
The panorama of language fashions is evolving quickly, pushed by the empirical success of scaling fashions with elevated parameters and computational budgets. On this period of huge language fashions, Combination-of-Specialists (MoE) structure emerges as a key participant, providing an answer to handle computational prices whereas scaling mannequin parameters. Nonetheless, challenges persist in making certain skilled specialization in typical MoE architectures like GShard, which activate the top-𝐾 out of 𝑁 specialists. Latest functions of MoE architectures in Transformers have showcased profitable makes an attempt at scaling language fashions to substantial sizes, accompanied by outstanding efficiency, underscoring the huge potential of MoE language fashions.
The standard MoE structure replaces Feed-Ahead Networks (FFNs) in a Transformer with MoE layers, the place every layer contains a number of specialists structurally equivalent to a regular FFN. Every token is assigned to at least one or two specialists, main to 2 main challenges: Data Hybridity and Data Redundancy. These points come up because of the restricted variety of specialists, inflicting tokens assigned to a particular skilled to cowl various information and, in flip, compromising the mannequin’s capacity to make the most of this info concurrently.
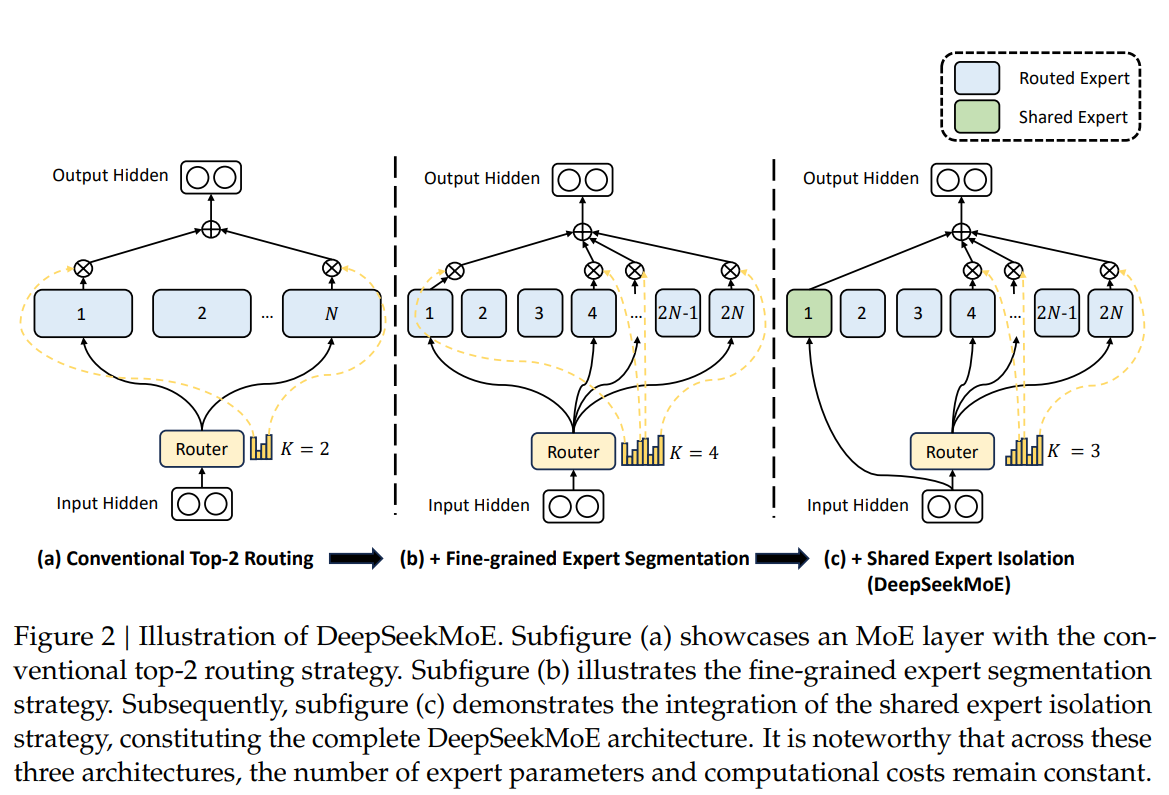
In response to those challenges, a group of researchers from DeepSeek-AI proposed DeepSeekMoE—an revolutionary MoE structure designed to realize final skilled specialization. As illustrated in Determine 2, this structure employs two principal methods: Tremendous-Grained Skilled Segmentation and Shared Skilled Isolation.
Tremendous-grained skilled Segmentation addresses the limitation of a hard and fast variety of specialists by splitting the FFN intermediate hidden dimension. This technique permits for a finer segmentation of specialists, activating extra fine-grained specialists whereas sustaining a continuing variety of parameters and computational prices. The consequence is a versatile and adaptable mixture of activated specialists, enabling exact information acquisition and better ranges of specialization. The fine-grained skilled segmentation considerably enhances the combinatorial flexibility of activated specialists, probably resulting in extra correct and focused information acquisition.
Shared Skilled Isolation enhances fine-grained segmentation by isolating particular specialists as shared specialists, all the time activated whatever the routing module. These shared specialists purpose to seize and consolidate widespread information throughout varied contexts, mitigating redundancy amongst different routed specialists. This isolation enhances parameter effectivity, making certain every routed skilled retains specialization by specializing in distinctive points. Notably, this shared skilled isolation technique attracts inspiration from Rajbhandari et al. (2022) however is approached from an algorithmic standpoint.
The paper delves into the difficulty of load imbalance that routinely realized routing methods might encounter, resulting in the dangers of routing collapse and computation bottlenecks. The authors introduce expert- and device-level stability loss to mitigate these dangers, emphasizing the significance of balanced computation throughout gadgets.
The coaching knowledge, sourced from a large-scale multilingual corpus by DeepSeek-AI, focuses totally on English and Chinese language however contains different languages. For validation experiments, a subset containing 100B tokens is sampled from the corpus to coach their fashions.
Analysis spans varied benchmarks encompassing language modeling, language understanding, reasoning, studying comprehension, code technology, and closed-book query answering. DeepSeekMoE is rigorously in contrast towards baselines, together with Hash Layer, Swap Transformer, and GShard, constantly demonstrating superiority throughout the MoE structure panorama.
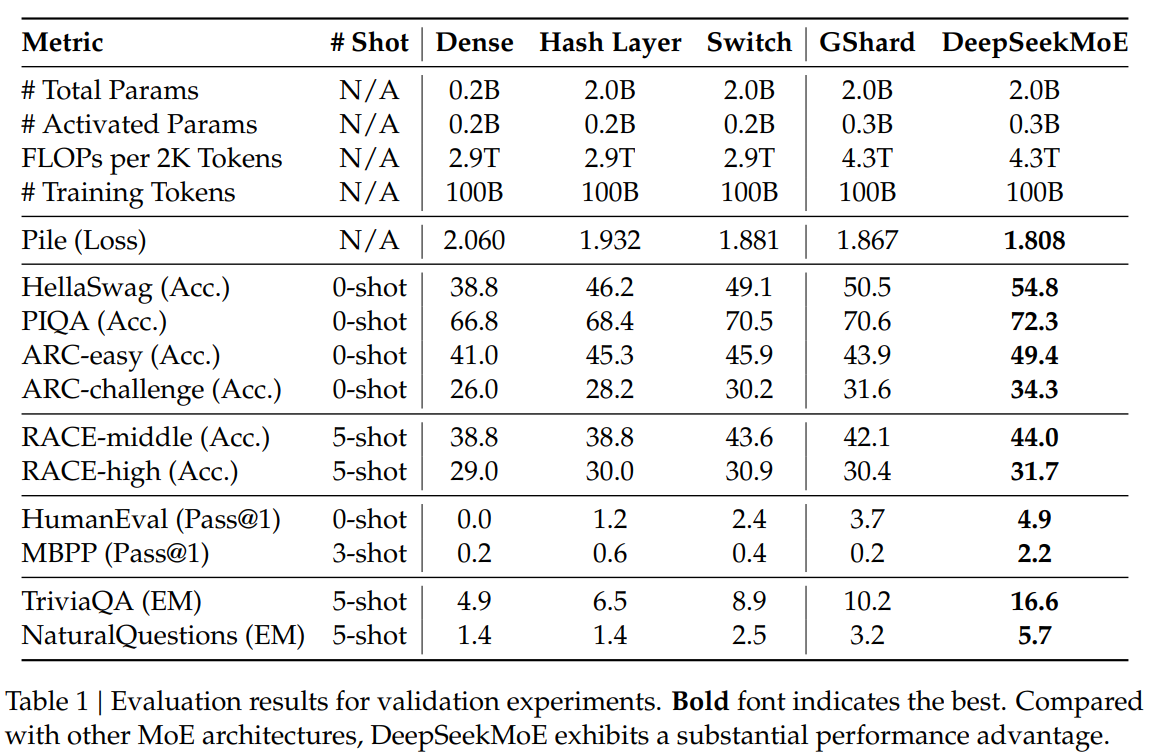
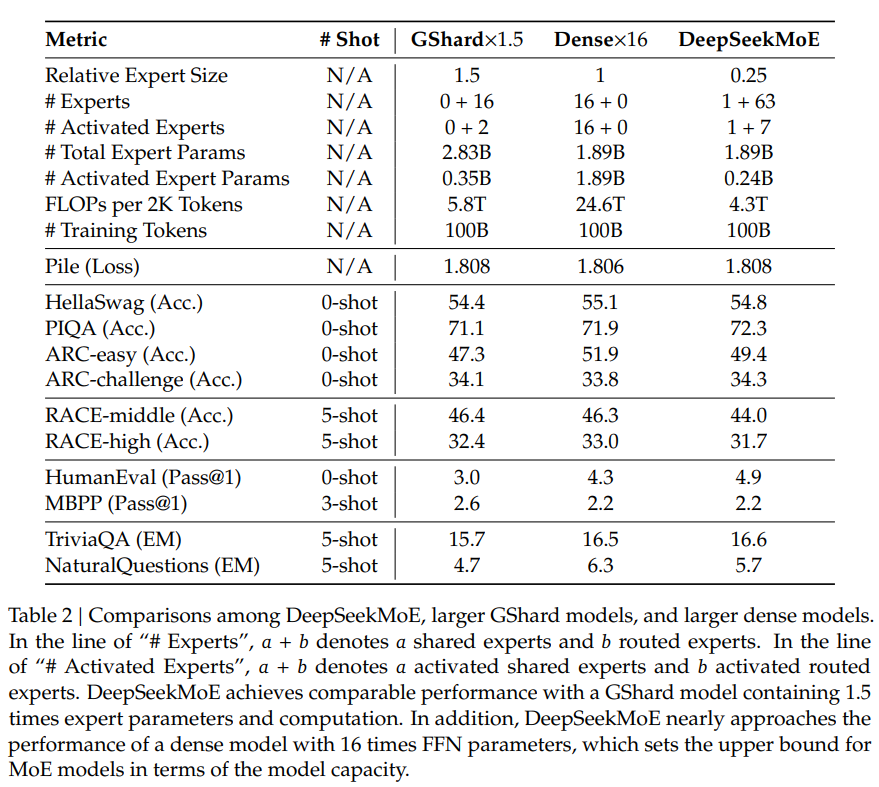
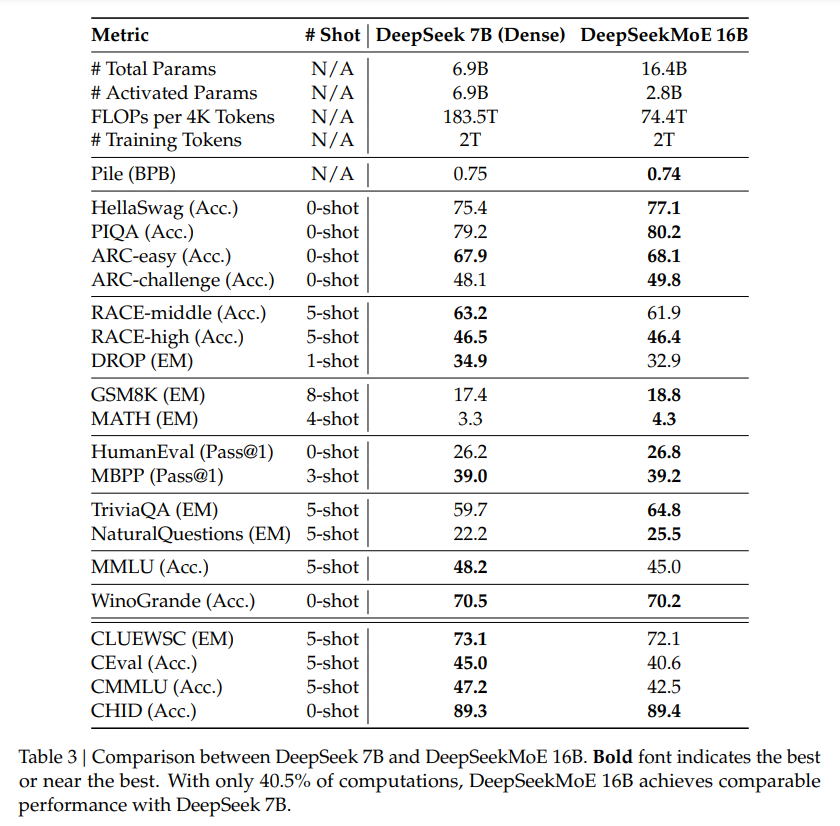
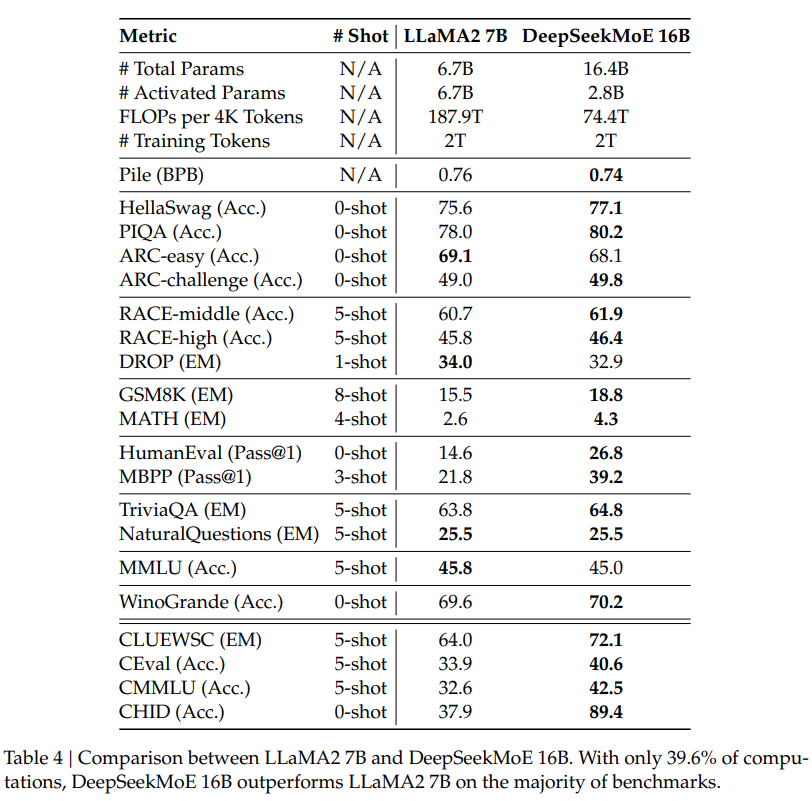
The analysis outcomes, detailed in Desk 1 and Desk 2, spotlight the strengths of DeepSeekMoE over different fashions. Noteworthy observations embody the numerous efficiency benefits of DeepSeekMoE over GShard, particularly when contemplating sparse architectures and comparable whole parameters. The paper additionally presents comparisons with bigger GShard fashions and denser fashions, showcasing the scalability and effectivity of DeepSeekMoE.
Earlier analysis on MoE fashions has typically advised restricted positive factors from fine-tuning. Nonetheless, the authors cite findings by Shen et al. (2023) indicating that MoE fashions, particularly DeepSeekMoE 16B, can profit from supervised fine-tuning. The experimental outcomes reveal the adaptability and comparable efficiency of DeepSeekMoE Chat 16B in alignment duties.
Buoyed by the success of DeepSeekMoE 16B, the authors embark on a preliminary exploration to scale up DeepSeekMoE to 145B. On this preliminary examine, DeepSeekMoE 145B, skilled on 245B tokens, demonstrates constant benefits over GShard and guarantees to match or exceed the efficiency of DeepSeek 67B (Dense). The authors plan to make the ultimate model of DeepSeekMoE 145B publicly accessible.
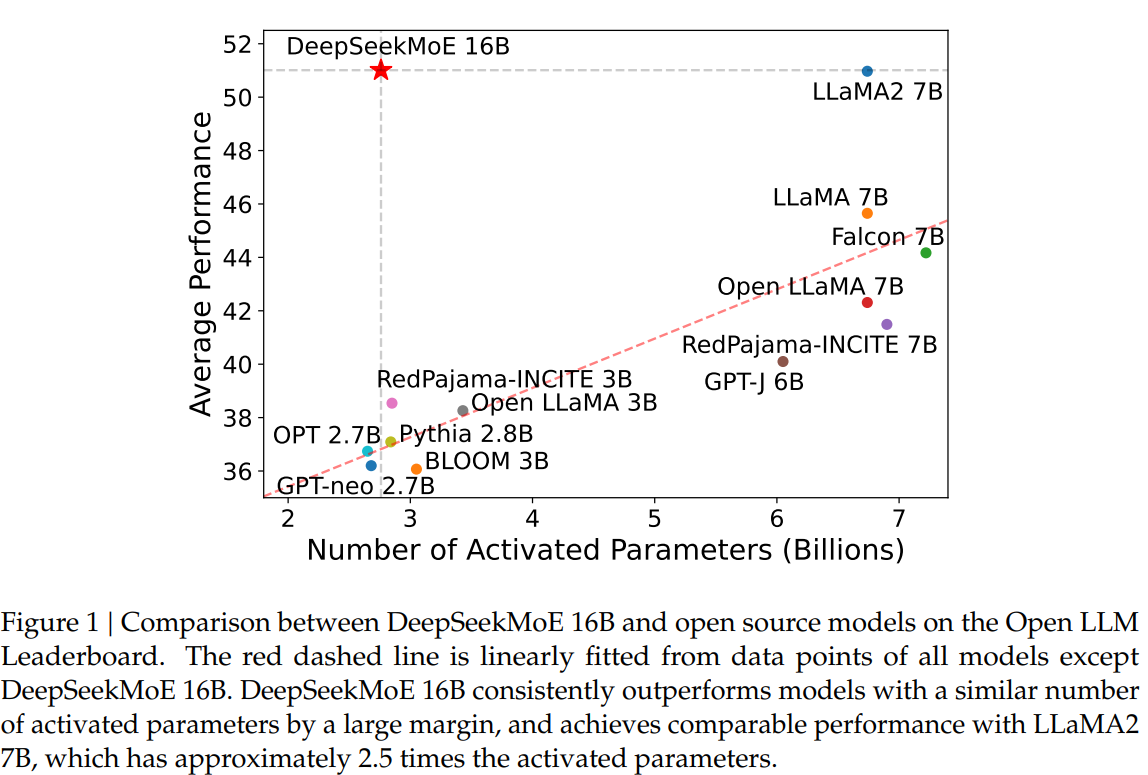
In conclusion, the paper introduces DeepSeekMoE as a groundbreaking MoE language mannequin structure, emphasizing final skilled specialization. By way of revolutionary methods, together with fine-grained skilled segmentation and shared skilled isolation, DeepSeekMoE achieves considerably greater skilled specialization and efficiency in comparison with present MoE architectures. The scalability of DeepSeekMoE is demonstrated via experiments, and the authors present a glimpse into its potential at an unprecedented scale of 145B parameters. With the discharge of the DeepSeekMoE 16B mannequin checkpoint to the general public (GitHub), the authors purpose to contribute priceless insights to each academia and trade, propelling the development of large-scale language fashions.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our Telegram Channel
Vineet Kumar is a consulting intern at MarktechPost. He’s at present pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s keen about analysis and the newest developments in Deep Studying, Pc Imaginative and prescient, and associated fields.