

Picture by Creator
Over the current yr and a half, the panorama of pure language processing (NLP) has seen a exceptional evolution, principally because of the rise of Massive Language Fashions (LLMs) like OpenAI’s GPT household.
These highly effective fashions have revolutionized our method to dealing with pure language duties, providing unprecedented capabilities in translation, sentiment evaluation, and automatic textual content technology. Their capability to know and generate human-like textual content has opened up potentialities as soon as thought unattainable.
Nonetheless, regardless of their spectacular capabilities, the journey to coach these fashions is filled with challenges, reminiscent of the numerous time and monetary investments required.
This brings us to the crucial function of fine-tuning LLMs.
By refining these pre-trained fashions to raised swimsuit particular purposes or domains, we are able to considerably improve their efficiency on specific duties. This step not solely elevates their high quality but additionally extends their utility throughout a wide selection of sectors.
This information goals to interrupt down this course of into 7 easy steps to get any LLM fine-tuned for a particular job.
LLMs are a specialised class of ML algorithms designed to foretell the subsequent phrase in a sequence primarily based on the context offered by the previous phrases. These fashions are constructed upon the Transformers structure, a breakthrough in machine studying methods and first defined in Google’s All you want is consideration article.
Fashions like GPT (Generative Pre-trained Transformer) are examples of pre-trained language fashions which were uncovered to giant volumes of textual information. This intensive coaching permits them to seize the underlying guidelines of language utilization, together with how phrases are mixed to kind coherent sentences.

Picture by Creator
A key power of those fashions lies of their capability to not solely perceive pure language but additionally to provide textual content that intently mimics human writing primarily based on the inputs they’re given.
So what’s the perfect of this?
These fashions are already open to the lots utilizing APIs.
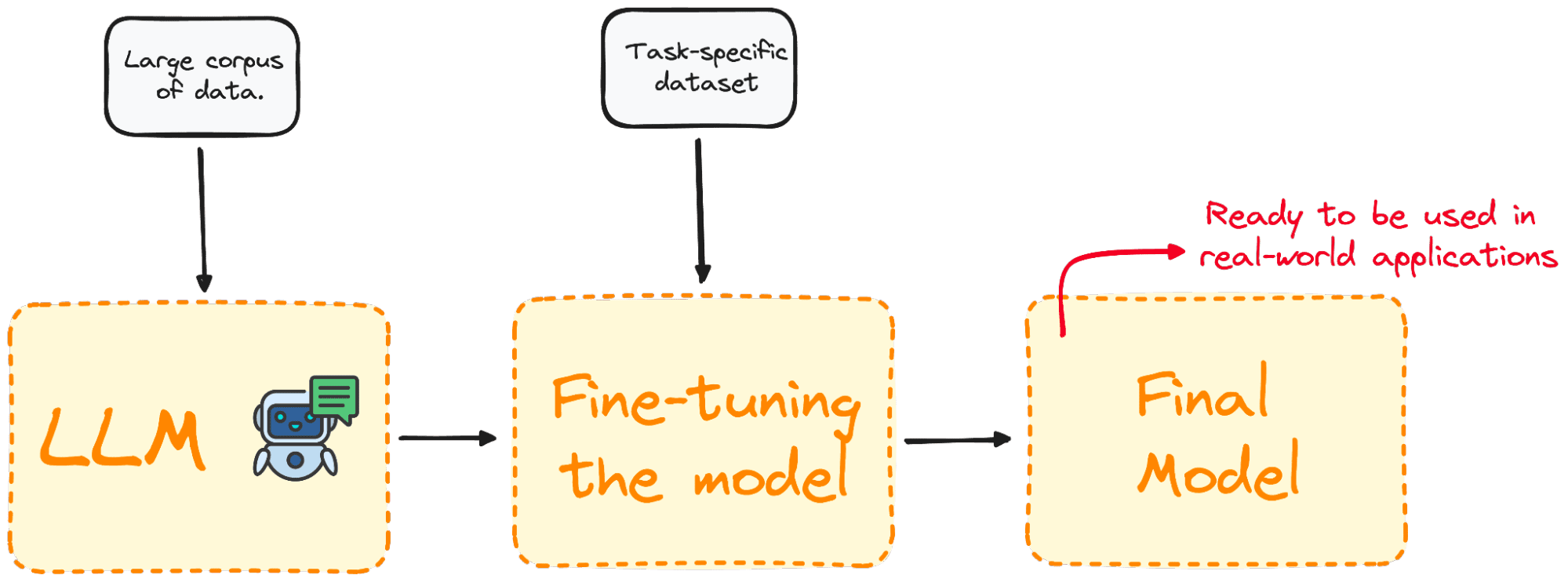
What’s High-quality-tuning, and Why is it Necessary?
High-quality-tuning is the method of selecting a pre-trained mannequin and enhancing it with additional coaching on a domain-specific dataset.
Most LLM fashions have excellent pure language abilities and generic data efficiency however fail in particular task-oriented issues. The fine-tuning course of affords an method to enhance mannequin efficiency for particular issues whereas decreasing computation bills with out the need of constructing them from the bottom up.
Picture by Creator
To place it merely, High-quality-tuning tailors the mannequin to have a greater efficiency for particular duties, making it simpler and versatile in real-world purposes. This course of is important for enhancing an present mannequin for a specific job or area.
Let’s exemplify this idea by fine-tuning an actual mannequin in solely 7 steps.
Step 1: Having our concrete goal clear
Think about we wish to infer the sentiment of any textual content and determine to attempt GPT-2 for such a job.
I’m fairly certain there’s no shock that we’ll quickly sufficient detect it’s fairly dangerous at doing so. Then, one pure query that involves thoughts is:
Can we do one thing to enhance its efficiency?
And naturally, the reply is that we are able to!
Profiting from fine-tuning by coaching our pre-trained GPT-2 mannequin from the Hugging Face Hub with a dataset containing tweets and their corresponding sentiments so the efficiency improves.
So our final purpose is to have a mannequin that’s good at inferring the sentiment out of textual content.
Step 2: Select a pre-trained mannequin and a dataset
The second step is to choose what mannequin to take as a base mannequin. In our case, we already picked the mannequin: GPT-2. So we’re going to carry out some easy fine-tuning to it.
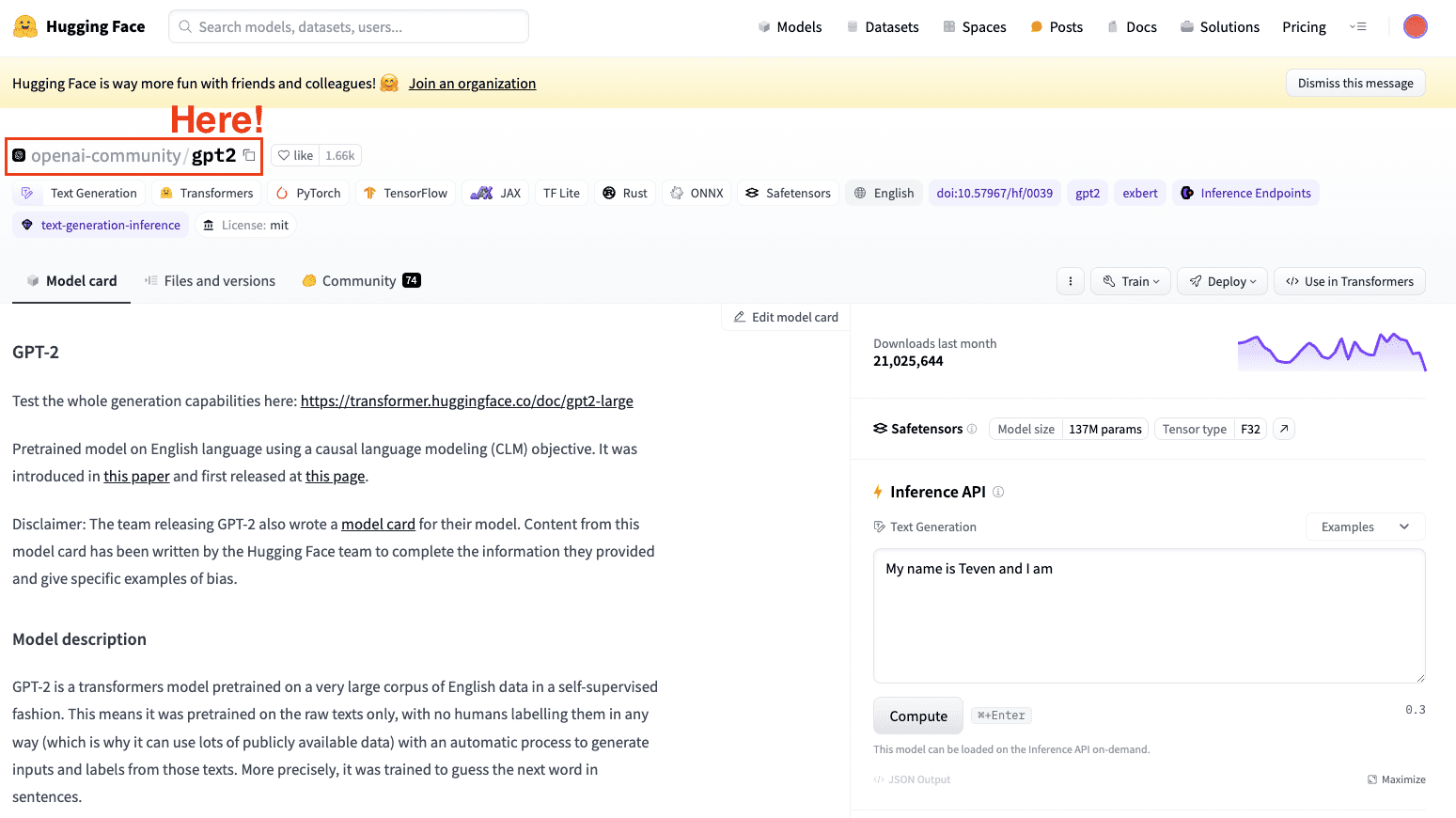
Screenshot of Hugging Face Datasets Hub. Deciding on OpenAI’s GPT2 mannequin.
All the time take note to pick out a mannequin that matches your job.
Step 3: Load the information to make use of
Now that now we have each our mannequin and our fundamental job, we’d like some information to work with.
However no worries, Hugging Face has all the pieces organized!
That is the place their dataset library kicks in.
On this instance, we’ll reap the benefits of the Hugging Face dataset library to import a dataset with tweets labeled with their corresponding sentiment (Constructive, Impartial or Adverse).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
The info seems like follows:

The info set for use.
Step 4: Tokenizer
Now now we have each our mannequin and the dataset to fine-tune it. So the next pure step is to load a tokenizer. As LLMs work with tokens (and never with phrases!!), we require a tokenizer to ship the information to our mannequin.
We are able to simply carry out this by benefiting from the map technique to tokenize the entire dataset.
from transformers import GPT2Tokenizer
# Loading the dataset to coach our mannequin
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
BONUS: To enhance our processing efficiency, two smaller subsets are generated:
- The coaching set: To fine-tune our mannequin.
- The testing set: To judge it.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).choose(vary(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).choose(vary(1000))
Step 5: Initialize our base mannequin
As soon as now we have the dataset for use, we load our mannequin and specify the variety of anticipated labels. From the Tweet’s sentiment dataset, you’ll be able to know there are three attainable labels:
- 0 or Adverse
- 1 or Impartial
- 2 or Constructive
from transformers import GPT2ForSequenceClassification
mannequin = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)
Step 6: Consider technique
The Transformers library supplies a category referred to as “Coach” that optimizes each the coaching and the analysis of our mannequin. Due to this fact, earlier than the precise coaching is begun, we have to outline a perform to judge the fine-tuned mannequin.
import consider
metric = consider.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
Step 7: High-quality-tune utilizing the Coach Technique
The ultimate step is fine-tuning the mannequin. To take action, we arrange the coaching arguments along with the analysis technique and execute the Coach object.
To execute the Coach object we simply use the prepare() command.
from transformers import TrainingArguments, Coach
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Cut back batch dimension right here
per_device_eval_batch_size=1, # Optionally, scale back for analysis as effectively
gradient_accumulation_steps=4
)
coach = Coach(
mannequin=mannequin,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
coach.prepare()
As soon as our mannequin has been fine-tuned, we use the check set to judge its efficiency. The coach object already incorporates an optimized consider() technique.
import consider
coach.consider()
This can be a fundamental course of to carry out a fine-tuning of any LLM.
Additionally, do not forget that the method of fine-tuning a LLM is very computationally demanding, so your native laptop might not have sufficient energy to carry out it.
Right now, fine-tuning pre-trained giant language fashions like GPT for particular duties is essential to enhancing LLMs efficiency in particular domains. It permits us to reap the benefits of their pure language energy whereas enhancing their effectivity and the potential for personalization, making the method accessible and cost-effective.
Following these easy 7 steps —from choosing the correct mannequin and dataset to coaching and evaluating the fine-tuned mannequin— we are able to obtain a superior mannequin efficiency in particular domains.
For many who wish to examine the complete code, it’s accessible in my large language fashions GitHub repo.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is at the moment working within the information science subject utilized to human mobility. He’s a part-time content material creator centered on information science and expertise. Josep writes on all issues AI, protecting the applying of the continued explosion within the subject.