
We’re excited to introduce vector search on Rockset to energy quick and environment friendly search experiences, personalization engines, fraud detection techniques and extra. To focus on these new capabilities, we constructed a search demo utilizing OpenAI to create embeddings for Amazon product descriptions and Rockset to generate related search outcomes. Within the demo, you’ll see how Rockset delivers search ends in 15 milliseconds over hundreds of paperwork.
Watch this tech discuss with me and Rockset VP of Engineering Louis Brandy From Spam Preventing at Fb to Vector Search at Rockset: The best way to Construct Actual-Time Machine Studying at Scale.
Why use vector search?
Organizations have continued to build up massive portions of unstructured information, starting from textual content paperwork to multimedia content material to machine and sensor information. Estimates present that unstructured information represents 80% of all generated information, however organizations solely leverage a small fraction of it to extract invaluable insights, energy decision-making and create immersive experiences. Comprehending and understanding the best way to leverage unstructured information has remained difficult and dear, requiring technical depth and area experience. As a consequence of these difficulties, unstructured information has remained largely underutilized.
With the evolution of machine studying, neural networks and huge language fashions, organizations can simply rework unstructured information into embeddings, generally represented as vectors. Vector search operates throughout these vectors to establish patterns and quantify similarities between elements of the underlying unstructured information.
Earlier than vector search, search experiences primarily relied on key phrase search, which regularly concerned manually tagging information to establish and ship related outcomes. The method of manually tagging paperwork requires a bunch of steps like creating taxonomies, understanding search patterns, analyzing enter paperwork, and sustaining customized rule units. For instance, if we wished to seek for tagged key phrases to ship product outcomes, we would wish to manually tag “Fortnite” as a ”survival sport” and ”multiplayer sport.” We’d additionally have to establish and tag phrases with similarities to “survival sport” like “battle royale” and “open-world play” to ship related search outcomes.
Extra not too long ago, key phrase search has come to depend on time period proximity, which depends on tokenization. Tokenization entails breaking down titles, descriptions and paperwork into particular person phrases and parts of phrases, after which time period proximity features ship outcomes primarily based on matches between these particular person phrases and search phrases. Though tokenization reduces the burden of manually tagging and managing search standards, key phrase search nonetheless lacks the power to return semantically comparable outcomes, particularly within the context of pure language which depends on associations between phrases and phrases.
With vector search, we will leverage textual content embeddings to seize semantic associations throughout phrases, phrases and sentences to energy extra strong search experiences. For instance, we will use vector search to seek out video games with “area and journey, open-world play and multiplayer choices.” As an alternative of manually tagging every sport with this potential standards or tokenizing every sport description to seek for precise outcomes, we’d use vector search to automate the method and ship extra related outcomes.
How do embeddings energy vector search?
Embeddings, represented as arrays or vectors of numbers, seize the underlying that means of unstructured information like textual content, audio, photographs and movies in a format extra simply understood and manipulated by computational fashions.
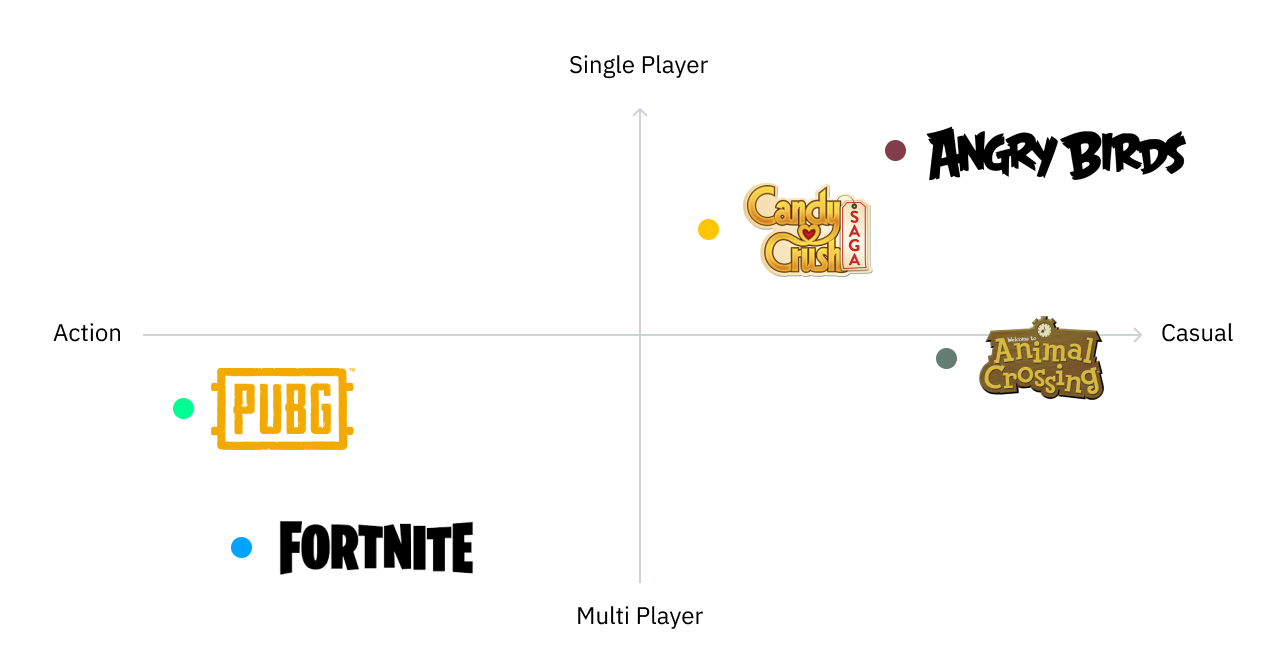
For instance, I might use embeddings to grasp the connection between phrases like “Fortnite,” “PUBG” and “Battle Royale.” Fashions derive that means from these phrases by creating embeddings for them, which group collectively when mapped to a multi-dimensional area. In a two-dimensional area, a mannequin would generate particular coordinates (x, y) for every time period, after which we’d perceive the similarity between these phrases by measuring the distances and angles between them.
In real-world functions, unstructured information can include billions of information factors and translate into embeddings with hundreds of dimensions. Vector search analyzes some of these embeddings to establish phrases in shut proximity to one another equivalent to “Fortnite” and “PUBG” in addition to phrases that could be in even nearer proximity to one another and synonyms like “PlayerUnknown’s Battlegrounds” and the related acronym “PUBG.”
Vector search has seen an explosion in reputation as a result of enhancements in accuracy and broadened accessibility to the fashions used to generate embeddings. Embedding fashions like BERT have led to exponential enhancements in pure language processing and understanding, producing embeddings with hundreds of dimensions. OpenAI’s textual content embedding mannequin, text-embedding-ada-002, generates embeddings with 1,526 dimensions, making a wealthy illustration of the underlying language.
Powering quick and environment friendly search with Rockset
Given we have now embeddings for our unstructured information, we will flip in direction of vector search to establish similarities throughout these embeddings. Rockset gives quite a lot of out-of-the-box distance features, together with dot product, cosine similarity, and Euclidean distance, to calculate the similarity between embeddings and search inputs. We are able to use these similarity scores to help Ok-Nearest Neighbors (kNN) search on Rockset, which returns the ok most comparable embeddings to the search enter.
Leveraging the newly launched vector operations and distance features, Rockset now helps vector search capabilities. Rockset extends its real-time search and analytics capabilities to vector search, becoming a member of different vector databases like Milvus, Pinecone and Weaviate and options equivalent to Elasticsearch, in indexing and storing vectors. Underneath the hood, Rockset makes use of its Converged Index expertise, which is optimized for metadata filtering, vector search and key phrase search, supporting sub-second search, aggregations and joins at scale.
Rockset gives an a variety of benefits together with vector search help to create related experiences:
- Actual-Time Knowledge: Ingest and index incoming information in real-time with help for updates.
- Function Era: Remodel and mixture information in the course of the ingest course of to generate complicated options and scale back information storage volumes.
- Quick Search: Mix vector search and selective metadata filtering to ship quick, environment friendly outcomes.
- Hybrid Search Plus Analytics: Be part of different information along with your vector search outcomes to ship wealthy and extra related experiences utilizing SQL.
- Absolutely-Managed Cloud Service: Run all of those processes on a horizontally scalable, extremely obtainable cloud-native database with compute-storage and compute-compute separation for cost-efficient scaling.
Constructing Product Search Suggestions
Let’s stroll by the best way to run semantic search utilizing OpenAI and Rockset to seek out related merchandise on Amazon.com.
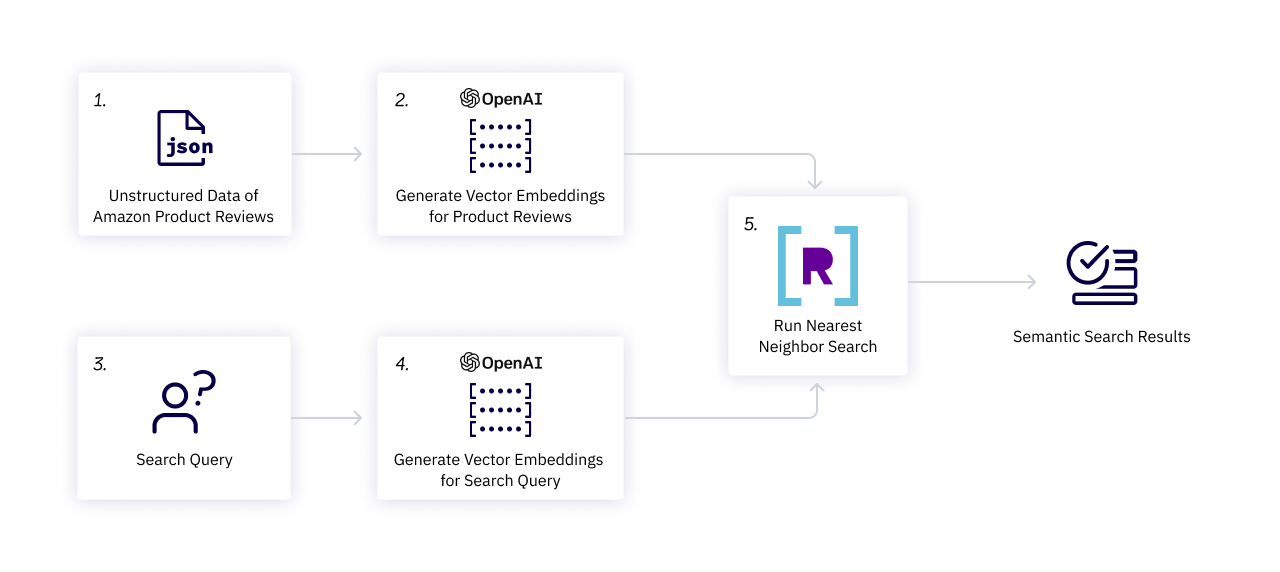
For this demonstration, we used product information that Amazon has made obtainable to the general public, together with product listings and opinions.
Generate Embeddings
The primary stage of this walkthrough entails utilizing OpenAI’s textual content embeddings API to generate embeddings for Amazon product descriptions. We opted to make use of OpenAI’s text-embedding-ada-002 mannequin as a result of its efficiency, accessibility and diminished embedding dimension. Although, we might have used quite a lot of different fashions to generate these embeddings, and we thought of a number of fashions from HuggingFace, which customers can run domestically.
OpenAI’s mannequin generates an embedding with 1,536 components. On this walkthrough, we’ll generate and save embeddings for 8,592 product descriptions of video video games listed on Amazon. We will even create an embedding for the search question used within the demonstration, “area and journey, open-world play and multiplayer choices.”
We use the next code to generate the embeddings:
Embedded content material: https://gist.github.com/julie-mills/a4e1ac299159bb72e0b1b2f121fa97ea
Add Embeddings to Rockset
Within the second step, we’ll add these embeddings, together with the product information, to Rockset and create a brand new assortment to start out working vector search. Right here’s how the method works:
We create a set in Rockset by importing the file created earlier with the online game product listings and related embeddings. Alternatively, we might have simply pulled the info from different storage mechanisms, like Amazon S3 and Snowflake, or streaming providers, like Kafka and Amazon Kinesis, leveraging Rockset’s built-in connectors. We then leverage Ingest Transformations to remodel the info in the course of the ingest course of utilizing SQL. We use Rockset’s new VECTOR_ENFORCE perform to validate the size and components of incoming arrays, which guarantee compatibility between vectors throughout question execution.
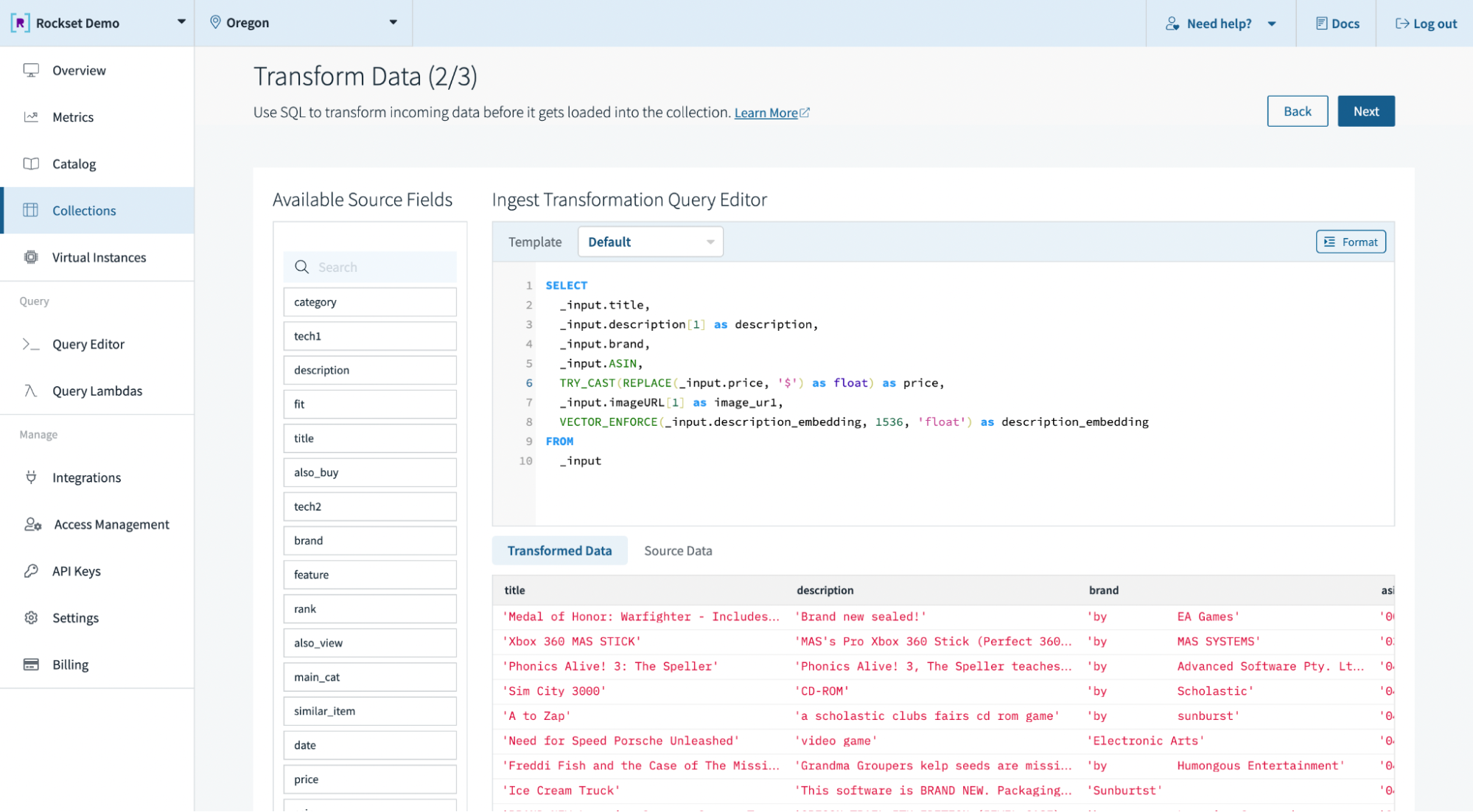
Run Vector Search on Rockset
Let’s now run vector search on Rockset utilizing the newly launched distance features. COSINE_SIM takes within the description embeddings subject as one argument and the search question embedding as one other. Rockset makes all of this attainable and intuitive with full-featured SQL.
For this demonstration, we copied and pasted the search question embedding into the COSINE_SIM perform throughout the SELECT assertion. Alternatively, we might have generated the embedding in actual time by immediately calling the OpenAI Textual content Embedding API and passing the embedding to Rockset as a Question Lambda parameter.
As a consequence of Rockset’s Converged Index, kNN search queries carry out notably effectively with selective, metadata filtering. Rockset applies these filters earlier than computing the similarity scores, which optimizes the search course of by solely calculating scores for related paperwork. For this vector search question, we filter by worth and sport developer to make sure the outcomes reside inside a specified worth vary and the video games are playable on a given system.
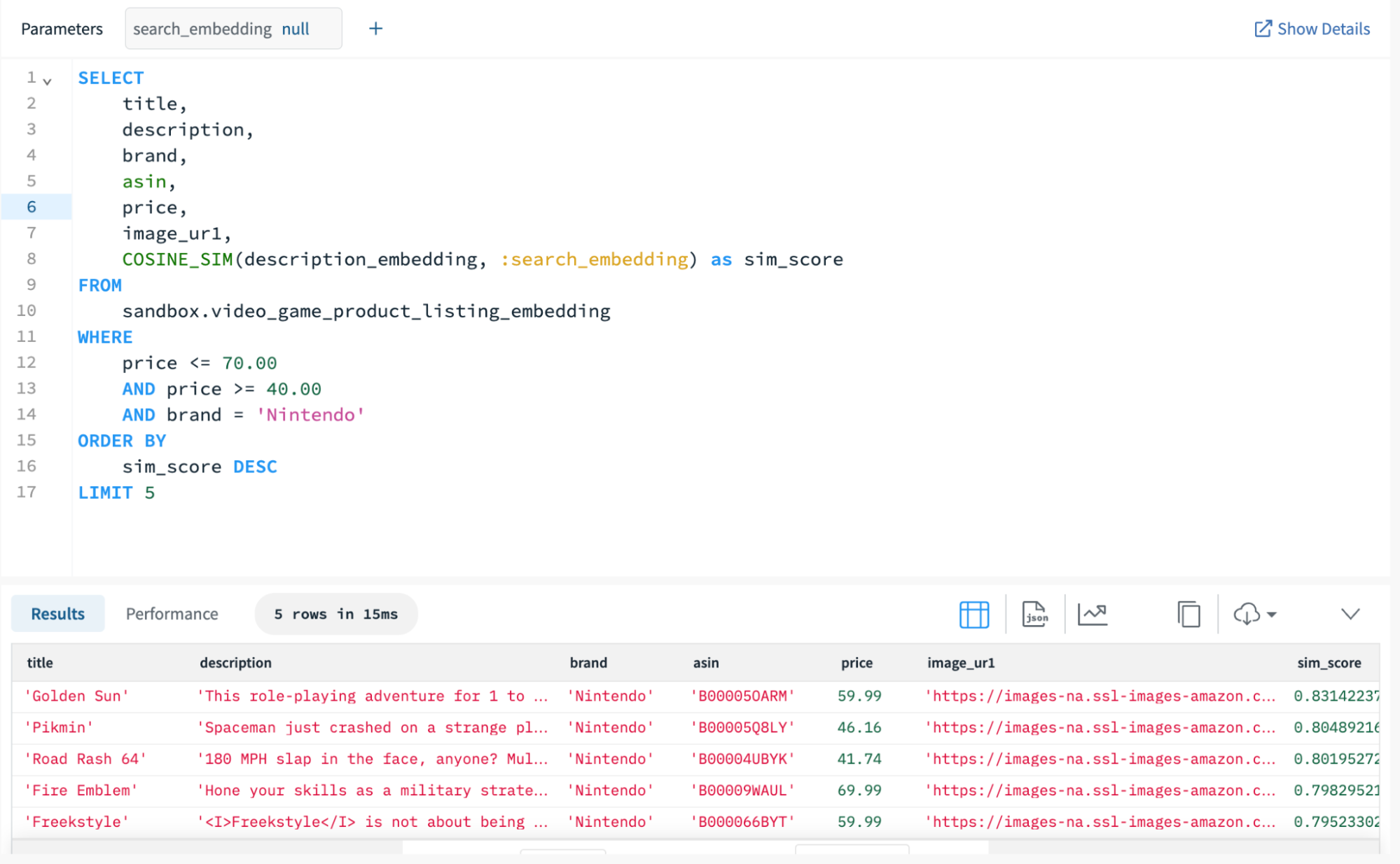
Since Rockset filters on model and worth earlier than computing the similarity scores, Rockset returns the highest 5 outcomes on over 8,500 paperwork in 15 milliseconds on a Giant Digital Occasion with 16 vCPUs and 128 GiB of allotted reminiscence. Listed here are the descriptions for the highest three outcomes primarily based on the search enter “area and journey, open-world play and multiplayer choices”:
- This role-playing journey for 1 to 4 gamers enables you to plunge deep into a brand new world of fantasy and marvel, and expertise the dawning of a brand new sequence.
- Spaceman simply crashed on a wierd planet and he wants to seek out all his spacecraft’s components. The issue? He solely has a number of days to do it!
- 180 MPH slap within the face, anybody? Multiplayer modes for as much as 4 gamers together with Deathmatch, Cop Mode and Tag.
To summarize, Rockset runs semantic search in roughly 15 milliseconds on embeddings generated by OpenAI, utilizing a mix of vector search with metadata filtering for sooner, extra related outcomes.
What does this imply for search?
We walked by an instance of the best way to use vector search to energy semantic search and there are a lot of different examples the place quick, related search might be helpful:
Personalization & Suggestion Engines: Leverage vector search in your e-commerce web sites and client functions to find out pursuits primarily based on actions like previous purchases and web page views. Vector search algorithms will help generate product suggestions and ship personalised experiences by figuring out similarities between customers.
Anomaly Detection: Incorporate vector search to establish anomalous transactions primarily based on their similarities (and variations!) to previous, professional transactions. Create embeddings primarily based on attributes equivalent to transaction quantity, location, time, and extra.
Predictive Upkeep: Deploy vector search to assist analyze components equivalent to engine temperature, oil stress, and brake put on to find out the relative well being of vans in a fleet. By evaluating readings to reference readings from wholesome vans, vector search can establish potential points equivalent to a malfunctioning engine or worn-out brakes.
Within the upcoming years, we anticipate the usage of unstructured information to skyrocket as massive language fashions change into simply accessible and the price of producing embeddings continues to say no. Rockset will assist speed up the convergence of real-time machine studying with real-time analytics by easing the adoption of vector search with a fully-managed, cloud-native service.
Search has change into simpler than ever as you now not have to construct complicated and hard-to-maintain rules-based algorithms or manually configure textual content tokenizers or analyzers. We see infinite prospects for vector search: discover Rockset to your use case by beginning a free trial as we speak.
Study extra in regards to the vector search launch by watching the tech discuss, From Spam Preventing at Fb to Vector Search at Rockset: The best way to Construct Actual-Time Machine Studying at Scale.
The Amazon Overview dataset was taken from: Justifying suggestions utilizing distantly-labeled opinions and fined-grained elements
Jianmo Ni, Jiacheng Li, Julian McAuley
Empirical Strategies in Pure Language Processing (EMNLP), 2019