
Multimodal architectures are revolutionizing the best way methods course of and interpret complicated information. These superior architectures facilitate simultaneous evaluation of various information sorts corresponding to textual content and pictures, broadening AI’s capabilities to reflect human cognitive capabilities extra precisely. The seamless integration of those modalities is essential for growing extra intuitive and responsive AI methods that may carry out varied duties extra successfully.
A persistent problem within the subject is the environment friendly and coherent fusion of textual and visible data inside AI fashions. Regardless of quite a few developments, many methods face difficulties aligning and integrating these information sorts, leading to suboptimal efficiency, significantly in duties that require complicated information interpretation and real-time decision-making. This hole underscores the vital want for revolutionary architectural options to bridge these modalities extra successfully.
Multimodal AI methods have included massive language fashions (LLMs) with varied adapters or encoders particularly designed for visible information processing. These methods are geared in the direction of enhancing the AI’s functionality to course of and perceive photographs along side textual inputs. Nonetheless, they typically don’t obtain the specified stage of integration, resulting in inconsistencies and inefficiencies in how the fashions deal with multimodal information.
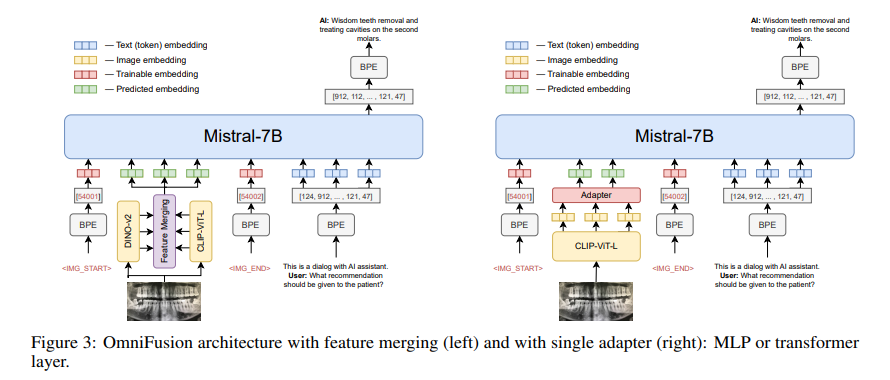
Researchers from AIRI, Sber AI, and Skoltech have proposed an OmniFusion mannequin counting on a pretrained LLM and adapters for visible modality. This revolutionary multimodal structure synergizes the sturdy capabilities of pre-trained LLMs with cutting-edge adapters designed to optimize visible information integration. OmniFusion makes use of an array of superior adapters and visible encoders, together with CLIP ViT and SigLIP, aiming to refine the interplay between textual content and pictures and obtain a extra built-in and efficient processing system.
OmniFusion introduces a flexible strategy to picture encoding by using each entire and tiled picture encoding strategies. This adaptability permits for an in-depth visible content material evaluation, facilitating a extra nuanced relationship between textual and visible data. The structure of OmniFusion is designed to experiment with varied fusion methods and architectural configurations to enhance the coherence and efficacy of multimodal information processing.
OmniFusion’s efficiency metrics are significantly spectacular in visible query answering (VQA). The mannequin has been rigorously examined throughout eight visual-language benchmarks, persistently outperforming main open-source options. Within the VQAv2 and TextVQA benchmarks, OmniFusion demonstrated superior efficiency, with scores surpassing current fashions. Its success can be evident in domain-specific functions, the place it supplies correct and contextually related solutions in fields corresponding to medication and tradition.
Analysis Snapshot

In conclusion, OmniFusion addresses the numerous problem of integrating textual and visible information inside AI methods, an important step for enhancing efficiency in complicated duties like visible query answering. By harnessing a novel structure that merges pre-trained LLMs with specialised adapters and superior visible encoders, OmniFusion successfully bridges the hole between totally different information modalities. This revolutionary strategy surpasses current fashions in rigorous benchmarks and demonstrates distinctive adaptability and effectiveness throughout varied domains. The success of OmniFusion marks a pivotal development in multimodal AI, setting a brand new benchmark for future developments within the subject.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to affix our 40k+ ML SubReddit
Wish to get in entrance of 1.5 Million AI Viewers? Work with us right here
Hiya, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m enthusiastic about expertise and need to create new merchandise that make a distinction.