
Giant capability fashions, akin to Giant Language Fashions (LLMs) and Giant Multi-modal Fashions (LMMs), have demonstrated effectiveness throughout varied domains and duties. Scaling up these fashions by rising parameter depend enhances efficiency however considerably reduces inference velocity, limiting practicality. Sparse Mixtures of Consultants (SMoE) supply a promising different, enabling mannequin scalability whereas mitigating computational prices. Nonetheless, SMoE faces two key challenges: i) low knowledgeable activation and ii) restricted analytical capabilities, which hinder its effectiveness and scalability.
SMoE enhances mannequin capability whereas sustaining fixed computational demand, yielding superior efficiency in comparison with densely-activated fashions. In contrast to dense fashions, SMoE employs N-independent Feed-Ahead Networks (FFN) as consultants inside every Combination-of-Consultants (MoE) layer and a gating operate to distribute weights over these consultants’ outputs. The routing mechanism selects the top-k consultants from N consultants, the place ok << N facilitates information and knowledgeable parallelism. Bigger ok values typically enhance mannequin efficiency however can scale back coaching effectivity.
Researchers from Tsinghua College and Microsoft Analysis introduce Multi-Head Combination-of-Consultants (MH-MoE). MH-MoE utilises a multi-head mechanism to divide every enter token into a number of sub-tokens and distribute them throughout completely different consultants, reaching denser knowledgeable activation with out rising computational or parameter complexity. In distinction to SMoE, MH-MoE prompts 4 consultants for a single enter token by splitting it into 4 sub-tokens. This allocation allows the mannequin to concentrate on varied illustration areas inside consultants, facilitating a extra nuanced understanding of imaginative and prescient and language patterns.

The structure of MH-MoE addresses problems with low knowledgeable activation and token ambiguity by using a multi-head mechanism to separate tokens into sub-tokens and route them to varied consultants. In MH-MoE, every parallel layer comprises a set of N consultants, with a multi-head layer projecting inputs adopted by token splitting and gating features to route sub-tokens to consultants. The highest-k routing mechanism prompts consultants with the best scores, and the ensuing sub-tokens are processed by these activated consultants and rearranged earlier than token merging to keep up input-output form consistency. The Token-Splitting-Merging (TSM) operation will increase the information quantity routed to particular consultants, leading to denser knowledgeable activation and improved understanding. This course of ensures no extra computational value in subsequent blocks, with a hyperparameter β used to steadiness parameters and computational complexity with the unique SMoE.

The validation perplexity curves for all pretrained fashions and pre-training duties are examined beneath two knowledgeable settings (8 consultants and 32 consultants). MH-MoE persistently maintains decrease perplexity than the baselines throughout varied experimental setups, indicating simpler studying. Additionally, rising the variety of consultants correlates with a lower in perplexity for MH-MoE, suggesting enhanced illustration studying capabilities. Downstream analysis throughout completely different pre-training duties additional validates the efficacy of MH-MoE. In English-focused language modeling, MH-MoE achieves the most effective efficiency throughout a number of benchmarks, demonstrating its effectiveness in enhancing language illustration. Equally, MH-MoE outperforms X-MoE persistently in multi-lingual language modeling, showcasing its superiority in modeling cross-lingual pure language. In masked multi-modal modeling duties akin to visible query answering, visible reasoning, and picture captioning, MH-MoE persistently outperforms Dense and X-MoE baselines, underscoring its skill to seize numerous semantic and detailed info inside visible information.
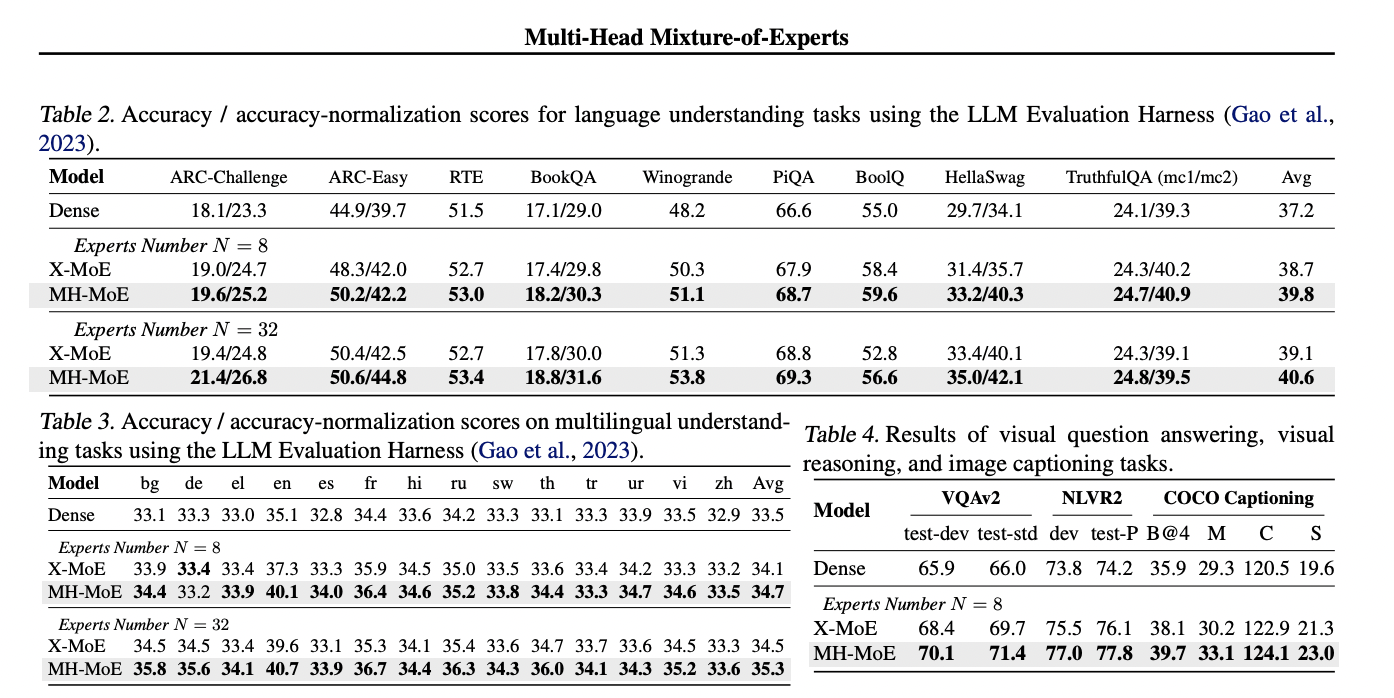
In conclusion, This paper investigates strategies for reaching denser knowledgeable activation with out introducing extra value whereas enhancing fine-grained understanding skill. The proposed MH-MoE affords an easy implementation of those functionalities. Additionally, MH-MoE’s simplicity facilitates seamless integration with different SMoE frameworks, enhancing efficiency simply. In depth empirical outcomes throughout three duties validate the effectiveness of MH-MoE in reaching these aims.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 40k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.