
We’re thrilled to announce Unity Catalog Lakeguard, which lets you run Apache Spark™ workloads in SQL, Python, and Scala with full knowledge governance on the Databricks Knowledge Intelligence Platform’s cost-efficient, multi-user compute. To implement governance, historically, you had to make use of single-user clusters, which provides value and operational overhead. With Lakeguard, consumer code runs in full isolation from another customers’ code and the Spark engine on shared compute, thus imposing knowledge governance at runtime. This lets you securely share clusters throughout your groups, decreasing compute value and minimizing operational toil.
Lakeguard has been an integral a part of Unity Catalog since its introduction: we steadily expanded the capabilities to run arbitrary code on shared clusters, with Python UDFs in DBR 13.1, Scala assist in DBR 13.3 and eventually, Scala UDFs with DBR 14.3. Python UDFs in Databricks SQL warehouses are additionally secured by Lakegaurd! With that, Databricks clients can run workloads in SQL, Python and Scala together with UDFs on multi-user compute with full knowledge governance.
On this weblog publish, we give an in depth overview of Unity Catalog’s Lakeguard and the way it enhances Apache Spark™ with knowledge governance.
Lakeguard enforces knowledge governance for Apache Spark™
Apache Spark is the world’s hottest distributed knowledge processing framework. As Spark utilization grows alongside enterprises’ concentrate on knowledge, so does the necessity for knowledge governance. For instance, a standard use case is to restrict the visibility of information between completely different departments, similar to finance and HR, or safe PII knowledge utilizing fine-grained entry controls similar to views or column and row-level filters on tables. For Databricks clients, Unity Catalog gives complete governance and lineage for all tables, views, and machine studying fashions on any cloud.
As soon as knowledge governance is outlined in Unity Catalog, governance guidelines should be enforced at runtime. The largest technical problem is that Spark doesn’t supply a mechanism for isolating consumer code. Completely different customers share the identical execution setting, the Java Digital Machine (JVM), opening up a possible path for leaking knowledge throughout customers. Cloud-hosted Spark providers get round this downside by creating devoted per-user clusters, which carry two main issues: elevated infrastructure prices and elevated administration overhead since directors need to outline and handle extra clusters. Moreover, Spark has not been designed with fine-grained entry management in thoughts: when querying a view, Spark “overfetches” information, i.e fetches all information of the underlying tables utilized by the view. As a consequence, customers may probably learn knowledge they haven’t been granted entry to.
At Databricks, we solved this downside with shared clusters utilizing Lakeguard underneath the hood. Lakeguard transparently enforces knowledge governance on the compute degree, making certain that every consumer’s code runs in full isolation from another consumer’s code and the underlying Spark engine. Lakeguard can also be used to isolate Python UDFs within the Databricks SQL warehouse. With that, Databricks is the industry-first and solely platform that helps safe sharing of compute for SQL, Python and Scala workloads with full knowledge governance, together with enforcement of fine-grained entry management utilizing views and column-level & row-level filters.
Lakeguard: Isolating consumer code with state-of-the-art sandboxing
To implement knowledge governance on the compute degree, we developed our compute structure from a safety mannequin the place customers share a JVM to a mannequin the place every consumer’s code runs in full isolation from one another and the underlying Spark engine in order that knowledge governance is all the time enforced. We achieved this by isolating all consumer code from (1) the Spark driver and (2) the Spark executors. The picture under exhibits how within the conventional Spark structure (left) customers’ consumer functions share a JVM with privileged entry to the underlying machine, whereas with Shared Clusters (proper), all consumer code is totally remoted utilizing safe containers. With this structure, Databricks securely runs a number of workloads on the identical cluster, providing a collaborative, cost-efficient, and safe resolution.
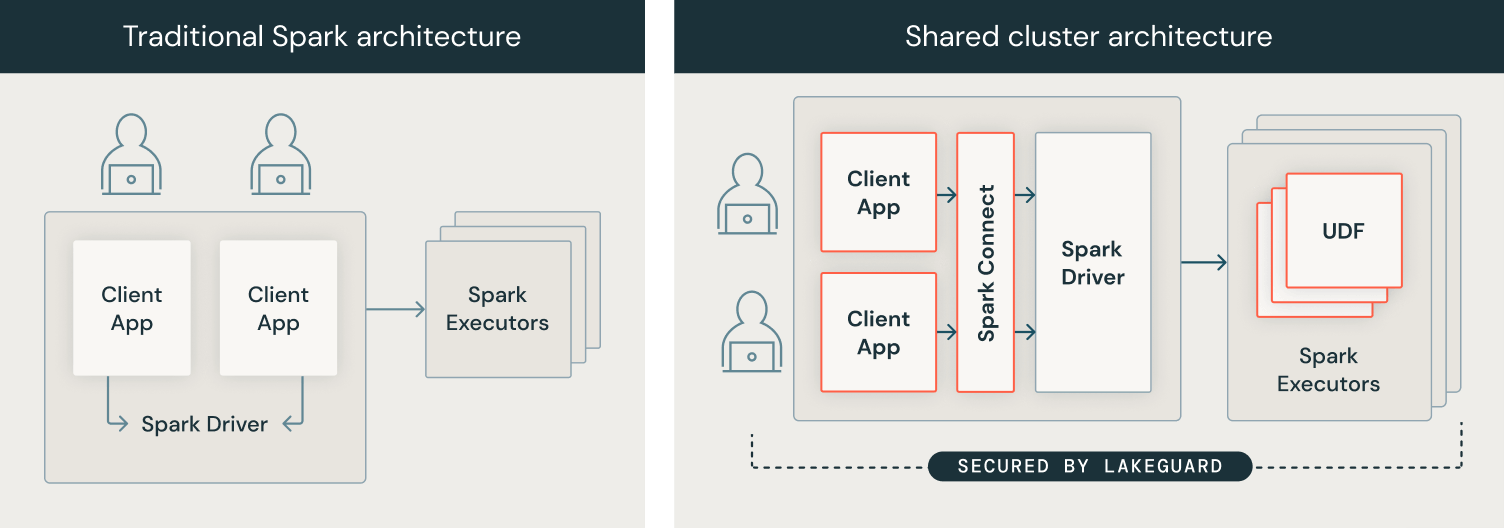
Spark Consumer: Person code isolation with Spark Join and sandboxed consumer functions
To isolate the consumer functions from the Spark driver, we needed to first decouple the 2 after which isolate the person consumer functions from one another and the underlying machine, with the aim of introducing a completely trusted and dependable boundary between particular person customers and Spark:
- Spark Join: To attain consumer code isolation on the consumer aspect, we use Spark Join that was open-sourced in Apache Spark 3.4. Spark Join was launched to decouple the consumer utility from the driving force in order that they now not share the identical JVM or classpath, and could be developed and run independently, main to raised stability, upgradability and enabling distant connectivity. Through the use of this decoupled structure, we will implement fine-grained entry management, as “over-fetched” knowledge used to course of queries over views or tables with row-level/column-level filters can now not be accessed from the consumer utility.
- Sandboxing consumer functions: As a subsequent step, we enforced that particular person consumer functions, i.e. consumer code, couldn’t entry one another’s knowledge or the underlying machine. We did this by constructing a light-weight sandboxed execution setting for consumer functions utilizing state-of-the-art sandboxing strategies based mostly on containers. At present, every consumer utility runs in full isolation in its personal container.
Spark Executors: Sandboxed executor isolation for UDFs
Equally to the Spark driver, Spark executors don’t implement isolation of user-defined features (UDF). For instance, a Scala UDF may write arbitrary information to the file system due to privileged entry to the machine. Analogously to the consumer utility, we sandboxed the execution setting on Spark executors as a way to securely run Python and Scala UDFs. We additionally isolate the egress community site visitors from the remainder of the system. Lastly, for customers to have the ability to use their libraries in UDFs, we securely replicate the consumer setting into the UDF sandboxes. Consequently, UDFs on shared clusters run in full isolation, and Lakeguard can also be used for Python UDFs within the Databricks SQL knowledge warehouse.
Save time and price at this time with Unity Catalog and Shared Clusters
We invite you to strive Shared Clusters at this time to collaborate along with your workforce and save value. Lakeguard is an integral part of Unity catalog and has been enabled for all clients utilizing Shared Clusters, Delta Reside Tables (DLT) and Databricks SQL with Unity Catalog.