRA has demonstrated its effectiveness throughout totally different duties, permitting researchers to maximise effectivity.
Researchers from Predibase launched LoRA Land, a complete venture that evaluates fine-tuned LLMs throughout numerous duties. The analysis crew used 10 base fashions and 31 duties to fine-tune 310 fashions. The duties included traditional NLP, coding, knowledge-based reasoning, and math-based issues. This effort was supported by LoRAX, the open-source inference server designed particularly for serving a number of LoRA fine-tuned LLMs. The server allows the simultaneous use of a number of fashions by leveraging shared base weights and dynamic adapter loading, thus permitting quite a few fashions to be deployed on a single GPU.

To validate the proposed methodology, the analysis crew performed experiments utilizing LoRA with 4-bit quantization on the bottom fashions, attaining outstanding outcomes. They discovered that LoRA-based fine-tuned fashions outperformed their base fashions considerably, with efficiency enhancements averaging over 34 factors. Some fashions even surpassed GPT-4 by 10 factors on common throughout totally different duties. The researchers meticulously standardized their testing framework, making certain consistency in fine-tuning parameters and queries to supply a good evaluation throughout fashions. LoRAX’s deployment capabilities have been completely evaluated, highlighting its capability to effectively handle a number of fashions concurrently. With options like dynamic adapter loading and tiered weight caching, it achieved excessive concurrency ranges whereas sustaining minimal latency.
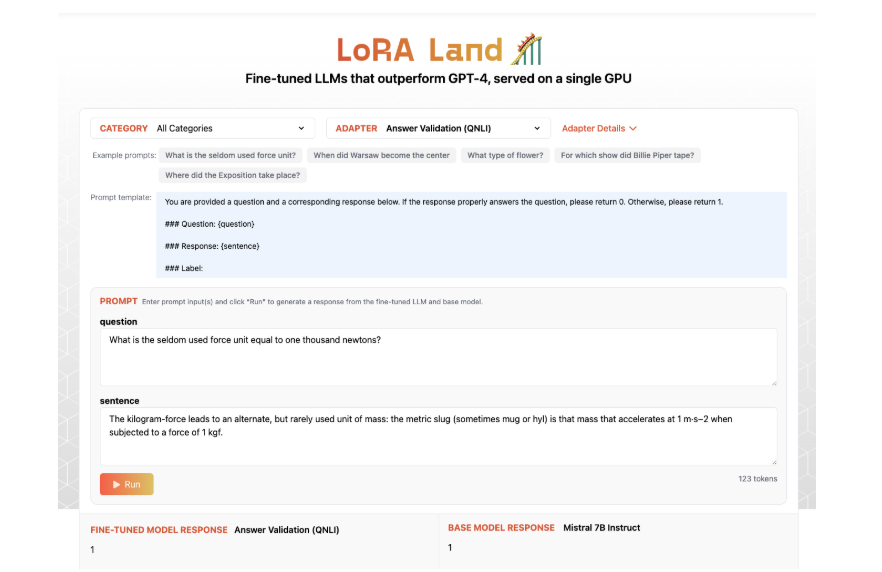
The venture’s outcomes revealed a considerable efficiency increase from fine-tuning, which persistently and considerably enhanced LLM efficiency. Throughout all 310 fashions, the fine-tuned variations surpassed their base counterparts, with 224 fashions exceeding the benchmark set by GPT-4. On common, fine-tuned fashions carried out higher than non-fine-tuned fashions by as much as 51.2 factors. This examine confirmed that fine-tuning with LoRA could be exceptionally efficient, notably for specialised duties the place a smaller mannequin can outperform even the biggest fashions like GPT-4.

In conclusion, the LoRA Land venture highlighted the effectiveness of LoRA in fine-tuning massive language fashions, making them appropriate for numerous specialised duties. The examine, protecting 310 fashions fine-tuned throughout 31 duties, demonstrated the effectivity and scalability of LoRA and its capability to match or surpass GPT-4’s efficiency in sure areas. LoRAX, the inference server used on this examine, might deal with many fashions concurrently on a single GPU, underscoring the potential of effectively deploying a number of fine-tuned fashions. The venture emphasizes some great benefits of specialised LLMs and the viability of LoRAX for future AI functions.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our 41k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.